我今天给大家分享的题目是《百度大规模战略性混部系统演进》,主要介绍三个方面的内容:第一部分是背景,即我们为什么要做混部。第二部分是混部的方案,我主要围绕两个方面去介绍,一是混部形态下核心的资源管理架构,我会介绍一下百度资源管理架构到底是什么样的,我们在线资源管理架构与离线资源管理架构的技术栈以及它的演进流程;二是混部核心技术,这里包括我们怎么去做容器的隔离,怎么去做资源的超发以及资源模型的优化。最后是收益和未来展望的部分。

为什么要做混部
首先,一个经典的互联网公司成本的构成大概是三个方面,第一是研发成本,也就是你我大家的成本,研发人员的工资。第二个是互联网运营成本,包括线上线做广告、营销等各种各样的成本,这些成本也是不可忽视的,当然我们今天主要是讲的第三个成本,也就是建 IDC 与服务器的成本,这个成本也是经典互联网公司成本构成非常重要的一个部分。
我们怎么去降低公司的成本?提升资源利用率其实就是降低服务器成本的一个非常重要的手段。
资源利用率现状分析
我们在做机房规划的时候有一个非常大的特点,就是离线机房与在线机房分离做规划。举个例子,假如我们在宁夏做一个机房,这个时候肯定考虑做一个离线机房,因为在线机房需要考虑网民请求分布的问题,要获得最好的访问优化体验以及访问速度,势必需要在一些访问热点上去做自己的机房规划,比如北京、上海、广州这样的地方。而对于离线机房来说不用关心这些,它最在乎的是如何提升计算和储存的资源和基础设施的规模。
在线机房与离线机房分别规划存在一个非常大的矛盾点,在于在线业务和离线业务本身的资源需求和特点不一样,我们的资源利用率非常不均衡。对离线来说,它是需要大规模的数据计算和日志数据储存和 AI 训练,它的利用率常态非常高,随着业务的增长它的资源也是常态不足。而对于在线来说,在线需要做大容量资源灾备和高低分的冗余,它的利用率非常低。
我们可以初步通过这个现状分析到,只有将离线、在线机房统一规划才能够充分使用资源,提升资源利用率,从而减少在线与离线服务器采购成本。
混部架构与核心技术
接下来主要讲一下混部的方案与核心的架构,这里面主要讲三个点,一是百度的在离线混部思路,二是百度内部是如何在混部这条路径上发展的,三是混部的资源架构在百度内部是什么样的形态。
在离线混部思路
首先还是从基础说起,什么叫在离线混部?可以从两个方面去解释,一是机房统一规划,我们将在线机房与离线机房统一规划成一个混部机房。二是业务混合运行,我们的在线服务和离线作业同时混合在一台机器上运行。这两者构成了“在离线混部”。
在离线混部的难点在于,我们需要——
1)保证在线不受到影响:在线与离线混合在一起,对离线来说往往是非常耗 CPU 和内存一些业务,我们需要保证离线不要影响在线,在线不会因为 CPU 的干扰而导致一些服务的延迟或者故障;
2)保证离线运行良好:在保证在线不受影响的同时,也需要保证离线运行良好,因为我们做混部实际上要节省离线资源,最终是要给离线做预算的交付;
3)挖潜更多的混部资源:在保证一和二两点的同时,我们还需要挖掘更多的混部资源,要去考虑怎样把 CPU 利用率做到更加极致。
我们今天主要是从前两个方面的难点出发去阐述百度是怎么样做在离线混部的。
百度混部演进历程
简单给大家介绍一下百度混部的演进历程。
百度从 2012 年就开始尝试进入混部技术领域,研发并推广了代理计算(BVC/IDLE)系统。BVC 是我们的搜索业务团队在做的一套资源混部系统,叫代理计算,IDLE 是 INF 团队当年做的基于进程的一套混部系统,这两套系统当年都承担了在离线混部一些工作,但由于架构上受限、资源隔离方案不完备,最终混部出来的计算资源都是不可靠的。
2012 年的时候,我们开始启动 Matrix, 2014 年 Matrix 全面上线,成为了百度虚拟化、容器化的基础设施,目前在百度内部全面应用,并且托管了所有机器。
2014 年,我们也做了另外一个事情,就是将百度所有离线分布式计算框架全部统一到一个资源管理平台,叫 Normandy。这里说到的离线计算框架包括 MapReduce、Spark、MPI 还有机器学习框架等各种分布式计算框架。
2015 年,百度正式启动战略性混部 2.0 项目千寻,并且已经上线。这套系统完全构建在 Matrix 之上,也就是说它是一套容器化的在离线混部的基础设施,并且在 2015 年的时候达到数万台的规模。
2017 年,千寻混部规模呈现更快速增长,在此期间我们做了大量资源隔离与混部核心技术的研究和推广。
2019 年,百度混部的规模已经达到数十万台,这是非常规模化的飞跃,所有新交付的机器已经全部交付给在离线混部,新的机器已经全部可以在线机器和离线机器同时运行。
混部技术栈
这张图是百度的混部技术栈。最底层的部分是机器管理系统 Matrix-Ultron,它托管了百度所有的服务器,实现了整个机器生命周期管理,包括机器自动维修、环境一致性,还有资源化交付等核心工作。
在 Matrix-Ultron 之上就是我们说的 Matrix ,Matrix 我们可以通过多个角度去理解它,首先它是一个容器引擎,类似百度的 Docker,另外 Matrix 本身也支持了开源件 Docker 运行时和镜像协议。Matrix 也支持实例管理、资源模型和资源隔离,Matrix 在单机上做了资源建模,并且提出了优先级资源模型,通过一系列内核态和用户态的技术实现了隔离。资源模型和资源隔离也是混部的核心基础。
在 Matrix 之上承载了三个系统,第一个是在线调度系统。第二个是离线调度系统 Normandy。第三个就是最右边的 AFS 文件系统,它是一套托管文件和磁盘的系统。
在调度系统之上,还有在线 PaaS 系统、MR/Spark 批量计算引擎和 MPI/Paddle 机器学习框架。对于在线 PaaS 来说,目前百度内部有两套系统,分别是 Opera 和 Beehive,分别服务于搜索和非搜索的业务。MR/Spark 批量计算引擎和 MPI/Paddle 机器学习框架则处于离线调度系统之上。AFS 作为 PaaS 系统提供文件服务。
最上面一层是在线服务和离线作业,包括百度内部的所有的业务,这里面有搜索、Feed、凤巢、网盘、度秘、无人车和地图等各种各样的业务。
混部的理论基础
混部的理论基础很简单,我们需要有一套在线与离线在单机上运行的规范,这个规范核心设计点有两套,第一个是基于优先级,第二个需要有超发,因为对于在线来说 Quota 申请往往是按照峰值去申请的,一定会产生资源冗余,我们如何让离线混部上去?需要有一套完整的超发模型,既然有超发之后,我们需要模拟在线与离线两个优先级去对单机上资源优先级进行建模,百度内部基于 Matrix 优先级分为三个 Band,第一个是在线优先级 Stable,其他的两个 Normal 和 Besteffort 都表示离线优先级,Normal 表示我需要有一定的 SLA,它是基本稳定的,Besteffort 表示我是零计费,我不稳定,但是你可以运行。
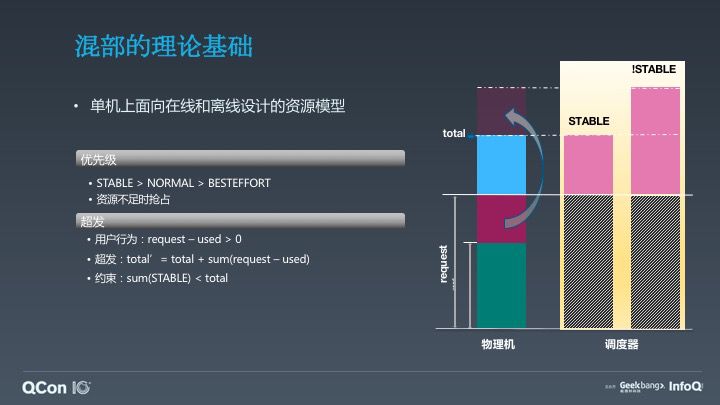
这里面最核心的部分就是超发模型。当用户 request – used > 0,我们可以通过 reclaim 单机资源模式实现整机上的超发。我们这里说的 total 其实就等于,对离线优先级来说,它整机资源 total’就等于 total 单机物理资源,再加上我们超发资源,即 total’= total + sum(request – used)。
混部的核心思路
这是我们在混部上单机在线与离线运行的一套规则规范,这里面有一个非常核心的点,一旦我们实现了超发,势必就需要考虑当资源发生竞争时我们处理的行为,这就是我们讲的混部的核心思路,我们怎么去解决单机上一旦发生资源竞争处理行为。
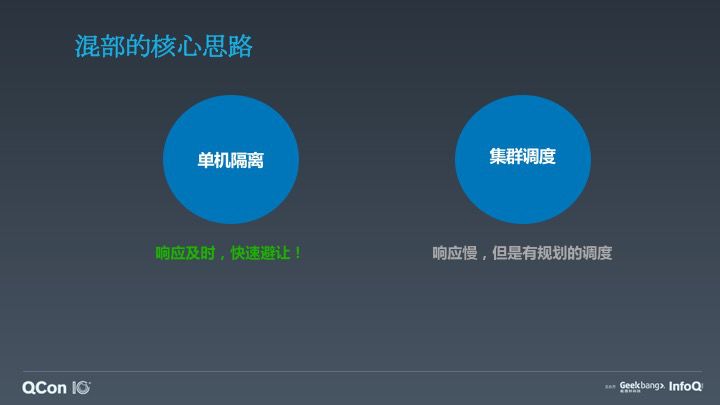
最主要从两个方面解决这个问题,一是通过单机资源隔离做离线避让,二是通过集群调度做一些有规划的事情。单机隔离的优势非常明显,能够做到快速避让,响应及时。而集群调度的响应非常慢,它的好处是可以根据单机上的行为,动态反馈给集群调度做一些更加有规范的动态预测和有规划的调度。
混部的难点有两个,一是怎么去保证在线不要受到影响,二是怎么去保证离线也能运行良好。
1)如何保证在线不受影响:我们基本思路有两个,分别是内核和用户态管控和离线“大框”模型。我们自己研发的单机上的控制组件 Watch-Dog 可以监控所有的在线与离线资源的使用和避让的行为,我们通过内核态与用户态方式同时管控离线资源使用。另外,为了更加安全去控制离线,我们设计了一套离线大框模型,将所有的离线运行在一个受限的大框内,对于 CPU 和内存,我们都是通过大框绑核和内存硬限的方式去解决问题。对 IO 而言,我们通过隔离磁盘、磁盘 IO 隔离的方式解决这个问题,同时在上层如果不能做磁盘的隔离,我们会做各种各样计算框架的优化。我们在网络层面也是通过 QoS 标签去保证在线不要受到离线影响,同时有一套 Transkeeper 组件在离线框架内部去做了一套对内部一些带宽的限流和规整。
在线服务有一个非常大的特点,即使离线资源使用在一个受限的范围之内,仍然有很可能对在线受到影响,这些部分需要我们对混部领域做更深层次的研究。我们做了一些更加精细化资源管控策略。简单列举如下。
离线大框绑核:根据单机 reclaim 资源量;离线内共享;
core-aware:快退避,慢启动,避免 HT 干扰;
HT 干扰规避:自动从迁移离线作业,避免和在线服务干扰;
L3-cache:CAT 隔离;
CPI 干扰抑制:检测、干扰源识别、避让。
我们着重讲一下后四点。对于 care-aware 策略,当在线与离线同时运行 HT 的时候可能会受到干扰,我们通过用户态的方式,当在线的资源使用开始变多的时候,离线大框就需要实时收缩,我们就做了一个快退避的策略。但是一旦在线资源使用开始收缩,这个时候离线需要通过慢启动的方式去解决这个问题,因为离线一旦快启动,这个时候因为 CPUrebalance 调度过慢,在线有可能还在那批 CPU 核上运行,势必会产生干扰,即使它的资源使用是在受限大框之内,它仍然在 CPU 微架构上会对在线造成干扰,我们通过慢启动的方式去避免这些干扰。同时我们在内核上也做了一些事情,即 HT 超线程干扰的规避,当在线进程在 HT 上运行,离线进程自动化迁移,避免对在线业务做干扰。同时假设在线与离线同时在 HT 核上运行,我们也通过其他的方式,比如说 L3-Cache 隔离的方式去避免在线业务的干扰。同时我们也引入了 CPI 干扰的方式,去对在线服务运行质量做检测,对在线业务检测出来之后,对离线资源干扰源做识别,并且形成一套避让的机制。以上主要是介绍一些精细化的管控策略。
2)保证离线运行良好:我们接下来讲一下怎么样去保证离线运行良好。这里面主要有两个部分的内容,第一个部分是我们在单机上做了更加精细的避让机制,另外一个我们在集群调度层面也做了一些更好优化。
首先单机层面上我们针对可压缩的资源尽量优先压缩,被 kill 往往比压缩好很多,离线有一些大数据的业务可能需要运行 2—3 小时,如果在即将完成之前被 kill 掉,它势必需要重算,如果通过压缩的方式可以缓解这种破坏的行为,同时对不可压缩的资源我们足量避让就可以了,不需要粗暴的全部杀掉。
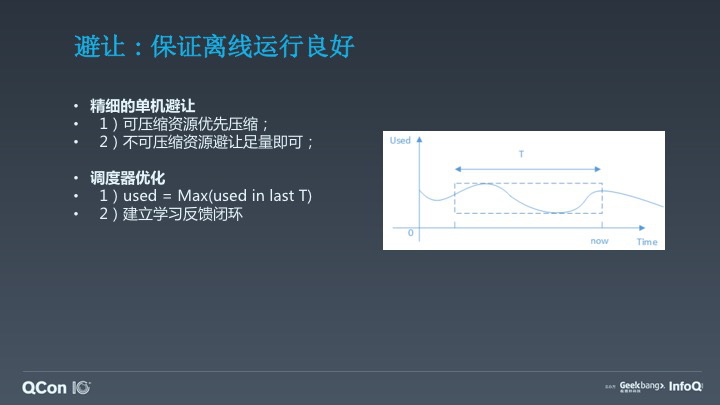
第二个层面我们通过调度优化的方式,这里面需要回答一个问题:如何学习一套超发的资源?刚才提到资源有优先级、有超发,怎么去学习一套稳定的超发曲线,保证离线不要一直被避让干扰。这里面有一个核心的内容,就是需要在线资源使用做画像,比如我们看一天的值,看两天的值,甚至看一周的值,最终学习一套稳定的曲线,使得在线资源超发能够趋于稳定,这样的情况下离线能够避免被杀。同时在这个基础上建立单机上资源隔离反馈的闭环,我们可以通过自动化学习的方式去建立更加优化的机制。
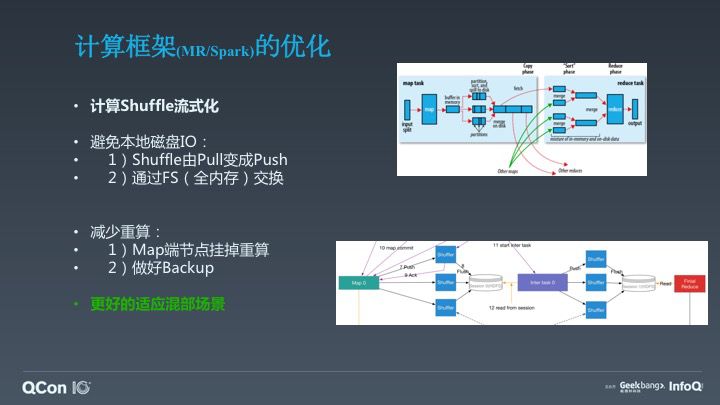
我们同时也对计算框架做了一些优化,比如计算 Shuffle 流式化。我们将可以做到两个优势点,第一个优势我们避免了本地磁盘 IO,因为 Shuffle 由 pull 变为 push,且通过 FS(全内存)交换,避免了 MapReduce 各种各样的磁盘行为。另外一个是减少了重算,它避免了 Map 端节点挂掉而导致任务重算,也做了 backup 的工作。当然,计算框架还做了很多其他的优化去更好适应我们的混部场景,这里就不一一列举了。
支撑系统建设
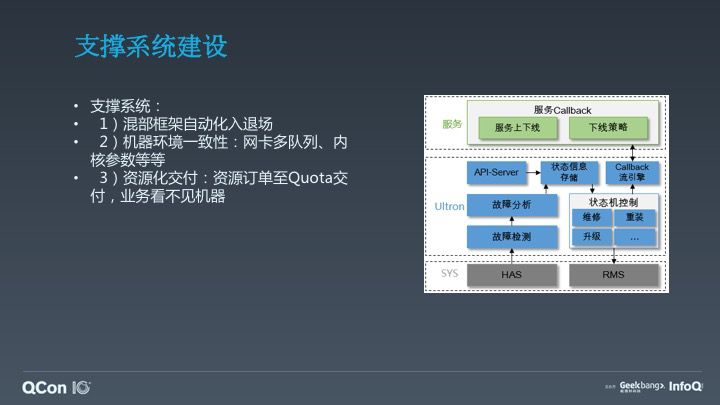
在混部实施过程中,其实需要大量基础性支持工作。
1)混部框架自动化入退场
2)机器环境一致性:网卡多队列、内核参数等等
3)资源化交付:资源订单至 Quota 交付,业务看不见机器
收益与未来展望
百度目前混部规模数十万台,它的混部集群 CPU 利用率比在线利用率提升 40%—80%。我们在 2016 年—2018 年实际节省数万台服务器的离线预算,这也是我们混部收益。
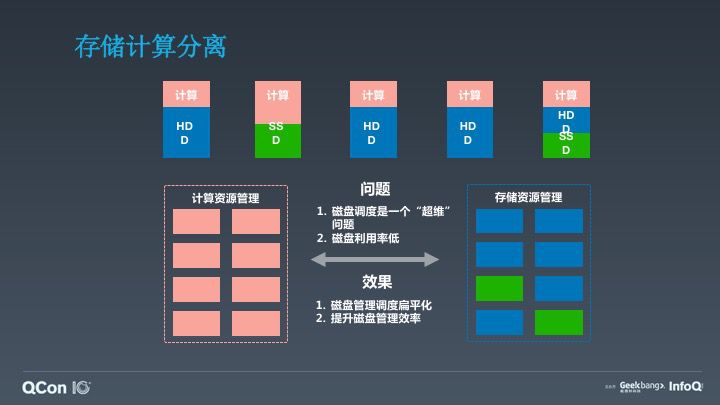
我们未来会做储存与计算分离,因为这里面一个比较大的问题,就是磁盘调度是”超维”调度,单纯的磁盘调度没有办法很好解决磁盘利用效率这个问题。所以现在百度正在将所有的储存磁盘资源统一至一套储存的 IaaS 系统托管,这样达到一个效果是能够对磁盘扁平化管理使得更快更容易去提升磁盘托管效率及利用率。
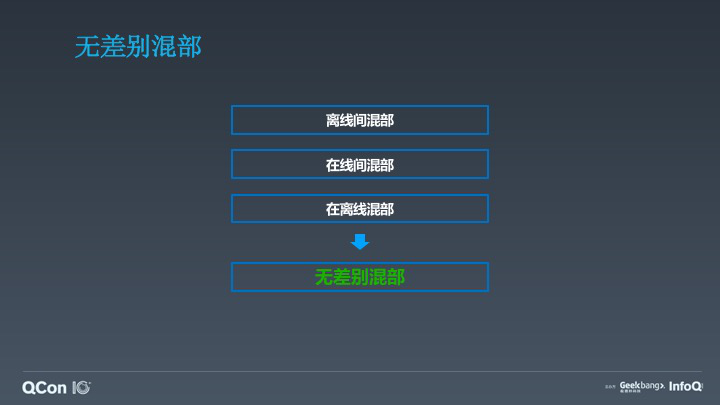
最后一点,我们想提出这样一个思路,就是无差别的混部,其实我们之前做了很多比如说离线混部,我们通过把离线计算框架全部混合在一起,同时在 2017 年的时候也开始启动在线混部,在线的合池,也做了在线的混部。那么我们怎么去做无差别的混部?这个事情很难,但是其实有几个思路,首先还是需要定义好资源的 SLA,比如说将它分为高优先级、低优先级,同时相对应有一套服务的 SLA 等级,一旦把这个事情做好以后,我们资源层面就能解释清楚对外提供的服务是什么样子的。另外一个还需要大量的一些基础服务的改造,比如说 MapReduce 和 Spark 目前都需要做一些预部署的工作,Spark 需要部署 NodeManager,MapReduce 需要部署 Shuffle,这些框架应该被改造以更加适合“云原生”。
今天主要给大家介绍到这里,总结一下刚才说的内容。首先是说明了百度做混部的背景。另外讲解了百度在混部架构上演进,以及它的历程,包括它的核心技术是什么样的,以及未来的展望。今天主要给大家介绍这么多,谢谢大家。
演讲嘉宾:张慕华,百度基础架构部资深研发工程师,毕业于天津大学取得计算机硕士学位。毕业后加入百度。先后参与或者负责 HHVM 虚拟机、分布式计算、分布式调度、在离线混部等多个产品或系统的研发工作。目前主要负责离线 PaaS 系统 Normandy、集群操作系统 Matrix、在离线混部系统千寻的技术和架构建设,专注于分布式架构、容器和调度等方向。