框架
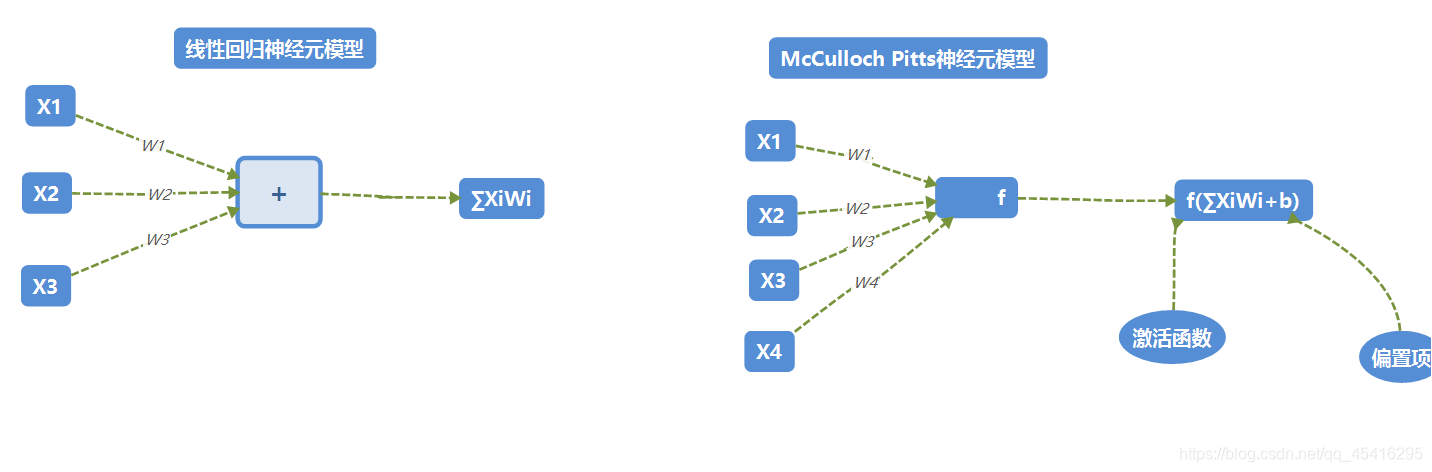
激活函数
- relu
- 函数表达式:
f(x)=max(x,0)={0,x<=0x,x>=0
- 函数调用:
tf.nn.relu()
- sigmoid
- 函数表达式:
f(x)=1+e−x1
- 函数调用:
tf.nn.sigmoid()
- tanh
- 函数表达式:
f(x)=1+e−2x1−e−2x
- 函数调用:
tf.nn.tanh()
NN复杂度
- 多用NN层数和NN参数的个数表示
- 层数:隐藏层层数+1个输出层
- 总参数:总W+总b
神经网络优化
- 损失函数(loss):预测值(y)与已知值(y_)的差距
- NN优化目标:loss最小
- 均方误差mse:
MSE(y_,y)=n∑i=1n(y−y_)2
函数调用:loss_mse=tf.reduce_mean(tf.square(y_-y))
- 自定义(商品预测)
loss(y_,y)=n∑f(y_,y)
即:
f(y_,y)={PROFIT∗(y_−y),y<y_,损失利润COST∗(y−y_),y>y_,损失成本
函数调用:
loss=tf.reduce_sum(tf.where(tf.greater(y,y_),COST(y-y_),PROFIT(y_-y)))
- ce(交叉熵)
- 表征两个概率分布之间 的距离
H(y_,y)=−∑y_∗logy
- 函数调用:
ce=tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-12,1.0)))
引入:softmax()函数
- 当n分类的n个输出(y1,y2,…yn)通过softmax()函数,满足概率分布要求:
-
∀x,P(X=x)∈[0,1]andx∑p(X=x)=1
-
softmmax(yi)=∑j=1neyieyi
- 函数调用:
ce=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem=tf.reduce_mean(ce)
