第一章 变量、常用循环体、代码结构、代码练习
第二章 列表、元组等数据结构、字符串驻留机制及字符串格式化操作
第三章 函数、面向对象、文件操作、深浅拷贝、模块、异常及捕获
第四章 项目打包、类和对象高级、序列、迭代器、生成器、装饰器
第五章 正则表达式、json、logging日志配置、数据库操作、枚举、闭包、匿名函数和高阶函数、time、datetime
第六章 Socket编程、多线程(创建方式、线程通信、线程锁、线程池)
正则表达式
多用于校验数据格式(字符串相关的),重在处理规则
常用的正则表达式

预定义字符
import re
# 找普通字符
res = re.findall('python', 'i like python, hello python')
print(res) # ['python', 'python']
# 预定义字符
# \d \s \w \D \S \W
# \d 匹配数字[0-9]
res = re.findall(r'\d', '1111fsdfsd12234321sss')
print(res) # ['1', '1', '1', '1', '1', '2', '2', '3', '4', '3', '2', '1']
# \D 匹配所有非数字 对\d的取反
res = re.findall(r'\D', '1111fsdfsd12234321sss')
print(res) # ['f', 's', 'd', 'f', 's', 'd', 's', 's', 's']
# \w 匹配所有字符(不包括特殊字符),包含下划线 a-zA-Z0-9_
res = re.findall(r'\w', '1111fsdf^#^3_1sss')
print(res) # ['1', '1', '1', '1', 'f', 's', 'd', 'f', '3', '_', '1', 's', 's', 's']
# \W 匹配所有特殊字符 \w的取反
res = re.findall(r'\W', '1111fsdf^#^3_1sss')
print(res) # ['^', '#', '^']
# \s 空白符 制表符 换行符
res = re.findall(r'\s', '1111fs sfsdfs\tfdsfsd\n')
print(res) # [' ', ' ', ' ', '\t', '\n']
# \S 除空白符 制表符 换行符外的所有 对\s的取反
res = re.findall(r'\S', '1111fs **^^## sfsdfs\tfdsfsd\n')
print(res) # ['1', '1', '1', '1', 'f', 's', '*', '*', '^', '^', '#', '#', 's', 'f', 's', 'd', 'f', 's', 'f', 'd', 's', 'f', 's', 'd']
元字符
# [] 匹配一个字符,括号内的字符是或者的关系
res = re.findall(r'[123]', 'fjsd11132322888');
print(res) # ['1', '1', '1', '3', '2', '3', '2', '2']
# [] + 预定义字符
res = re.findall(r'[\d\s]', 'fjsd11132 32 \t2888');
print(res) # ['1', '1', '1', '3', '2', ' ', ' ', '3', '2', ' ', '\t', '2', '8', '8', '8']
# ^ 表示取反操作
res = re.findall(r'[^\d\s]', 'fjs132 32 \t2888');
print(res) # ['f', 'j', 's']
# - 表示区间
res = re.findall(r'[1-3]', 'fjsd111323');
print(res) # ['1', '1', '1', '3', '2', '3']
res = re.findall(r'[1-3a-zA-C]', 'fjsd11B132A3');
print(res) # ['f', 'j', 's', 'd', '1', '1', 'B', '1', '3', '2', 'A', '3']
重复匹配
# {n} 表示前面的字符重复n次
res = re.findall(r'\d{3}', '112243fsssml;gmdf')
print(res) # ['112', '243']
# {n,m} 表示前面的字符 最少出现n次,最多m次
res = re.findall(r'\d{2,5}', '11a224b3fsssml;gmdf')
print(res) # ['11', '224']
# {n,} 表示前面的字符 最少出现n次,最多无限次
res = re.findall(r'\d{2,}', '11224b3fsssml;gmdf')
print(res) # ['11224']
# ? 表示前面的字符出现 0次或1次 ==》 {0,1}
res = re.findall(r'\w?', '11224b3fsssml;gmdf')
print(res) # ['1', '1', '2', '2', '4', 'b', '3', 'f', 's', 's', 's', 'm', 'l', '', 'g', 'm', 'd', 'f', '']
# + 表示字符出现至少一次 ==> {1,}
res = re.findall(r'\d+', '11224b3fsssml;gmdf')
print(res) # ['11224', '3']
# * 表示字符出现 0次或任意次 ==> {0,}
res = re.findall(r'\d*', '11224b3fsssml;gmdf')
print(res) # ['11224', '', '3', '', '', '', '', '', '', '', '', '', '', '', '']
转义符
# 转义符 \d * +
res = re.findall(r'\*', '112*24b3f*f')
print(res) # ['*', '*']
贪婪和非贪婪
# 贪婪和非贪婪
res = re.findall(r'd\w+d', 'dxxxxxdxxxdxxxxd')
print(res) # ['dxxxxxdxxxdxxxxd']
res = re.findall(r'd\w+?d', 'dxxxxxdxxxdxxxxd')
print(res) # ['dxxxxxd', 'dxxxxd']
htmlstr = '''
<td>python</td><td>$211</td><td>[email protected]</td>
'''
# . 匹配所有非 换行的字符
res = re.findall(r'<td>.+</td>', htmlstr)
print(res) # ['<td>python</td><td>$211</td><td>[email protected]</td>']
# . 匹配所有非 换行的字符
# ? 使用非贪婪模式(一获取到 立即返回)
res = re.findall(r'<td>.+?</td>', htmlstr)
print(res) # ['<td>python</td>', '<td>$211</td>', '<td>[email protected]</td>']
# (): 只取()中的元素
res = re.findall(r'<td>(.+?)</td>', htmlstr)
print(res) # ['python', '$211', '[email protected]']
反向引用
wordstr = '''
'hello' "python" 'love" "haha'
'''
res = re.findall(r"['\"]\w+['\"]", wordstr)
print(res) # ["'hello'", '"python"', '\'love"', '"haha\'']
# 引用前面的匹配结果
res = re.findall(r"('|\")(\w+)(\1)", wordstr)
# 注意返回的是 'hello'的元组 如("'", 'hello', "'")
print(res) # [("'", 'hello', "'"), ('"', 'python', '"')]
# 对数据处理
lst = [i[1] for i in res]
print(lst) # ['hello', 'python']
实现校验
校验密码:
返回:有连续的字符密码
# 连续的数字
res = re.findall(r'(\d)(\1{2,})','122223')
print(res) # [('2', '222')]
res = re.findall(r'(\d)(\1{2,})','111222')
print(res) # [('1', '11'), ('2', '22')]
# 处理数据
print([x[1] for x in res]) # ['11', '22']
# 拼接
print([x[0]+x[1] for x in res]) # ['111', '222']
位置匹配
开始和结束
- ^ : 开始
- $ : 结束
res = re.findall(r'\d{11}','13700000000')
print(res) # ['13700000000']
# ^ $ 开始和结束
res = re.findall(r'^\d{11}$','13700123231')
print(res) # ['13700123231']
Python3 json 标准库
json是轻量级文本数据交换格式。JavaScript对象表示法(Java Script Object Notation),是很常用的数据格式。
示例:
# json 对象
{
"firstName":"john","lastName":"Doe"}
# json数组
{
"emps":[
{
"firstName":"john","lastName":"Doe"},
{
"firstName":"amay","lastName":"Doa"},
{
"firstName":"kyes","lastName":"Dob"}
]
}
# 访问元素
emps[0].lastName = "aab"
标准库的使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gRAW2a3B-1649321364712)(imgs4/2.png)]](https://img-blog.csdnimg.cn/37f5d9ed79cf44849502eb521608c663.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6bii5bC-Xw==,size_20,color_FFFFFF,t_70,g_se,x_16)
json转为python时,和上图基本类似,反向即可
不同的是:
| json | python |
|---|---|
| number(int) | int |
| number(real) | float |
- 使用json字符串生成python对象或者叫解析json(load)
- json.load(fp):从json的文件中读取数据并且转换为python的类型
- json.loads(s):将json格式的字符串转换为python的类型
import json
# 从python对象格式化为 json String
person = {
"name": 'sniper', 'age': 30, 'tel': ['11111111111', '22222222222'], 'isonly': True}
print(person) # {'name': 'sniper', 'age': 30, 'tel': ['11111111111', '22222222222'], 'isonly': True}
jsonStr = json.dumps(person, indent=4, sort_keys=True) # indet=4 带缩进的,有格式的(可读性高) sort_keys=True 键排序
print(jsonStr) # {"name": "sniper", "age": 30, "tel": ["11111111111", "22222222222"], "isonly": true}
json.dump(person, open('data.json', 'w', encoding='UTF-8'), indent=4) # 格式化python对象,并写入到文件中
-
把python对象格式化为json字符串(dump)
-
json.dump(obj, fp):将python数据类型转换并保存到Json格式的文件中
-
pythonObj = json.load(open('data.json', 'r', encoding='utf-8')) print(pythonObj) # {'emps': [{'firstName': 'john', 'lastName': 'Doe'}, {'firstName': 'amay', 'lastName': 'Doa'}, {'firstName': 'kyes', 'lastName': 'Dob'}]} print(type(pythonObj)) # <class 'dict'>
-
-
json.dumps(obj):将python数据类型转换为JSON格式的字符串
-
# 从json String解析为 python对象 pythonObj = json.loads('{"name": "sniper", "age": 30, "tel": ["11111111111", "22222222222"], "isonly": true}') print(type(pythonObj)) # <class 'dict'> print(pythonObj) # {'name': 'sniper', 'age': 30, 'tel': ['11111111111', '22222222222'], 'isonly': True} s = '["1","2","3"]' pythonObj = json.loads(s) print(type(pythonObj)) # <class 'list'> print(pythonObj) # ['1', '2', '3']
-
-
logging日志库
日志级别:
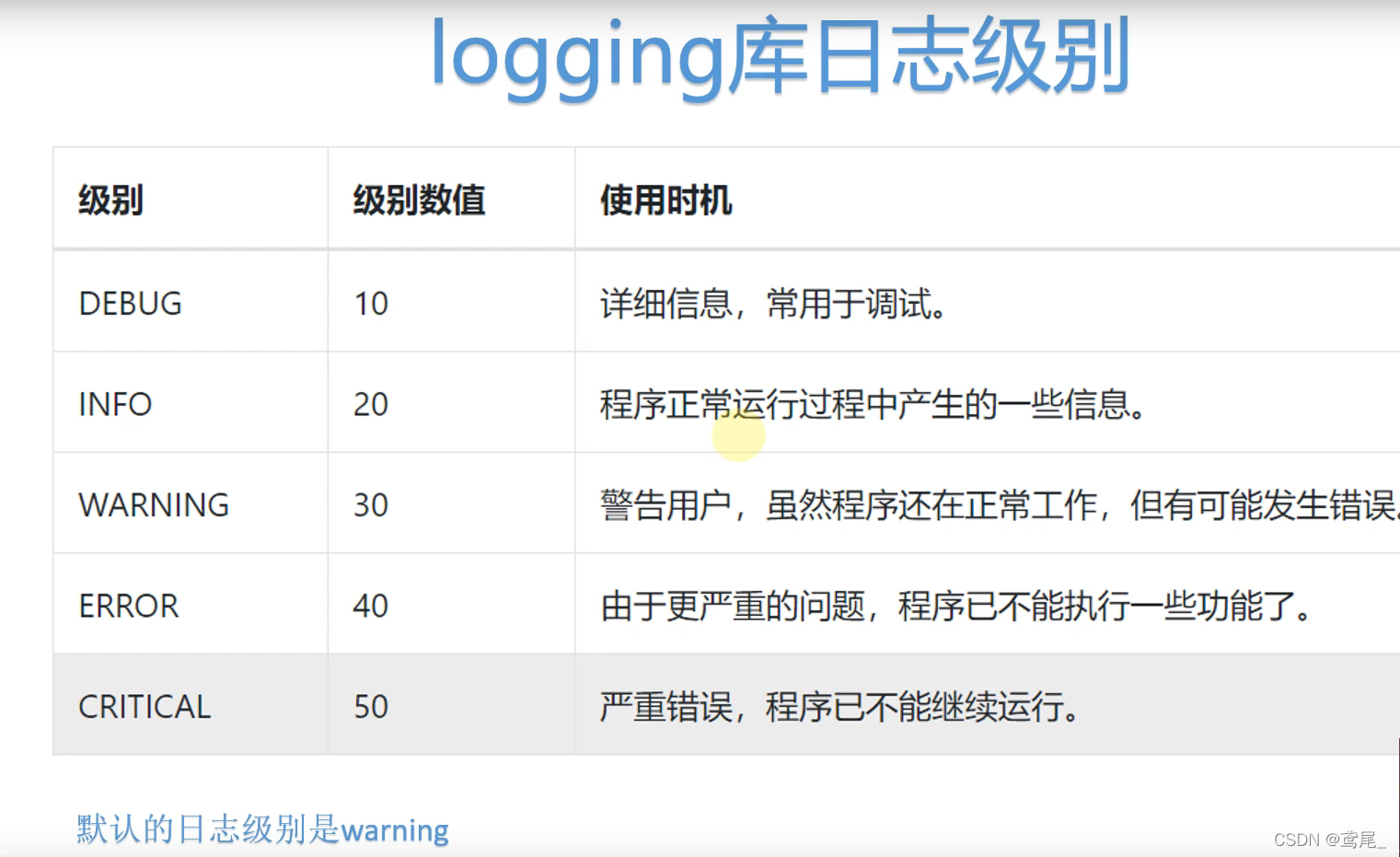
当日志级别是 INFO级别,那么 >= INFO级别的日志都会被输出,小于INFO级别的日志不会被输出。
默认的日志级别
# 默认的日志输出级别是 warning,所以debug和info不会输出
logging.debug('this is a debug log')
logging.info('this is a info log')
logging.warning('this is a warning log') # WARNING:root:this is a warning log
logging.error('this is a error log') # ERROR:root:this is a error log
初级原理
设置日志级别
logging.basicConfig(level=logging.INFO)
logging.basicConfig(level=logging.INFO) # 设置为 INFO级别,那么debug级别将不会输出
logging.debug('this is a debug log')
logging.info('this is a info log') # INFO:root:this is a info log
logging.warning('this is a warning log') # WARNING:root:this is a warning log
logging.error('this is a error log') # ERROR:root:this is a error log
日志输出到文件中
默认是追加模式写入到日志文件中
logging.basicConfig(filename='demo.log', level=logging.INFO) # 设置为 INFO级别
设置文件模式
设置为覆盖模式,每次执行时,都会去覆盖demo.log文件
logging.basicConfig(filename='demo.log', filemode='w', level=logging.INFO) # INFO级别
向日志输出变量
可以使用string的格式化,%、{}.format()、f-str
# 设置日志级别
log.basicConfig(level=log.DEBUG)
name = 'zs'
age = 21
log.debug(f'姓名:{
name}, 年龄:{
age}')
格式化输出内容
添加公共信息到日志中
import logging as log # 设置别名
# 设置日志级别
log.basicConfig(level=log.DEBUG, format="%(asctime)s|%(levelname)s|%(filename)s:%(lineno)s|%(message)s",
datefmt='%Y-%m-%d %H:%M:%S')
name = 'zs'
age = 21
log.debug(f'姓名:{
name}, 年龄:{
age}') # 2022-04-06 15:04:15|DEBUG|demo1.py:10|姓名:zs, 年龄:21
log.warning(f'姓名:{
name}, 年龄:{
age}') # 2022-04-06 15:04:15|WARNING|demo1.py:11|姓名:zs, 年龄:21
高级应用
logging模块采用了模块化设计,主要包含四种组件:
- Loggers: 记录器,提供应用程序代码能直接使用的接口(用哪根笔去写日志)
- Handlers: 处理器,将记录器产生的日志发送至目的地(邮件、控制台、文件)
- Filters: 过滤器,提供更好的粒度控制,决定那些日志会被输出(日志级别)
- Formatters: 格式化器,设置日志内容的组成结构和消息字段
工作流程:
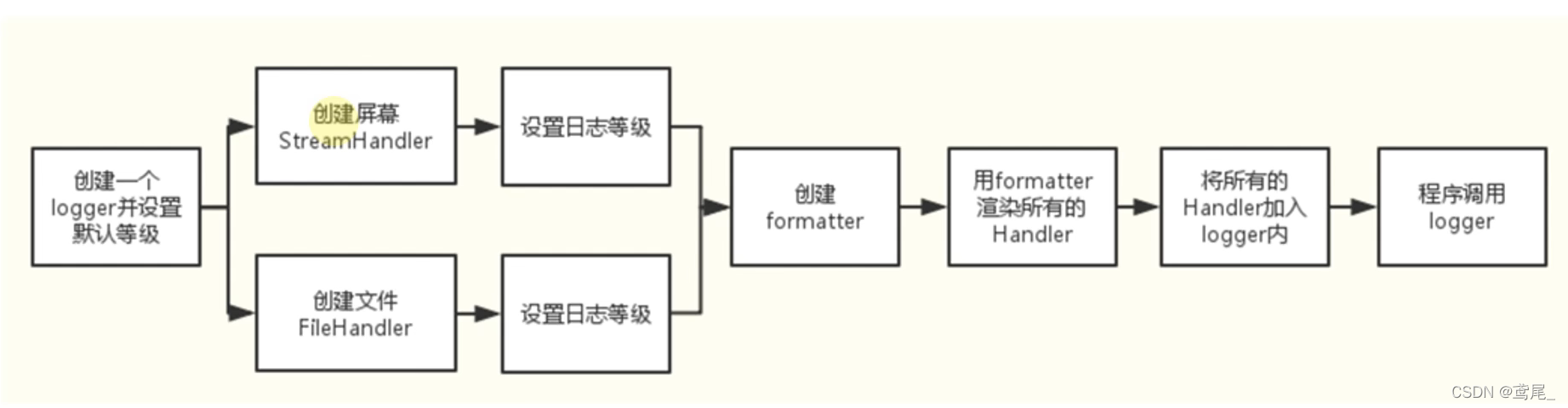
Loggers记录器
# logger是单例的
logger = logging.getLogger(__name__)
# 设置logger的日志级别
logger.setLevel()
# 将日志内容传递到相关联的handlers中
logger.addHandler() 和 logger.removeHandler()
Handlers处理器
将日志发送到不同的目的地,可以是文件、控制台、邮件或通过socket、http等协议发送到任何地方。
几种常见的处理器:StreamHandler、FileHandler、TimedRotatingFileHandler
-
StreamHandler: 标准输出
sh = logging.StreamHandler(stream=None)创建 -
FileHandler
fh = logging.FileHandler(filename, mode='a',encoding=None,delay=False)创建
# 记录器
logger = log.getLogger() # 不写时,使用Root
logger.setLevel(log.DEBUG)
print(logger) # <RootLogger root (DEBUG)>
logger = log.getLogger('applog')
print(logger) # <Logger applog (DEBUG)>
编程方式(注重原理,不适用)
实例
import logging as log
# 记录器
logger = log.getLogger('applog')
logger.setLevel(log.INFO)
# 处理器 handler
# 控制台处理器
consoleHandler = log.StreamHandler() # 标准输出 到控制台
consoleHandler.setLevel(log.DEBUG) # 处理器设置日志级别,会和记录器比较级别,采用等级高的那个(此种情况下,会采用 INFO级别)
# 文件处理器
# 不给handler指定日志级别,将会使用logger的级别
fileHandler = log.FileHandler(filename='addDemo.log', encoding='UTF-8')
# 格式 formatter
formatter = log.Formatter('%(asctime)s|%(levelname)s|%(filename)s:%(lineno)s|%(message)s')
# 给处理器设置格式
consoleHandler.setFormatter(formatter)
fileHandler.setFormatter(formatter)
# 记录器设置处理器
logger.addHandler(consoleHandler)
logger.addHandler(fileHandler)
# 打印日志(使用记录器去记录日志)
logger.debug('this is a debug log')
logger.info('this is a info log') # 2022-04-06 15:58:43,135|INFO|demo2.py:33|this is a info log
logger.warning('this is a warning log') # 2022-04-06 15:58:43,135|WARNING|demo2.py:34|this is a warning log
logger.error('this is a error log') # 2022-04-06 15:58:43,135|ERROR|demo2.py:35|this is a error log
以上注意:当记录器设置了日志级别时,处理器再去设置日志级别是没有用处的,还是会采用记录器的日志级别,所以当想让处理器有不同的日志级别时,要给记录器设置最低级DEBUG日志级别(因为如果不设置就会默认为warning级别),给处理器单独设置即可。
过滤器
import logging as log
# 记录器
logger = log.getLogger('cn.cccb.applog')
logger.setLevel(log.DEBUG)
# 定义过滤器(过滤记录器和处理器的)
flt = log.Filter('cn.cccb') # 以cn.cccb开头的对象名,是符合的
# 记录器关联过滤器(当记录器的名称是 cn.cccb开头时才不会被过滤掉)
logger.addFilter(flt)
配置方式(推荐使用)
配置一个logging.conf配置文件
请注意:以下文件中的中文注释只是帮助理解,如需使用,请把文件中的中文注释全部删掉,否则可能会导致读取文件时报编码错误!!!
#记录器:提供应用程序代码直接使用的接口
#设置记录器名称,root必须存在!!!
[loggers]
keys=root,applog
#处理器,将记录器产生的日志发送至目的地
#设置处理器类型
[handlers]
keys=fileHandler,consoleHandler
#格式化器,设置日志内容的组成结构和消息字段
#设置格式化器的种类
[formatters]
keys=simpleFormatter
#设置记录器root的级别与种类
[logger_root]
level=DEBUG
handlers=consoleHandler
#设置记录器applog的级别与种类
[logger_applog]
level=DEBUG
handlers=fileHandler,consoleHandler
#起个对外的名字
qualname=applog
#继承关系
propagate=0
#设置
[handler_consoleHandler]
class=StreamHandler
args=(sys.stdout,)
level=DEBUG
formatter=simpleFormatter
[handler_fileHandler]
class=handlers.TimedRotatingFileHandler
#在午夜1点(3600s)开启下一个log文件,第四个参数0表示保留历史文件
#第三个参数表示午夜的第几秒开始做
args=('applog.log','midnight',3600,0)
level=DEBUG
formatter=simpleFormatter
[formatter_simpleFormatter]
format=%(asctime)s|%(levelname)8s|%(filename)s[:%(lineno)d]|%(message)s
#设置时间输出格式
datefmt=%Y-%m-%d %H:%M:%S
引入使用
import logging.config
# 配置文件方式
logging.config.fileConfig('logging.conf')
logger = logging.getLogger('applog') # 拿到 applog 记录器
logger.debug('this is a debug log applog')
rootLogger = logging.getLogger() # 拿到 root 记录器
rootLogger.debug('this is a debug log root')
# 全面的错误信息,不使用 error,而是用exception()
a = 'aaa'
try:
int(a)
except Exception as e:
logger.exception(e) # 错误信息更全面(携带栈信息)
实际生产中,为方便快速定位问题,一定要使用logger.exception()来展示更全面的异常信息!!!
数据库操作
SQLite数据库(轻量级)
SQLite的使用
使用步骤:
- 连接数据库
- 拿到游标
- 执行sql
- 关闭游标
- 关闭数据库连接
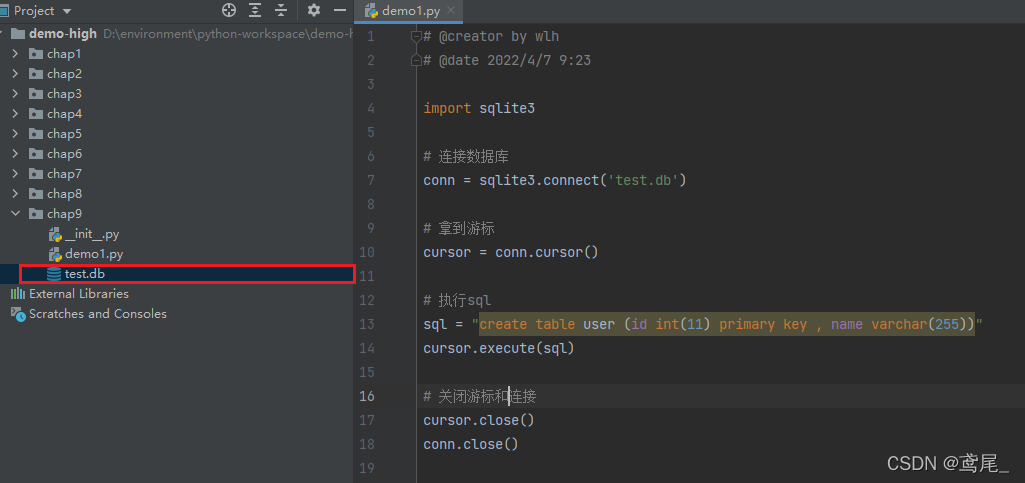
import sqlite3
# 连接数据库
conn = sqlite3.connect('test.db')
# 拿到游标
cursor = conn.cursor()
# 执行sql
sql = "create table user (id int(11) primary key , name varchar(255))"
cursor.execute(sql)
# 关闭游标和连接
cursor.close()
conn.close()
可看到,创建了一个test.db数据库
- 执行insert
当涉及到增删改数据时,要提交事务,否则会回滚
# 执行sql
sql = "insert into user (id, name) values(1,'zs')"
cursor.execute(sql)
# 提交事务
conn.commit()
- select
查询时不必提交事务

# 执行sql
sql = "select * from user"
cursor.execute(sql)
result = cursor.fetchall()
print(result) # [(1, 'zs'), (2, 'ls')] 得到的是一个列表套元组
完善
import sqlite3
# 连接数据库
conn = sqlite3.connect('test.db')
# 拿到游标
cursor = conn.cursor()
try:
# 执行sql
sql = "insert into user (id,name) values(1,'zs')"
cursor.execute(sql) # 执行sql
conn.commit() # 提交事务
except Exception as e:
conn.rollback() # 失败就回滚事务
finally:
# 关闭游标和连接
cursor.close()
conn.close()
MySQL
终端安装第三方模块pymysql,pip install pymysql
如果安装较慢,可以使用国内的镜像地址
使用国内镜像
windows:
在用户目录下创建一个pip文件夹
创建一个pip.ini文件
[global]
timeout = 10000
index-url = http://mirrors.aliyun.com/pypi/simple/
trusted-host = mirrors.aliyun.com
配置完成即可。
使用pymysql
import pymysql
# 1 连接mysql 2 拿到游标 3 执行sql 4 关闭游标 5 关闭连接
# 连接mysql
conn = pymysql.connect(user='root',password='134520',host='localhost',database='db_test')
# 拿到游标
cursor = conn.cursor()
sql = 'create table user(id int(11) primary key , name varchar(50))'
cursor.execute(sql) # 执行sql
cursor.close() # 关游标
conn.close() # 关连接
补充(回忆基础):
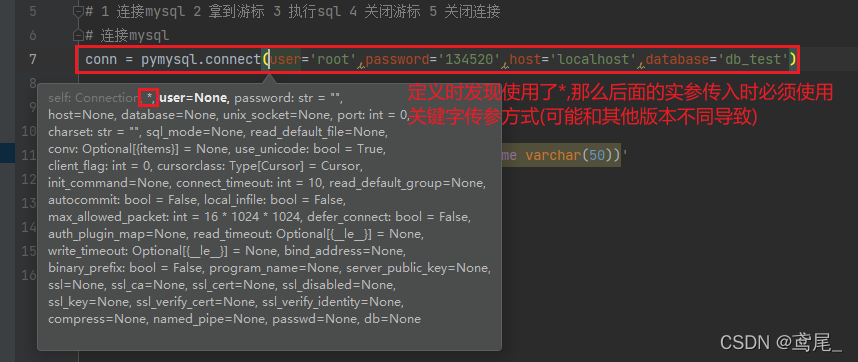
使用pymysql和sqlite没什么区别,主要是数据库的连接方式不同而已,其他的概念都相同。
完善
数据库的连接数据可使用字典传入参数(关键字传参)
import pymysql
# 1 连接mysql 2 拿到游标 3 执行sql 4 关闭游标 5 关闭连接
# 连接数据
dst = {
'user': 'root',
'password': '134520',
'host': '192.168.0.103',
'database': 'db_test'
}
# 连接mysql
conn = pymysql.connect(**dst)
# 拿到游标
cursor = conn.cursor()
try:
sql = "insert into user (id,name) values(1,'zs')"
cursor.execute(sql) # 执行sql
conn.commit()
except Exception as e:
conn.rollback()
finally:
cursor.close() # 关游标
conn.close() # 关连接
枚举
作用:
- 可读性
- 防止修改
- 防止重复
创建(程序运行中不能修改)、访问
from enum import Enum
class COLOR(Enum):
RED = 1
GREEN = 2
BLACK = 3
BLUE = 4
# 访问
print(COLOR.RED) # COLOR.RED
print(COLOR['RED']) # COLOR.RED
print(COLOR(1)) # COLOR.RED 单例模式的
print(COLOR.RED.name) # RED
print(COLOR.RED.value) # 1
COLOR.RED = 6 # 将会报错,枚举不能被修改
print('----------------------')
for c in COLOR: # 遍历
print(c)
防止重复
key相同
class COLOR(Enum):
RED = 1 # 当key有相同的时,运行会报错
RED = 5
GREEN = 2
BLACK = 3
BLUE = 4
value相同
class COLOR(Enum):
RED = 1
RED1 = 1 # 当有值相同时,从第二个开始则被认为是第一个key的别名,而且通常循环和遍历时别名key会被隐藏,不会被输出
GREEN = 2
BLACK = 3
BLUE = 4
强制value唯一
from enum import Enum, unique
@unique # 使用unique装饰器
class COLOR(Enum):
RED = 1
GREEN = 1 # 值相同,会报错
BLACK = 3
BLUE = 4
继承其他类型的Enum
from enum import Enum, IntEnum
class COLOR(IntEnum):
RED = 1
GREEN = 2
BLACK = 3
BLUE = 'a' # 运行报错,继承自IntEnum,value值只能是int类型
闭包(了解知识理论)
函数式编程 python
-
函数任意位置的定义(比如多函数 嵌套)
-
函数可以作为另一个函数的返回值,或者参数来使用
def fun_out():
def fun_in(): # 嵌套函数
print('i am func_in')
return fun_in # 函数作为返回值
f = fun_out() # 获取到 fun_in函数对象
f() # i am func_in
闭包
函数 + 环境参数
def func_out():
rate = 6 # 局部变量
def transfer(dollar):
return dollar * rate
return transfer
rate = 7 # 全局变量,无法改变函数内的 局部变量
f = func_out()
print(f(10)) # 60 闭包现象(找的还是func_out函数定义的变量)
旅行者例子:
不使用闭包
origin = 0
def gogo(step):
global origin
target = origin + step
origin = target
return target
print(gogo(2)) # 2
print(gogo(3)) # 5
print(gogo(6)) # 11
使用闭包
nonlocal关键字
def creator(start):
def gogo(step):
nonlocal start # 不是在本地,且不是全局变量(依次向上找)
target = start + step
start = target
return target
return gogo
f = creator(0)
print(f(2)) # 每执行一次 start的值都会被修改
print(f(3))
print(f(6))
匿名函数和高阶函数
匿名函数
语法lambda params:expression
- params:参数列表
- expression:表达式
表达式只能写一些简单语句,不能写复杂的语句
lambda x, y: x + y # 匿名函数
# 匿名函数 + 三目表达式
lambda x, y: x if x > y else y
高阶函数
- sorted(): 排序
my_list = [
('a', 5),
('b', 3),
('c', 8),
('d', 2)
]
my_list = sorted(my_list, key=lambda x: x[1]) # 每次遍历的x,就是一个个的元组
print(my_list) # [('d', 2), ('b', 3), ('a', 5), ('c', 8)]
- map() : map映射lambda
my_list = [1, 2, 3, 4, 5, 6]
res = map(lambda x: x ** 2, my_list) # 返回一个map对象
print(list(res)) # [1, 4, 9, 16, 25, 36]
--------------------------------------------------------------
my_list = [1, 2, 3, 4, 5, 6]
my_list2 = [1, 2, 3, 4, 5, 6]
res = map(lambda x, y: x + y, my_list, my_list2) # 返回一个map对象
print(list(res)) # [2, 4, 6, 8, 10, 12]
- reduce() : 规约函数
from functools import reduce
res = reduce(lambda x, y: x + y, range(1, 101)) # x和y是列表的第一个和第二个元素,得到值后,x=上一个x+y的值,y是列表中下一个值,一个个迭代
print(res) # 5050
reduce(lambda x, y: x + y, range(1, 101),100) # 第三个参数,初始值,x是初始值,y是列表第一个元素,以此类推
- filter() : 过滤
my_list = [1, 0, 0, 11, 0, 12, 0]
# 会过滤掉为False的值
res = filter(lambda x: True if x != 0 else False, my_list)
print(list(res)) # [1, 11, 12]
time标准库(基础)
基本使用
import time
# 时间戳(浮点数)
print(time.time())
# 结构化时间对象
st = time.localtime() # struct_time类实例对象
print(st)
# st本质上是一个元组(不可更改的)
print('今天是{}-{:02d}-{:02d}'.format(st[0], st[1], st[2])) # 今天是2022-04-07
# 格式化时间字符串
print(time.ctime()) # Thu Apr 7 14:51:59 2022
# strftime(时间格式) '%Y-%m-%d %H:%M:%S'
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2022-04-07 14:53:38
print(time.strftime('%Y年%m月%d日 %H时%M分%S秒')) # 2022年04月07日 14时54分20秒
'''
%W: 本周是今年的第几周
%a: 本周的缩写 %A:本周的全称
'''
- sleep()
线程休眠
time.sleep(1.23) # 休眠1.23秒
- 程序执行时间
t1 = time.time()
....
t2 = time.time()
print('执行了{:.3f}秒'.format(t2-t1))
三种格式之间的转换
时间戳 -> 结构化对象
import time
# UTC时间
print(time.gmtime())
print(time.gmtime(time.time()))
# local时间
print(time.localtime())
print(time.localtime(time.time() - 3600)) # 计算一个小时之前
结构化 -> 时间戳
import time
print(time.time()) # 1649316342.619856
print(time.mktime(time.localtime())) # 1649316342.0 (精度是秒)
结构化对象 -> 格式化时间字符串
import time
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())) # 2022-04-07 15:28:42
格式化字符串 -> 结构化对象
import time
strTime = '2022-04-07 15:31:25'
print(time.strptime(strTime, '%Y-%m-%d %H:%M:%S')) # time.struct_time(tm_year=2022, tm_mon=4, tm_mday=7, tm_hour=15, tm_min=31, tm_sec=25, tm_wday=3, tm_yday=97, tm_isdst=-1)
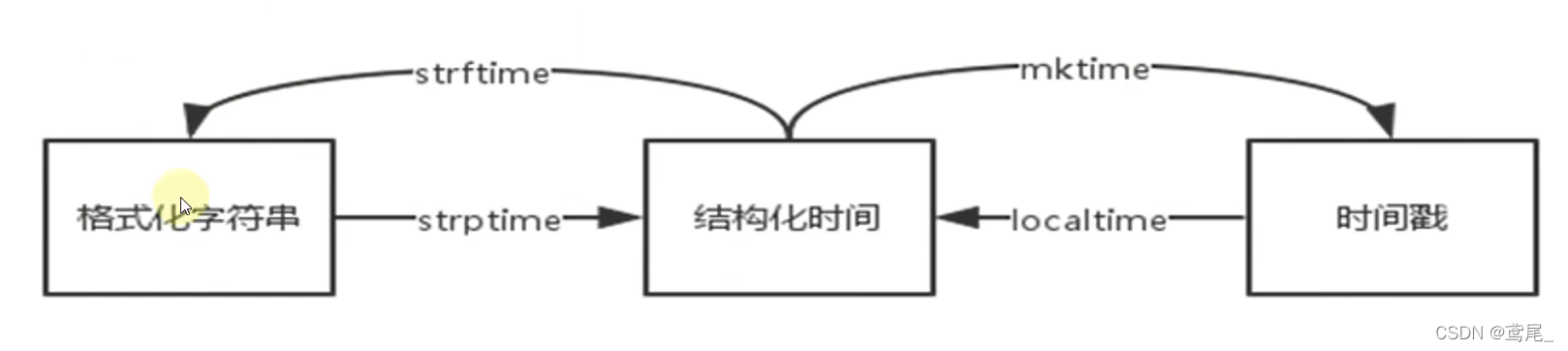
datetime标准库(封装)

date
常用
import datetime
# datetime.date 只处理日期
import time
d = datetime.date.today() # 当前日期
print(d) # 2022-04-07
d = datetime.date(2022, 4, 7) # 构造函数生成
print(d) # 2022-04-07
d = datetime.date.fromtimestamp(time.time()) # 从时间戳生成
print(d) # 2022-04-07
# 实例属性
print(d.year, d.month, d.day) # 2022 4 7
# 实例方法
# 替换
d = d.replace(2023, 5, 20) # 生成了个新对象
print(d) # 2023-05-20
# 周几
print(d.weekday()) # 3 代表周四(0代表周一)
print(d.isoweekday()) # 4 周四 (0代表周日)
# 格式化字符串
print(d.strftime('%Y年%m月%d日')) # 2022年04月07日
date对象 -> 结构化时间对象
实例方法timetuple(),获取结构化时间对象
d = datetime.date.today()
# 实例方法
print(d.timetuple())
time
import datetime
t = datetime.time(16, 11, 45)
print(t) # 16:11:45
# 实例属性
print(t.hour, t.minute, t.second, t.microsecond) # 16 11 45 0
# 方法
print(t.strftime('%H时%M分%S秒')) # 16时11分45秒
datetime
常用
import datetime
# 生成
dt = datetime.datetime(2022, 4, 7, 16, 16, 15)
print(dt) # 2022-04-07 16:16:15
dt = datetime.datetime.now(tz=None) # 可设置时区
print(dt) # 2022-04-07 16:19:24.474342
dt = datetime.datetime.today() # 当前时间
print(dt) # 2022-04-07 16:19:24.474460
dt = datetime.datetime.utcnow() # 获取utc时间
print(dt)
# 实例方法
dt = dt.replace(second=59)
print(dt)
常用实例方法
datetime -> 结构化对象
dt.timetuple()
datetime -> 时间戳
dt.timestamp()
datetime -> 字符串时间
dt.strftime('%Y-%m-%d %H:%M:%S')
格式化对象 -> datetime
dt.strptime('2022-04-07 16:33:34', '%Y-%m-%d %H:%M:%S')
时间戳 -> datetime
import datetime
# 生成
import time
dt = datetime.datetime.fromtimestamp(time.time())
print(dt) # 2022-04-07 16:21:46.380139
字符串 -> datetime
strTime = '2022-04-07 16:21:46'
dt = datetime.datetime.strptime(strTime, '%Y-%m-%d %H:%M:%S')
print(dt) # 2022-04-07 16:21:46
date,time -> datetime
import datetime
d = datetime.date.today()
t = datetime.time(16, 25, 45)
dt = datetime.datetime.combine(d, t)
print(dt)
关系图
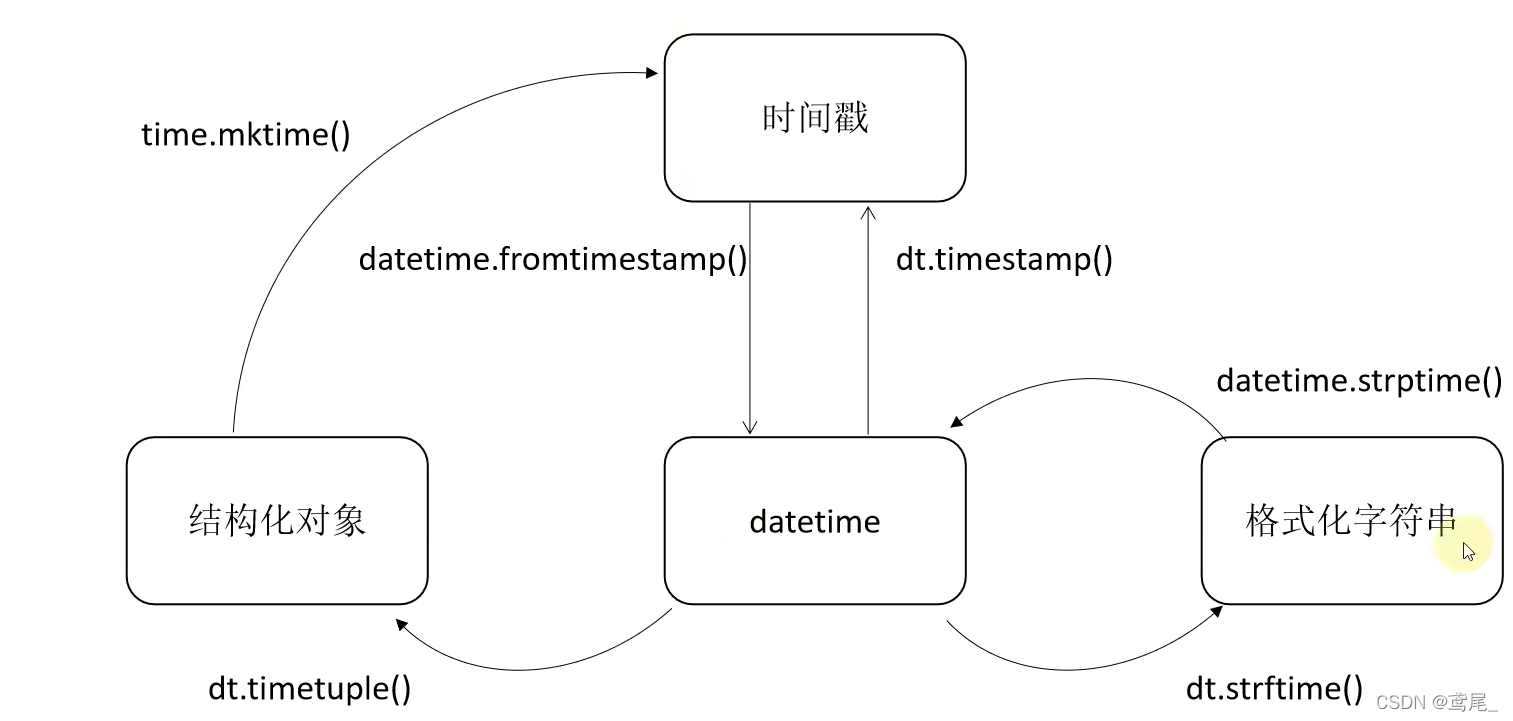
timedelta(求时间差)
import datetime
# 生成
td = datetime.timedelta(10, hours=3)
print(td) # 10 days, 3:00:00
td = datetime.timedelta(-5, hours=3)
print(td) # -5 days, 3:00:00
td = datetime.timedelta(weeks=2)
print(td) # 14 days, 0:00:00
计算目标日期
import datetime
# 计算日期
dt = datetime.datetime.today()
print(dt) # 2022-04-07 16:43:52.576797
td = datetime.timedelta(days=10) # 十天后
target = dt + td
print(target) # 2022-04-17 16:43:52.576797
计算时间差
import datetime
# 计算日期
dt1 = datetime.datetime.today()
dt2 = datetime.datetime.utcnow()
td = dt1 - dt2
print(td, type(td)) # 8:00:00 <class 'datetime.timedelta'>
print('相差{:.0f}个小时'.format(td.seconds / 3600)) # 相差8个小时
datetime
```python
import datetime
# 生成
import time
dt = datetime.datetime.fromtimestamp(time.time())
print(dt) # 2022-04-07 16:21:46.380139