Linux 的 awk 命令相信不少人都用过,但是真正研究它的人应该不多。因为,我们多数人都是面向百度编程的。今天我们抽个时间,简单的来说一下它。
我随便谷歌了一下,就找到了两位大神的文章,相信不少人都认识。
我的文章也是以他们的为参考,并加入了一些内容。
awk 是处理文本文件的一个应用程序,几乎所有 Linux 系统都自带这个程序。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk 语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
- -F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
- -v var=value or --asign var=value
赋值一个用户定义变量。
- -f scripfile or --file scriptfile
从脚本文件中读取awk命令。
- -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
- -W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
- -W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。
- -W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。
- -W lint or --lint
打印不能向传统unix平台移植的结构的警告。
- W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。
- -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替^和^=;fflush无效。
-W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。
-W version or --version
打印bug报告信息的版本。
基本用法
我们以 xttblog.txt 文件内容为例。
2
this
is a test
3
Are
you like awk
5
www
.
xttblog
.
com
,业余草
This
'
s a test
10
There
are orange
,
apple
,
mongo
当执行 awk '{print $1,$4}' xttblog.txt 命令后,会出现一下内容。
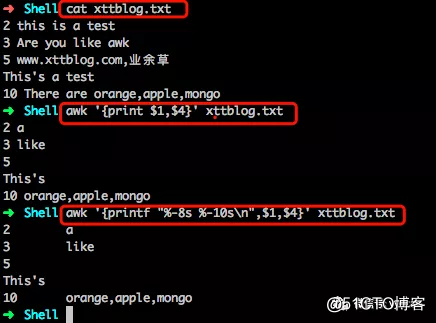
上面的例子是,每行按空格或TAB分割,输出文本中的1、4项。awk '{printf "%-8s %-10s\n",$1,$4}' xttblog.txt 是针对输出的内容进行格式化显示。
我们再看一个指定分隔符的例子:
awk -F #-F相当于内置变量FS, 指定分割字符
使用","分割。
$ awk
F
,
'{print $1,$2}'
xttblog
.
txt
2
this
is
a test
3
Are
you like awk
5
www
.
xttblog
.
com
业余草
This
's a test
10 There are orange apple
使用内置变量。
$ awk
'BEGIN{FS=","} {print $1,$2}'
xttblog
.
txt
2
this
is
a test
3
Are
you like awk
5
www
.
xttblog
.
com
业余草
This
's a test
10 There are orange apple
使用多个分隔符。先使用空格分割,然后对分割结果再使用","分割。
$ awk
F
'[ ,]'
'{print $1,$2,$5}'
xttblog
.
txt
2
this
test
3
Are
awk
5
www
.
xttblog
.
com
This
's a
10 There apple
下面再看一个设置变量的用法。设置变量我们使用 awk -v
$ awk
v a
1
'{print $1,$1+a}'
xttblog
.
txt
2
3
3
4
5
6
This
's 1
10 11
设置两个变量的例子。
$ awk
v a
1
-
v b
s
'{print $1,$1+a,$1b}'
xttblog
.
txt
2
3
2s
3
4
3s
5
6
5s
This
's 1 This'
ss
10
11
10s
awk 的强大之处还在于它之处 awk 脚本。
$ awk -f {awk脚本} {文件名}
同时还支持运算符。
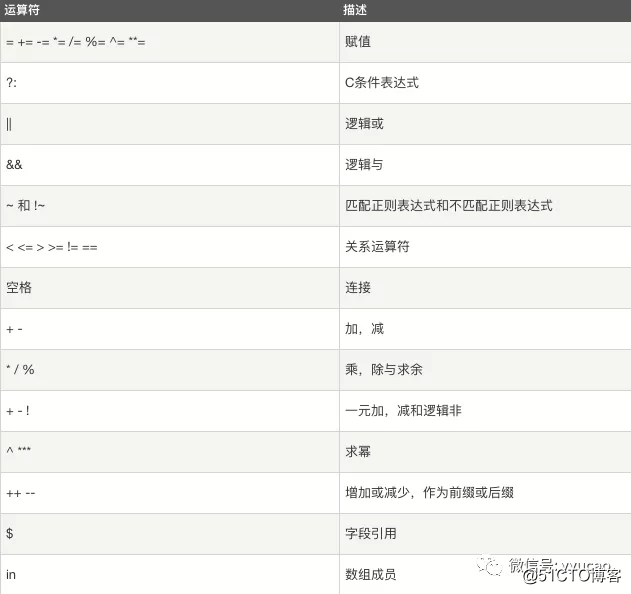
举例:过滤第一列大于 2 的行。
$ awk
'$1>2'
xttblog
.
txt
3
Are
you like awk
5
www
.
xttblog
.
com
,业余草
This
's a test
10 There are orange,apple,mongo
过滤第一列等于 2 的行。
$ awk
'$1==2 {print $1,$3}'
xttblog
.
txt
2
is
过滤第一列大于 2 并且第二列等于'Are'的行。
$ awk
'$1>2 && $2=="Are" {print $1,$2,$3}'
xttblog
.
txt
3
Are
you
awk 还支持内建变量。
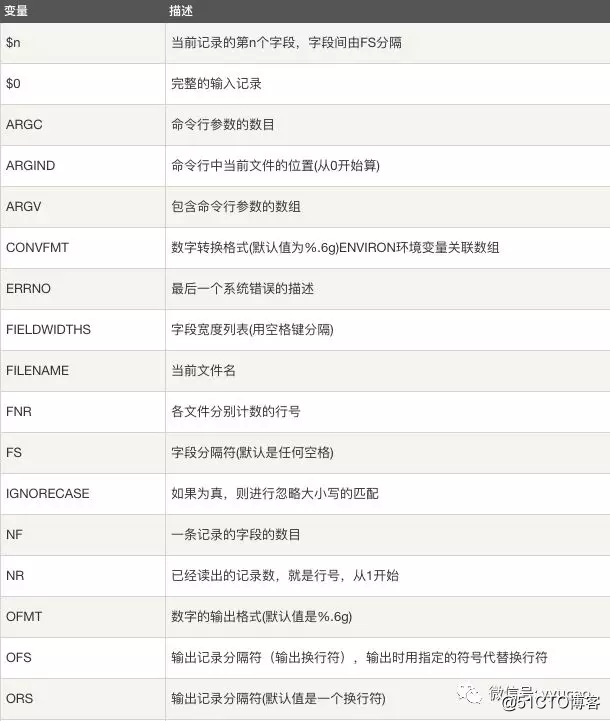

$ awk
'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}'
xttblog
.
txt
FILENAME ARGC FNR FS NF NR OFS ORS RS
xttblog
.
txt
2
1
5
1
xttblog
.
txt
2
2
5
2
xttblog
.
txt
2
3
2
3
xttblog
.
txt
2
4
3
4
xttblog
.
txt
2
5
4
5
输出顺序号 NR, 匹配文本行号。
$ awk
'{print NR,FNR,$1,$2,$3}'
xttblog
.
txt
1
1
2
this
is
2
2
3
Are
you
3
3
5
www
.
xttblog
.
com
,业余草
4
4
This
's a test
5 5 10 There are
指定输出分割符。
$ awk
'{print $1,$2,$5}'
OFS
" $ "
xttblog
.
txt
2
$
this
$ test
3
$
Are
$ awk
5
$ www
.
xttblog
.
com
,业余草
$
This
's $ a $
10 $ There $
awk 还支持正则,字符串匹配。
输出第二列包含 "th",并打印第二列与第四列。
$ awk
'$2 ~ /th/ {print $2,$4}'
xttblog
.
txt
this
a
上面的命令中,~ 表示模式开始。// 中是模式。
下面再看一个输出包含"," 的行。
$ awk
'/,/ '
xttblog
.
txt
5
www
.
xttblog
.
com
,业余草
10
There
are orange
,
apple
,
mongo
awk 忽略大小写。
$ awk
'BEGIN{IGNORECASE=1} /this/'
xttblog
.
txt
2
this
is
a test
awk 模式取反。
$ awk
'$2 !~ /th/ {print $2,$4}'
xttblog
.
txt
Are
like
www
.
xttblog
.
com
,业余草
a
There
orange
,
apple
,
mongo
$ awk
'!/th/ {print $2,$4}'
xttblog
.
txt
Are
like
www
.
xttblog
.
com
,业余草
a
There
orange
,
apple
,
mongo
awk 还支持 awk 脚本。脚本文件以 .awk 结尾。
awk 脚本有两个重要的关键词 BEGIN 和 END。
BEGIN{ 这里面放的是执行前的语句 }
END {这里面放的是处理完所有的行后要执行的语句 }
{这里面放的是处理每一行时要执行的语句
下面看一个简单的 xttblog.awk 脚本。
#!/bin/awk -f
#运行前
BEGIN
{
math =
0
english =
0
computer =
0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=
$3
english+=
$4
computer+=
$5
printf "%-6s %-6s %4d %8d %8d %8d\n"
,
$1
,
$2
,
$3
,
$4
,
$5
,
$3
+
$4
+
$5
}
#运行后
END
{
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n"
,
math
,
english
,
computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n"
,
math
/
NR
,
english
/
NR
,
computer
/
NR
}
这个脚本看起来代码比较多,我们看一个 hello world 脚本。
echo
|
awk
'{print "Hello,World!"}'
echo
|
awk
'BEGIN {print "Hello,World!"}'
awk
'BEGIN {print "Hello,World!"}'
echo
"hello world"
|
awk
'{print}'
awk 非常的强大,适合运维,Java 开发人员上手学习!建议大家收藏本文!