1、什么是LocalCache?
本地缓存是一种将数据存储在应用程序内存中的机制,用于提高数据访问的性能和响应速度。它通过在内存中维护一个键值对的存储结构,允许应用程序快速检索和访问数据,而无需每次都从慢速的数据源(如数据库或网络)获取数据。
2、LocalCache优缺点
1)优点
•快速访问:LocalCache将数据存储在内存中,因此可以快速访问缓存数据,提高应用程序的性能。
•减轻后端负载:通过将经常访问的数据存储在本地缓存中,可以减少对后端数据源的访问次数,降低后端负载,提高系统的整体性能。
•灵活性:LocalCache提供了一些配置选项,如最大容量、过期时间等,可以根据需求进行调整。这使得开发人员能够灵活地控制缓存的行为,以适应不同的业务场景。
2)缺点
•有限的容量:由于LocalCache是基于内存的,因此容量是有限的。如果缓存数据量过大,可能会导致内存消耗过高,影响系统的稳定性。
•单点故障:LocalCache存储在单个应用程序中,如果应用程序崩溃或重启,缓存数据将丢失。这可能会导致缓存冷启动和性能下降。
3、LocalCache应用场景
LocalCache适用于许多不同的使用场景,特别是以下几种情况:
1.**频繁访问的数据:**如果应用程序中有一些频繁被访问的数据,将这些数据存储在LocalCache中可以大大提高访问速度。由于数据存储在内存中,相比于从磁盘或网络中读取数据,从本地缓存中获取数据的速度更快。
2.**减轻后端负载:**通过将经常访问的数据存储在本地缓存中,可以减少对后端数据源(如数据库或API)的访问次数。这样可以降低后端的负载,提高系统的整体性能。
3.**降低网络延迟:**在分布式系统或微服务架构中,不同的服务可能位于不同的节点上,通过网络进行通信。使用本地缓存可以减少对远程服务的调用次数,从而减少网络延迟,提高系统的响应速度。
4.灵活性和可配置性:LocalCache提供了一些配置选项,如最大容量、过期时间等,可以根据需求进行调整。这使得开发人员能够灵活地控制缓存的行为,以适应不同的业务场景。
4、LocalCache实际使用场景
1.**数据库中间件:**数据库中间件是位于应用程序和后端数据库之间的软件层,常见的数据库中间件包括MySQL Proxy、Cobar、MyCat等。这些中间件可以使用LocalCache来缓存查询结果,以减轻后端数据库的负载并提高查询性能。当应用程序发出相同的查询请求时,中间件可以先检查LocalCache中是否有相应的缓存结果,如果有则直接返回缓存结果,否则再向后端数据库发起查询请求。
2.**消息队列:**消息队列是一种用于异步通信的中间件,常见的消息队列系统包括Apache Kafka、RabbitMQ等。在消息队列系统中,LocalCache可以用来缓存消息,以提高消息的处理速度和响应能力。当消费者需要处理消息时,它可以先在LocalCache中查找是否有相应的消息缓存,如果有则直接消费缓存消息,否则再从消息队列中获取消息。
3.**前端应用:**前端应用包括各种Web应用、移动应用和桌面应用,常见的前端框架如React、Angular、Vue.js等。在前端应用中,LocalCache可以用于缓存静态资源(如JavaScript、CSS、图像等)或动态数据,以提高应用的加载速度和用户体验。例如,前端应用可以先检查LocalCache中是否有相应的资源缓存,如果有则直接使用缓存资源,否则再从服务器获取资源并将其缓存到LocalCache中。
4.**服务端应用:**服务端应用包括各种后端服务、微服务和RESTful API等,常见的服务端框架如Spring、Node.js、Ruby on Rails等。LocalCache可以在服务端应用中使用,用于缓存计算结果、数据库查询结果等,以提高性能和减少对外部资源的依赖。例如,当服务端应用需要进行频繁的计算或查询时,它可以先检查LocalCache中是否有相应的缓存结果,如果有则直接返回缓存结果,否则再进行计算或查询,并将结果缓存到LocalCache中。
5.**开源框架:**许多开源框架提供了自己的LocalCache实现,以方便开发人员在应用中使用。这些框架通常提供了丰富的配置选项和高性能的缓存实现,可以根据应用需求进行定制。例如,Guava、Caffeine和Ehcache等是常见的Java开源框架,它们提供了LocalCache的实现,可以用于缓存计算结果、数据库查询结果等。
5、LocalCache在Guava实践
Guava cache 继承了 ConcurrentHashMap 的思路,使用多个 segments 方式的细粒度锁,在保证线程安全的同时,支持高并发场景需求。
1、CacheBuilder 缓存构建器。构建缓存的入口,指定缓存配置参数并初始化本地缓存。采用 Builder 设计模式提供了设置好各种参数的缓存对象。
CacheBuilder<Object,Object> cacheBuilder =CacheBuilder.newBuilder();
2、LocalCache 数据结构。缓存核心类 LocalCache 数据结构与 ConcurrentHashMap 很相似,由多个 segment 组成,且各 segment 相对独立,互不影响,所以能支持并行操作,每个 segment 由一个 table 和若干队列组成。缓存数据存储在 table 中,其类型为AtomicReferenceArray,具体结构图及代码解释如下。
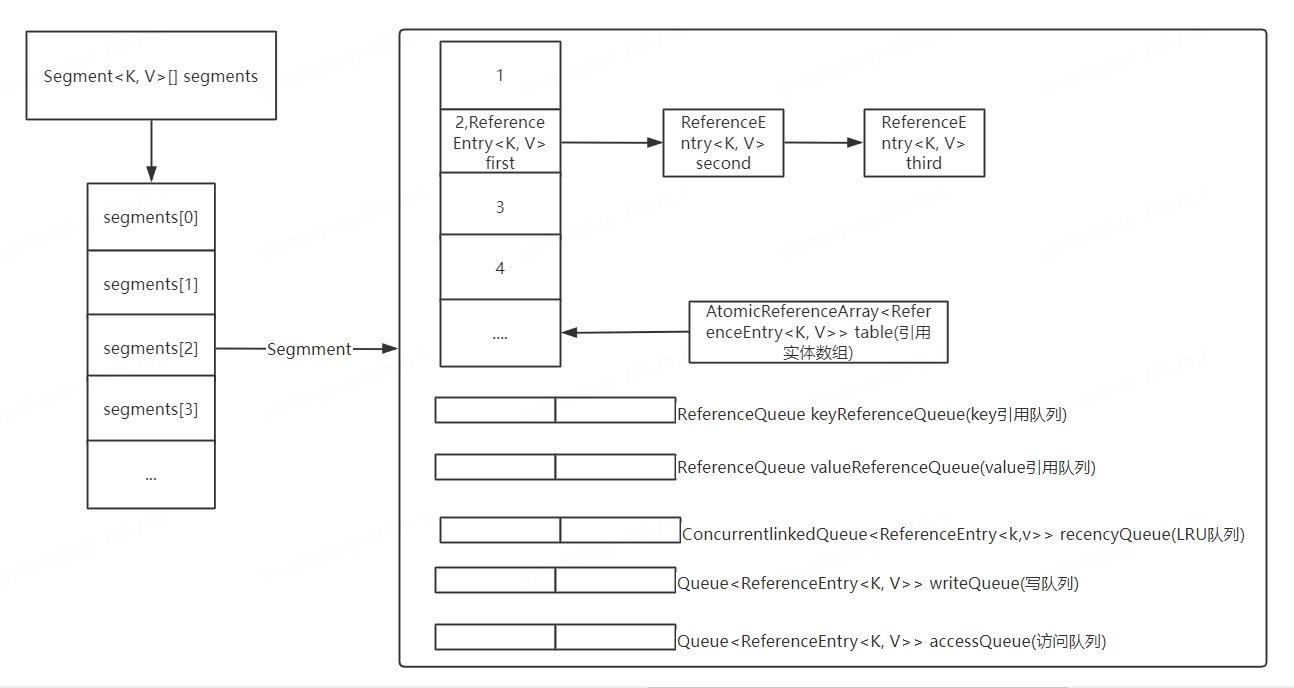
#Guava中LocalCache声明segments变量
final LocalCache.Segment<K, V>[] segments;
#Guava中初始化segments
this.segments = this.newSegmentArray(segmentCount);
final LocalCache.Segment<K, V>[] newSegmentArray(int ssize) {
return new LocalCache.Segment[ssize];
}
#获取Segment
Segment<K, V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
#Guava中Segment声明table变量用于存储数据
volatile AtomicReferenceArray<LocalCache.ReferenceEntry<K, V>> table;
V put(K key, int hash, V value, boolean onlyIfAbsent) {
#保证线程安全
lock();
#获取数据
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
}
}
}
3、在Guava中,CacheBuilder提供了一系列方法,用于指定缓存的大小、过期策略、并发级别等属性。
1.配置缓存属性:通过一系列方法来配置缓存的属性,例如:
•maximumSize(long size):指定缓存的最大容量,当缓存达到最大容量时,根据缓存策略淘汰部分缓存项。
•expireAfterWrite(Duration duration):指定缓存项的写入后过期时间,过期后的缓存项将被自动移除。
•expireAfterAccess(Duration duration):指定缓存项的最后一次访问后过期时间,过期后的缓存项将被自动移除。
•concurrencyLevel(int level):指定并发级别,即同时可以进行缓存操作的线程数。
Cache<Object,Object> cache = cacheBuilder.maximumSize(1000)
.expireAfterWrite(Duration.ofMinutes(10))
.concurrencyLevel(4)
.build();
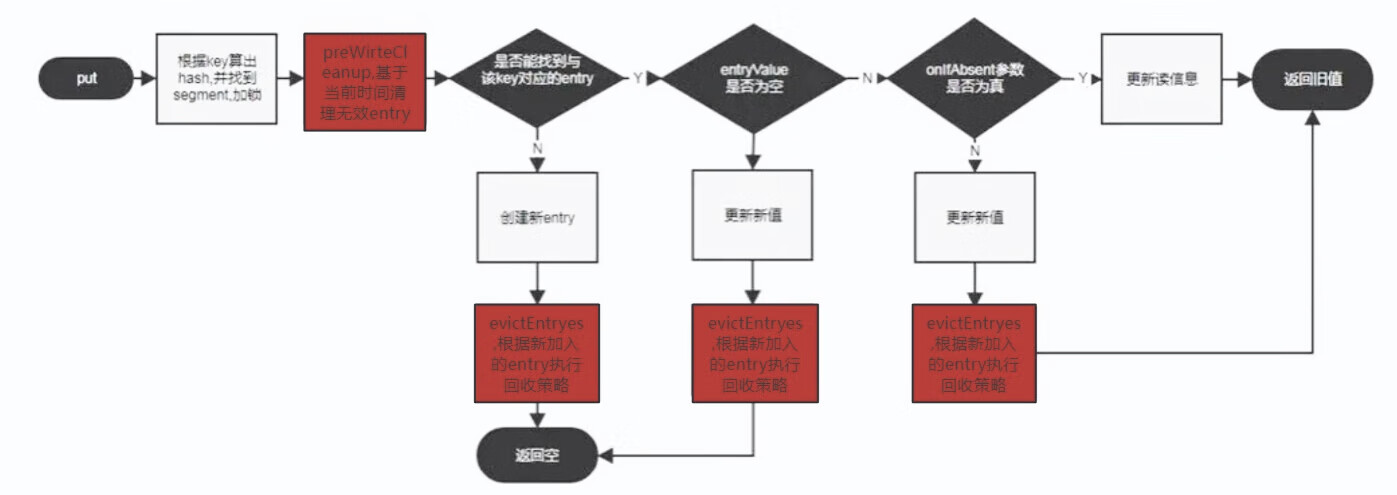
2. 使用缓存:通过Cache对象的方法来进行缓存的读取、写入和移除操作。例如:
•get(Object key):根据键获取缓存项的值。
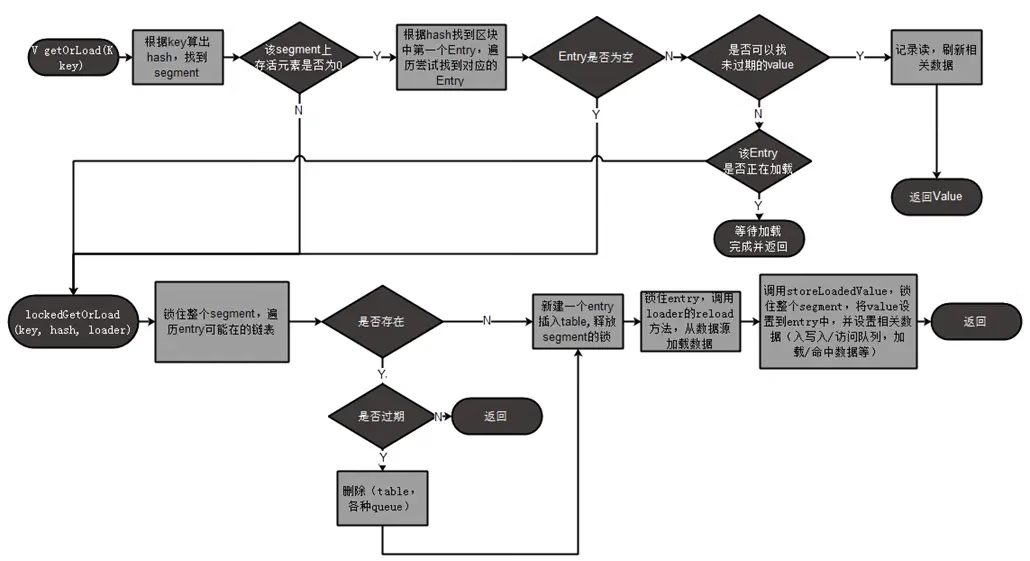
•put(Object key, Object value):向缓存中添加或更新一个缓存项。
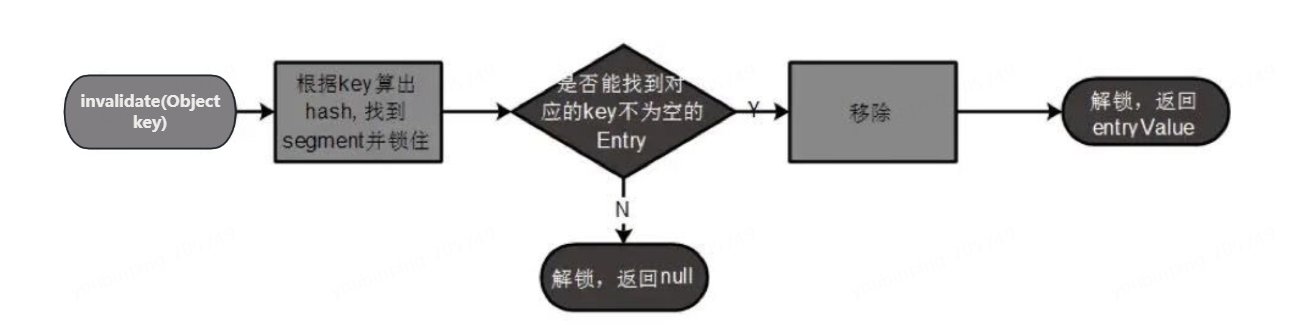
•invalidate(Object key):移除指定键的缓存项。
3. 其他功能:Guava的LocalCache还提供了其他功能,如统计信息、监听器、加载器等,用于监控缓存的状态、处理缓存未命中的情况等。
CacheStats stats = cache.stats();
cache.asMap().forEach((key, value)->System.out.println(key +": "+ value));
cache.cleanUp();
总结来说,Guava的LocalCache使用CacheBuilder构建和配置缓存,通过Cache对象进行缓存的读取、写入和移除操作。开发人员可以根据自己的需求使用相应的方法和功能来定制和管理缓存。
6、后记
设计一个可用的 Cache 绝对不是一个普通的 Map 这么简单,这里小结一下关于 Guava Cache 的知识。
回归LocalCache 的源头,我是希望可以了解 设计一个缓存要考虑什么?,局部性原理 是一个系统性能提升的最直接的方式(编程上,硬件上当然也可以),缓存的出现就是根据 局部性原理 所设计的。
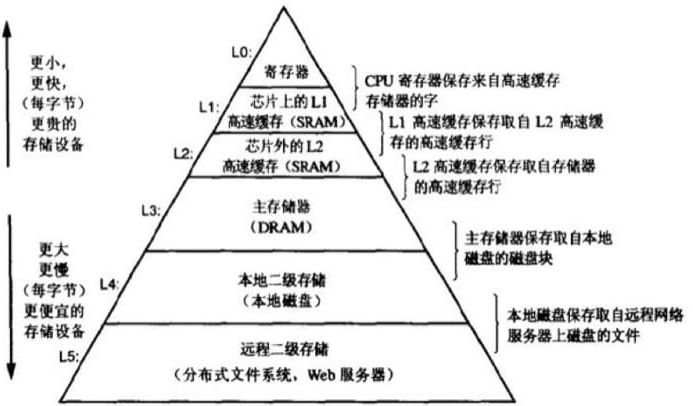
缓存作为存储金字塔的一部分,一定需要考虑以下几个问题:
1.何时加载
在设计何时加载的问题上,Guava Cache 提供了一个 Loader 接口,让用户可以自定义加载过程,在由 Cache 在找不到对象的时候主动调用 Loader 去加载,还通过一个巧妙的方法,既保证了 Loader 的只运行一次,还能保证锁粒度极小,保证并发加载时,安全且高性能。
2. 何时失效
失效处理上,Guava Cache 提供了基于容量、有限时间(读有限时、写有限时)等失效策略,在官方文档上也写明,在基于限时的情况下,并不是使用一个线程去单独清理过期 K-V,而是把这个清理工作,均摊到每次访问中。假如需要定时清理,也可以调用 CleanUp 方法,定时调用就可以了。
3. 如何保持热点数据有效性
在 Cache 容量有限时, LRU 算法是一个通用的解决方案,在源码中,Guava Cache 并不是严格地保证全局 LRU 的,只是针对一个 Segment 实现 LRU 算法。这个前提是 Segment 对用户来说是随机的,所以全局的 LRU 算法和单个 Segment 的算法是基本一致的。
4. 写回策略
在 Guava Cache 里,并没有实现任何的写回策略。原因在于,Guava Cache 是一个本地缓存,直接修改对象的数据,Cache 的数据就已经是最新的了,所以在数据能够写入 DB 后,数据就已经完成一致了。
参考文献:Google Guava Cache 全解析
作者:京东科技 游斌平
来源:京东云开发者社区 转载请注明来源
npm 被滥用 —— 有人上传了 700 多个武林外传切片视频 “Linux 中国” 开源社区宣布停止运营 微软组建新团队,帮助用 Rust 重写核心 Windows 库 JetBrain 捆绑 AI 助手引起用户不满 德国铁路公司招聘熟悉 MS-DOS 和 Windows 3.11 的 IT 管理员 VS Code 1.86 会导致远程开发功能无法使用 FastGateway:一个可以用于代替 Nginx 的网关 Visual Studio Code 1.86 发布 工信部等七部门联合发文:发展下一代操作系统、推广开源技术、构建开源生态体系 Windows Terminal Preview 1.20 发布