本专栏将从基础开始,循序渐进,讲解数据库的基本概念以及使用,希望大家都能够从中有所收获,也请大家多多支持。
专栏地址: 数据库必知必会
相关软件地址:软件地址
如果文章知识点有错误的地方,请指正!大家一起学习,一起进步。
文章目录
1 单表查询
1.1 基本查询语法
select [*][列名 ,列名][列名 as 别名 ...] [distinct 字段] from 表名 [where 条件]
2 简单查询
2.1 查询所有的列的记录
- 语法
select * form 表
- 查询商品表里面的所有的列
select * from product;
2.2 查询某张表特定列的记录
- 语法
select 列名,列名,列名... from 表
- 查询商品名字和价格
select pname, price from product;
2.3 去重查询
- 语法
SELECT DISTINCT 字段名 FROM 表名; //要数据一模一样才能去重
- 去重查询商品的价格
select distinct price from product;
注意点: 去重针对某列, distinct前面不能先出现列名
2.4 别名查询
- 语法
select 列名 as 别名 ,列名 from 表 //列别名 as可以不写
select 别名.* from 表 as 别名 //表别名(多表查询, 明天会具体讲)
- 查询商品名称和商品价格,商品价格通过别名‘价格’来显示
select pname , price as 价格 from product;
2.5 运算查询(+,-,*,/等)
- 把商品名,和商品价格+10查询出来
select pname ,price+10 from product;
注意
- 运算查询字段,字段之间是可以的
- 字符串等类型可以做运算查询,但结果没有意义
3 条件查询
3.1 语法
select ... from 表 where 条件
//取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回
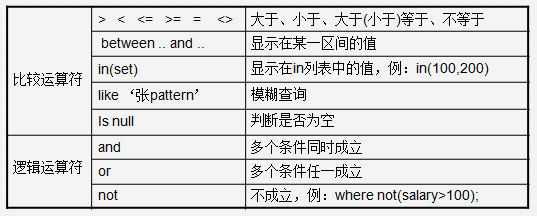
- between…and… 区间查询
eg: where price between 1000 and 3000 相当于 1000<=price<=3000
- in(值,值…)
-- 查询id为1,3,5,7的
select * from t_product where id = 1
select * from t_product where id = 3
select * from t_product where id = 5
select * from t_product where id = 7
select * from t_product where id in(1,3,5,7)
- like 模糊查询 一般和_或者%一起使用
- _ 占一位
- % 占0或者n位
name like '张%' --查询姓张的用户, 名字的字数没有限制
name like '张_' --查询姓张的用户 并且名字是两个的字的
- and 多条件同时满足
where 条件1 and 条件2 and 条件3
- or 任意条件满足
where 条件1 or 条件2 or 条件3
3.2 练习
- 查询商品价格>3000的商品
- 查询id=1的商品
- 查询id<>1的商品
- 查询价格在3000到6000之间的商品
- 查询id在1,5,7,15范围内的商品
- 查询商品名以iPho开头的商品(iPhone系列)
- 查询商品价格大于3000并且数量大于20的商品 (条件 and 条件 and…)
- 查询id=1或者价格小于3000的商品
select * from product where price > 3000;
select * from product where pid = 1;
select * from product where pid <> 1;
select * from product where price between 3000 and 6000;
select * from product where id in (1,5,7,15);
select * from product where pname like 'iPho%';
select * from product where price > 3000 and num > 20;
select * from product where pid = 1 or price < 3000;
3.3 小结
- 语法
select [*],[列名,列名],[列名 as 别名],[distinct 列名],[列(+,-..)] from 表名 [where 条件]
- 条件
- where price > 2000
- where id = 1
- where id <> 1
- where name like ‘张%’
- where price between 3000 and 5000
- where id in(1,3,5,7,10)
- where name like ‘张%’ and age > 10
- where name like ‘张%’ or age <60
- 逻辑运算符
4 排序查询
有时候我们需要对查询出来的结果排序显示,那么就可以通过ORDER BY子句将查询出的结果进行排序。排序可以根据一个字段排,也可以根据多个字段排序,排序只是对查询的结果集排序,并不会影响表中数据的顺序。
4.1 环境的准备
# 创建学生表(有sid,学生姓名,学生性别,学生年龄,分数列,其中sid为主键自动增长)
CREATE TABLE student(
sid INT PRIMARY KEY auto_increment,
sname VARCHAR(40),
sex VARCHAR(10),
age INT,
score DOUBLE
);
INSERT INTO student VALUES(null,'zs','男',18,98.5);
INSERT INTO student VALUES(null,'ls','女',18,96.5);
INSERT INTO student VALUES(null,'ww','男',15,50.5);
INSERT INTO student VALUES(null,'zl','女',20,98.5);
INSERT INTO student VALUES(null,'tq','男',18,60.5);
INSERT INTO student VALUES(null,'wb','男',38,98.5);
INSERT INTO student VALUES(null,'小丽','男',18,100);
INSERT INTO student VALUES(null,'小红','女',28,28);
INSERT INTO student VALUES(null,'小强','男',21,95);
4.2 单列排序
- 语法: 只按某一个字段进行排序,单列排序
SELECT 字段名 FROM 表名 [WHERE 条件] ORDER BY 字段名 [ASC|DESC]; //ASC: 升序,默认值; DESC: 降序
- 练习: 以分数降序查询所有的学生
SELECT * FROM student ORDER BY score DESC
4.3 组合排序
- 语法: 同时对多个字段进行排序,如果第1个字段相等,则按第2个字段排序,依次类推
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名1 [ASC|DESC], 字段名2 [ASC|DESC];
- 练习: 以分数降序查询所有的学生, 如果分数一致,再以age降序
SELECT * FROM student ORDER BY score DESC, age DESC
小结
- 排序的语法
order by 列 asc/desc, 列 asc/desc;
asc: 升序【默认值】
desc: 降序
-
应用场景
商城里面 根据价格, 销量, 上架时间, 评论数…
社交里面 根据距离排序
5 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值NULL
| 聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值 |
| count(列名) | 统计这一列有多少条记录 |
| sum(列名) | 对这一列求总和 |
- 语法
SELECT 聚合函数(列名) FROM 表名 [where 条件];
- 练习
-- 求出学生表里面的最高分数
-- 求出学生表里面的最低分数
-- 求出学生表里面的分数的总和(忽略null值)
-- 求出学生表里面的平均分
-- 统计学生的总人数 (忽略null)
SELECT MAX(score) FROM student
SELECT MIN(score) FROM student
SELECT SUM(score) FROM student
SELECT AVG(score) FROM student
SELECT COUNT(sid) FROM student
SELECT COUNT(*) FROM student
注意: 聚合函数会忽略空值NULL
我们发现对于NULL的记录不会统计,建议如果统计个数则不要使用有可能为null的列,但如果需要把NULL也统计进去呢?我们可以通过 IFNULL(列名,默认值) 函数来解决这个问题. 如果列不为空,返回这列的值。如果为NULL,则返回默认值。
小结
- 语法
select 聚合函数(列) from 表名;
-
聚合函数
- max() 最大值
- min() 最小值
- sum() 求和
- avg() 平均值
- count() 统计数量
-
注意事项
- 聚合函数会忽略null值的,
- 可以通过 IFNULL(列名,默认值) 函数来解决这个问题. 如果列不为空,返回这列的值。如果为NULL,则返回默认值。
6 分组查询
分组查询是指使用 GROUP BY语句对查询信息进行分组
GROUP BY怎么分组的? 将分组字段结果中相同内容作为一组,如按性别将学生分成两组
GROUP BY将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用
6.1 分组
- 语法
SELECT 字段1,字段2... FROM 表名 [where 条件] GROUP BY 列 [HAVING 条件];
- 练习:根据性别分组, 统计每一组学生的总人数
-- 根据性别分组, 统计每一组学生的总人数
SELECT sex, count(*) FROM student GROUP BY sex
6.2 分组后筛选 having
- 练习根据性别分组, 统计每一组学生的总人数> 5的(分组后筛选)
SELECT sex, count(*) FROM student GROUP BY sex HAVING count(*) > 5
小结
- 分组语法
group by 列 [having 条件]
-
注意事项
单独分组 没有意义, 返回每一组的第一条记录
分组的目的一般为了做统计使用, 所以经常和聚合函数一起使用
分组查询如果不查询出分组字段的值,就无法得知结果属于那组
在分组里面, 如果select后面的列没有出现在group by后面 ,展示这个组的这个列的第一个数据
-
where和having的区别【面试】
| 子名 | 作用 |
|---|---|
| where 子句 | 1) 对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,即先过滤再分组。2) where后面不可以使用聚合函数 |
| having字句 | 1) having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。2) having后面可以使用聚合函数 |
7 分页查询
LIMIT是限制的意思,所以LIMIT的作用就是限制查询记录的条数. 经常用来做分页查询
- 语法
select ... from .... limit 起始行数,查询的记录条数.
| LIMIT a,b; |
|---|
| a起始行数,从0开始计数,如果省略,默认就是0; a=(当前页码-1)*b; |
| b: 返回的行数 |
- 练习
eg: 分页查询学生, 每一页查询4条
b=4; a=(当前页码-1)*b;
第一页: a=0, b=4;
第二页: a=4, b=4;
第三页: a=8, b=4;
小结
- 语法
limit a,b;
a:从哪里开始查询, 从0开始计数 【a=(当前页码-1)*b】
b: 一页查询的数量【固定的,自定义的】
-
应用场景
如果数据库里面的数据量特别大, 我们不建议一次查询出来. 为了提升性能和用户体验, 使用分页
8 查询的语法小结
select...from...[where...][group by...having...][order by...][limit...]
select...from...
select...from...where...
select...from...order by...
select...from...group by...having...
select...from...limit...