1.操作系统组织进程
1.1进程的定义
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。简而言之,一个进程就是一个正在执行程序的实例。
1.2进程标识符(PID)
它在linux被定义为:
pid_t pid;
它与散列表的连接的定义
/* PID/PID hash table linkage. */ struct pid_link pids[PIDTYPE_MAX]; struct list_head thread_group;
1.3进程之间的关系
一个进程只有一个父进程,,但可以有零个,一个或多个子进程。在Linux中,进程的父进程,子进程与拥有兄弟关系的进程定义如下
/* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->parent->pid) */ struct task_struct *real_parent; /* real parent process (when being debugged) */ struct task_struct *parent; /* parent process */ /* * children/sibling forms the list of my children plus the * tasks I'm ptracing. */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ struct task_struct *group_leader; /* threadgroup leader */
real_parent与parent的区别是,当real_parent没有时,进程会将parent当做自己的父进程。
2.进程状态转换
2.1进程状态定义
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
2.2进程状态分类及其赋值
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define __TASK_STOPPED 4 #define __TASK_TRACED 8 /* in tsk->exit_state */ #define EXIT_ZOMBIE 16 #define EXIT_DEAD 32 /* in tsk->state again */ #define TASK_DEAD 64 #define TASK_WAKEKILL 128
各个状态的定义:
·TASK_RUNNING:进程当前正在运行,或者正在运行队列中等待调度。
·TASK_INTERRUPTIBLE:进程处于睡眠状态,处于这个状态的进程因为等待某事件的发生(比如等待socket连接、等待信号量),而被挂起。
·TASK_UNINTERRUPTIBLE:不可中断的睡眠状态,此进程状态类似于 TASK_INTERRUPTIBLE,只是它不会处理信号。
·TASK_STOPPED:进程已中止执行,它没有运行,并且不能运行。
·TASK_TRACED:正被调试程序等其他进程监控时,进程将进入这种状态。
·EXIT_ZOMBIE:进程已终止,它正等待其父进程收集关于它的一些统计信息。
·EXIT_DEAD:最终状态(正如其名)。将进程从系统中删除时,它将进入此状态,因为其父进程已经通过 wait4() 或 waitpid() 调用收集了所有统计信息。
2.3进程状态转换
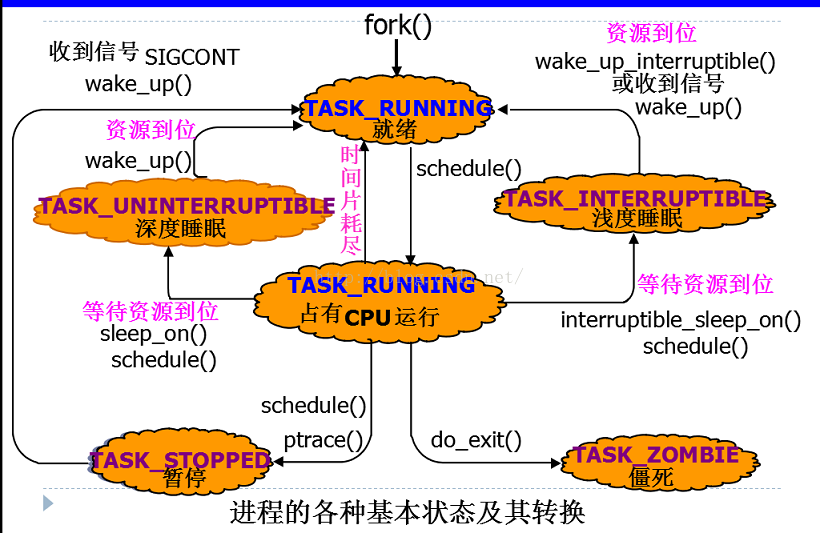
3.进程的调度
3.1调度的定义:
当计算机系统十多道程序设计系统时,通常就会有多个进程或线程同时竞争CPU。只要有两个或更多的进程处于就绪状态,这种情形就会发生。如果只有一个CPU可用,那么就必须选择下一个要运行的进程。在操作系统中,完成选择工作的这一部分称为调度程序,该程序使用的算法称为调度算法。
3.2Linux系统的两个调度算法
3.2.1LinuxO(1)调度器(O(1)scheduler)
这个调度器能够在常数时间内执行任务调度,例如从执行队列中选择一个任务或将一个任务加入执行队列,这与系统中的任务总数无关。
O(1)调度器优点:能够在常数时间内执行任务调度
O(1)调度器缺点:使用启发式方法来确定一个任务的交互性,会使该任务的优先级复杂且不完善,从而导致在处理交互任务时性能很糟糕。
3.2.2CFS(完全公平调度器)
它在Linux2.6.23版本中首次被集成到内核中
CFS的主要思想是使用一颗红黑树作为调度队列的数据结构。
CFS的调度算法总结:该算法总是优先调度那些使用CPU时间最少的任务,通常是在树中最左边节点上的任务。CFS会周期性地根据任务已经运行的时间,递增他的虚拟时间运行值,并将这个值与树中当前最左节点的值进行比较,如果正在运行的任务仍具有较小虚拟运行时间值,那么它将继续运行,否则,它将被插入红黑树的适当位置,并且CPU将执行新的最左边节点上的任务。
在Linux2.2.26中进程的可调度实体的定义如下:
/* * CFS stats for a schedulable entity (task, task-group etc) * * Current field usage histogram: * * 4 se->block_start * 4 se->run_node * 4 se->sleep_start * 6 se->load.weight */ struct sched_entity { struct load_weight load; /* for load-balancing */ struct rb_node run_node; struct list_head group_node; unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime; u64 last_wakeup; u64 avg_overlap; #ifdef CONFIG_SCHEDSTATS u64 wait_start; u64 wait_max; u64 wait_count; u64 wait_sum; u64 sleep_start; u64 sleep_max; s64 sum_sleep_runtime; u64 block_start; u64 block_max; u64 exec_max; u64 slice_max; u64 nr_migrations; u64 nr_migrations_cold; u64 nr_failed_migrations_affine; u64 nr_failed_migrations_running; u64 nr_failed_migrations_hot; u64 nr_forced_migrations; u64 nr_forced2_migrations; u64 nr_wakeups; u64 nr_wakeups_sync; u64 nr_wakeups_migrate; u64 nr_wakeups_local; u64 nr_wakeups_remote; u64 nr_wakeups_affine; u64 nr_wakeups_affine_attempts; u64 nr_wakeups_passive; u64 nr_wakeups_idle; #endif #ifdef CONFIG_FAIR_GROUP_SCHED struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q; #endif };
其中,定义了任务在CPU上运行的时间长短vruntime(虚拟运行时间),在红黑树中,树中的每个内部节点对应于一个任务,左侧的子节点对应于CPU上运行时间更少的任务,右侧的子节点是那些迄今消耗CPU时间较多的任务。而在Linux中,vruntime的计算公式为:
vruntime=实际运行时间*1024/进程权重=(调度周期*进程权重/所有进程权重)*1024/进程权重=调度周期*1024/所有进程总权重
因此我们可以得出,虽然进程的权重不同,但是他们的vruntime增长速度应该是一样的,与权重无关,这样我们就可以通过vruntime更为公平地选择下一个运行的进程。
以下是主动调度代码schedule
/* * schedule() is the main scheduler function. */ asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: preempt_disable(); cpu = smp_processor_id(); rq = cpu_rq(cpu); rcu_qsctr_inc(cpu); prev = rq->curr; switch_count = &prev->nivcsw; release_kernel_lock(prev); need_resched_nonpreemptible: schedule_debug(prev); hrtick_clear(rq); /* * Do the rq-clock update outside the rq lock: */ local_irq_disable(); update_rq_clock(rq); spin_lock(&rq->lock); clear_tsk_need_resched(prev); if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) prev->state = TASK_RUNNING; else deactivate_task(rq, prev, 1); switch_count = &prev->nvcsw; } #ifdef CONFIG_SMP if (prev->sched_class->pre_schedule) prev->sched_class->pre_schedule(rq, prev); #endif if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); prev->sched_class->put_prev_task(rq, prev); next = pick_next_task(rq, prev); if (likely(prev != next)) { sched_info_switch(prev, next); rq->nr_switches++; rq->curr = next; ++*switch_count; context_switch(rq, prev, next); /* unlocks the rq */ /* * the context switch might have flipped the stack from under * us, hence refresh the local variables. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else spin_unlock_irq(&rq->lock); hrtick_set(rq); if (unlikely(reacquire_kernel_lock(current) < 0)) goto need_resched_nonpreemptible; preempt_enable_no_resched(); if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) goto need_resched; }
其中的重点是pick_next_task函数
/* * Pick up the highest-prio task: */ static inline struct task_struct * pick_next_task(struct rq *rq, struct task_struct *prev) { const struct sched_class *class; struct task_struct *p; /* * Optimization: we know that if all tasks are in * the fair class we can call that function directly: */ if (likely(rq->nr_running == rq->cfs.nr_running)) { p = fair_sched_class.pick_next_task(rq); if (likely(p)) return p; } class = sched_class_highest; for ( ; ; ) { p = class->pick_next_task(rq); if (p) return p; /* * Will never be NULL as the idle class always * returns a non-NULL p: */ class = class->next; } }
4.自己对操作系统进程模型的看法
在一个操作系统中,各个进程的存在以及相应的活动非常复杂繁多,各个进程之间也存在很多的关系,在我看来,目前的进程模型已经做得很好了,能够保证现在我们所使用的系统的负载水平。