复制操作步骤
准备两个集群,clusterA,clusterB .
两个集群都建表 create table PERSON (id integer not null primary key,name varchar,age integer, sex INTEGER, val DOUBLE) compression = ‘snappy’, UPDATE_CACHE_FREQUENCY=30000, COLUMN_ENCODED_BYTES=0;
主集群添加复制相关配置
<property>
<name>hbase.replication</name>
<value>true</value>
<description> 打开replication功能</description>
</property>
<property>
<name>replication.source.nb.capacity</name>
<value>10</value>
<description> 主集群每次像备集群发送的entry最大的个数,推荐5000.可根据集群规模做出适当调整,slave集群服务器如果较多,可适当增大</description>
</property>
<property>
<name>replication.source.size.capacity</name>
<value>1</value>
<description> 主集群每次像备集群发送的entry的包的最大值大小,不推荐过大</description>
</property>
<property>
<name>replication.source.ratio</name>
<value>1</value>
<description> 主集群里使用slave服务器的百分比</description>
</property>
<property>
<name>hbase.regionserver.wal.enablecompression</name>
<value>false</value>
<description> 主集群关闭hlog的压缩</description>
</property>
<property>
<name> replication.sleep.before.failover</name>
<value>5000</value>
<description> 主集群在regionserver当机后几毫秒开始执行failover</description>
</property>
备集群添加复制相关配置
<property>
<name>hbase.replication</name>
<value>true</value>
<description> 打开replication功能</description>
</property>
将主集群列族标识为可复制
hbase(main):007:0> alter 'PERSON',{NAME=>'0',REPLICATION_SCOPE=>'1'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.6841 seconds
hbase(main):008:0> !describe 'PERSON'
Table PERSON is ENABLED
PERSON, {TABLE_ATTRIBUTES => {coprocessor$1 => '|org.apache.phoenix.coprocessor.ScanRegionObserver|805306366|', coprocessor$2 => '|org.apache.phoenix.coprocessor.UngroupedAggregateRegionObserver|805306366|', coprocessor$3 => '|org.apache.phoenix.coprocessor.GroupedAggre
gateRegionObserver|805306366|', coprocessor$4 => '|org.apache.phoenix.coprocessor.ServerCachingEndpointImpl|805306366|', coprocessor$5 => '|org.apache.phoenix.hbase.index.Indexer|805306366|index.builder=org.apache.phoenix.index.PhoenixIndexBuilder,org.apache.hadoop.hbas
e.index.codec.class=org.apache.phoenix.index.PhoenixIndexCodec'}
COLUMN FAMILIES DESCRIPTION
{NAME => '0', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'FAST_DIFF', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '1', BLOOMFIL
TER => 'NONE', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
1 row(s)
Took 0.0610 seconds
=> true
执行命令add_peer '1', CLUSTER_KEY => "192.168.229.105:2181:/hbase"创建peer。
hbase(main):011:0> add_peer '1', CLUSTER_KEY => "192.168.229.105:2181:/hbase"
Took 1.5124 seconds
hbase(main):012:0> list_peers
PEER_ID CLUSTER_KEY ENDPOINT_CLASSNAME STATE REPLICATE_ALL NAMESPACES TABLE_CFS BANDWIDTH SERIAL
1 192.168.229.105:2181:/hbase ENABLED true 0 false
1 row(s)
Took 0.0630 seconds
=> #<Java::JavaUtil::ArrayList:0x1ff463bb>
创建后,观察主集群的ZK变化:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ErXlfrWt-1572431331494)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/b225b2272a11de122fdaaf32a35054d2/image.png)]](https://img-blog.csdnimg.cn/20191030183002422.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
ZK上新建/hbase/replication目录,该目录存储复制相关内容。
peers记录了复制方向,从集群信息,复制的表及列族信息,及slave的复制状态。rs节点管理所有的regionServer。rs/node4,16020,1572256020528/1这里的1是复制peer ID,其下挂载hlog队列和position信息(复制进度)。
此时主集群写入数据,备集群就会同步过去了。
接下来看一下add_peer的帮助文档:
hbase(main):002:0> help "add_peer"
A peer can either be another HBase cluster or a custom replication endpoint. In either case an id
must be specified to identify the peer.
For a HBase cluster peer, a cluster key must be provided and is composed like this:
hbase.zookeeper.quorum:hbase.zookeeper.property.clientPort:zookeeper.znode.parent
This gives a full path for HBase to connect to another HBase cluster.
An optional parameter for state identifies the replication peer's state is enabled or disabled.
And the default state is enabled.
An optional parameter for namespaces identifies which namespace's tables will be replicated
to the peer cluster.
An optional parameter for table column families identifies which tables and/or column families
will be replicated to the peer cluster.
An optional parameter for serial flag identifies whether or not the replication peer is a serial
replication peer. The default serial flag is false.
Notice: Set a namespace in the peer config means that all tables in this namespace
will be replicated to the peer cluster. So if you already have set a namespace in peer config,
then you can't set this namespace's tables in the peer config again.
Examples:
hbase> add_peer '1', CLUSTER_KEY => "server1.cie.com:2181:/hbase"
hbase> add_peer '1', CLUSTER_KEY => "server1.cie.com:2181:/hbase", STATE => "ENABLED"
hbase> add_peer '1', CLUSTER_KEY => "server1.cie.com:2181:/hbase", STATE => "DISABLED"
hbase> add_peer '2', CLUSTER_KEY => "zk1,zk2,zk3:2182:/hbase-prod",
TABLE_CFS => { "table1" => [], "table2" => ["cf1"], "table3" => ["cf1", "cf2"] }
hbase> add_peer '2', CLUSTER_KEY => "zk1,zk2,zk3:2182:/hbase-prod",
NAMESPACES => ["ns1", "ns2", "ns3"]
hbase> add_peer '2', CLUSTER_KEY => "zk1,zk2,zk3:2182:/hbase-prod",
NAMESPACES => ["ns1", "ns2"], TABLE_CFS => { "ns3:table1" => [], "ns3:table2" => ["cf1"] }
hbase> add_peer '3', CLUSTER_KEY => "zk1,zk2,zk3:2182:/hbase-prod",
NAMESPACES => ["ns1", "ns2", "ns3"], SERIAL => true
For a custom replication endpoint, the ENDPOINT_CLASSNAME can be provided. Two optional arguments
are DATA and CONFIG which can be specified to set different either the peer_data or configuration
for the custom replication endpoint. Table column families is optional and can be specified with
the key TABLE_CFS.
hbase> add_peer '6', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint'
hbase> add_peer '7', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint',
DATA => { "key1" => 1 }
hbase> add_peer '8', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint',
CONFIG => { "config1" => "value1", "config2" => "value2" }
hbase> add_peer '9', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint',
DATA => { "key1" => 1 }, CONFIG => { "config1" => "value1", "config2" => "value2" },
hbase> add_peer '10', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint',
TABLE_CFS => { "table1" => [], "ns2:table2" => ["cf1"], "ns3:table3" => ["cf1", "cf2"] }
hbase> add_peer '11', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint',
DATA => { "key1" => 1 }, CONFIG => { "config1" => "value1", "config2" => "value2" },
TABLE_CFS => { "table1" => [], "ns2:table2" => ["cf1"], "ns3:table3" => ["cf1", "cf2"] }
hbase> add_peer '12', ENDPOINT_CLASSNAME => 'org.apache.hadoop.hbase.MyReplicationEndpoint',
CLUSTER_KEY => "server2.cie.com:2181:/hbase"
Note: Either CLUSTER_KEY or ENDPOINT_CLASSNAME must be specified. If ENDPOINT_CLASSNAME is specified, CLUSTER_KEY is
optional and should only be specified if a particular custom endpoint requires it.
如果想要实现串行复制,只需要添加SERIAL => true即可。有关串行复制后面会讲。
复制原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G6D1InGQ-1572431331495)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/1bd925f389dbf24f178b9ee8716cc822/image.png)]](https://img-blog.csdnimg.cn/20191030183009302.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
- 日志滚动
有监听器监听日志的滚动操作。日志滚动roll后,新的日志信息会备记录在walGroup,采用串行复制保证数据的一致性,等老的日志复制完成后,新日志才开始复制。
- rs宕机
当某台宕机后,其他rs会去其节点下抢注lock节点,竞争锁成功的RS会接管hlog日志的处理。由于在zk中记录了peer的元数据信息以及消费进度position信息,所以可以继续之前的复制进度继续复制。
- 日志归档
正常情况下,超过TTL时间的日志会被删除。清理线程会扫描复制队列,正在复制的数据不会被删除,即使peer是disable的。(这里待验证)
- 循环复制
The region server reads the edits sequentially and separates them into buffers, one buffer per table. After all edits are read, each buffer is flushed using Table, HBase’s normal client. The master’s UUID and the UUIDs of slaves which have already consumed the data are preserved in the edits they are applied, in order to prevent replication loops.
这里采用的是集群UUID的方式来实现的。写入WAL的数据中包含UUID,在复制时,判断UUID与自身集群的UUID是否一致,如果不一致则过滤掉不复制。
串行复制
问题描述
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C3mDgFO6-1572431331496)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/3237a99ca967f6a25d3e08a9264d4ccc/image.png)]](https://img-blog.csdnimg.cn/20191030183019574.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
影响因素:region迁移与Major compaction
如上图所示这种极端情况下,还会导致主备集群数据的不一致。比如RegionServer1上最后一个未同步的写入操作是Put,而RegionA被移动到RegionServer2上的第一个写入操作是Delete,在主集群上其写入顺序是先Put后Delete,如果RegionServer2上的Delete操作先被复制到了备集群,然后备集群做了一次Major compaction,其会删除掉这个Delete marker,然后Put操作才被同步到了备集群,因为Delete已经被Major compact掉了,这个Put将永远无法被删除,所以备集群的数据将会比主集群多。
解决方法
解决这个问题的关键在于需要确保RegionServer2上的新写入操作必须在RegionServer1上的写入操作复制完成之后再进行复制。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MiHvt6Nu-1572431331498)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/f0186b824910b95b680d61b74e39bc6a/image.png)]](https://img-blog.csdnimg.cn/20191030183025387.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
- Barrier列表
- lastPushedSequenceId
Pending的写入记录就需要等待lastPushedSequenceId推到Barrier2之后才能开始复制。由于每个区间之间只会有一个RegionServer来负责复制,所以只有和lastPushedSequenceId在同一个区间内的RegionServer才能进行复制,并在复制成功后不断更新lastPushedSequenceId,而在lastPushedSequenceId之后各个区间的RegionServer则需要等待lastPushedSequenceId被推到自己区间的起始Barrier,然后才能开始复制,从而确保了Region的写入操作可以严格按照主集群的写入顺序串行的复制到备集群。
源码分析
而在HRegionServer中有Replication的两个重要引用,这两个handler负责执行复制工作,如果配置了复制,HRegionServer在启动时,会启动ReplicationService(ReplicationSourceService 和ReplicationSinkService )
// Replication services. If no replication, this handler will be null.
protected ReplicationSourceService replicationSourceHandler;
protected ReplicationSinkService replicationSinkHandler;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zeUYcgkq-1572431331500)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/9e5e35d481a1af83ff95eb7ecc15200f/image.png)]](https://img-blog.csdnimg.cn/2019103018303218.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
org.apache.hadoop.hbase.replication.regionserver.Replication类是复制的核心类,类图:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s3RmgPO6-1572431331501)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/f55cbe563121e838f91a48c5fc89f966/image.png)]](https://img-blog.csdnimg.cn/20191030183035240.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
Replication类的关键属性:
private ReplicationSourceManager replicationManager;
private ReplicationQueueStorage queueStorage;
private ReplicationPeers replicationPeers;
private ReplicationTracker replicationTracker;
private Configuration conf;
private ReplicationSink replicationSink;
// Hosting server
private Server server;
/** Statistics thread schedule pool */
private ScheduledExecutorService scheduleThreadPool;
private int statsThreadPeriod;
// ReplicationLoad to access replication metrics
private ReplicationLoad replicationLoad;
private PeerProcedureHandler peerProcedureHandler;
ReplicationSourceWALReader
ReplicationSourceWALReader是读取WAL日志文件的核心,将读取到的数据封装成entry放到队列中等待消费。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5RMKPJJP-1572431331502)(http://git.caimi-inc.com/middleware/hbase2.0/uploads/8b51770a0be05670cceafa9ccc968c58/image.png)]](https://img-blog.csdnimg.cn/20191030183044342.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9pdDAwNy5ibG9nLmNzZG4ubmV0,size_16,color_FFFFFF,t_70)
一个entrybatch有多少数据?
依赖于下面两个字段的值:
// max (heap) size of each batch - multiply by number of batches in queue to get total
private final long replicationBatchSizeCapacity;
// max count of each batch - multiply by number of batches in queue to get total
private final int replicationBatchCountCapacity;
复制时,会一直读取,直到达到条数或者大小的限制, 或者到大文件末尾:
// returns true if we reach the size limit for batch, i.e, we need to finish the batch and return.
protected final boolean addEntryToBatch(WALEntryBatch batch, Entry entry) {
WALEdit edit = entry.getEdit();
if (edit == null || edit.isEmpty()) {
return false;
}
long entrySize = getEntrySizeIncludeBulkLoad(entry);
long entrySizeExcludeBulkLoad = getEntrySizeExcludeBulkLoad(entry);
batch.addEntry(entry);
updateBatchStats(batch, entry, entrySize);
boolean totalBufferTooLarge = acquireBufferQuota(entrySizeExcludeBulkLoad);
// Stop if too many entries or too big **
return totalBufferTooLarge || batch.getHeapSize() >= replicationBatchSizeCapacity ||
batch.getNbEntries() >= replicationBatchCountCapacity;
}
delete
在entry.WALEdit.Cell中有记录是PUT还是DELETE
删除某个列族时:
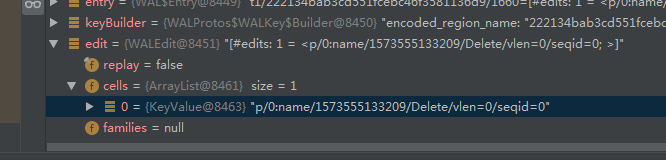
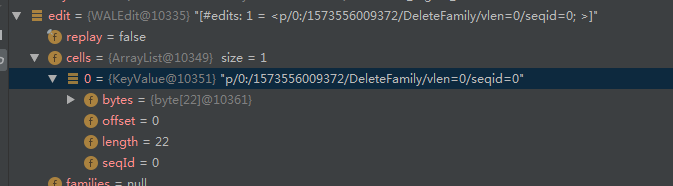
删除一行时,wal日志文件中该行的所有列族都会体现出来:

主从集群时间戳一致
这里是通过在复制时,主集群读WAL时一起读出时间戳,然后将其传到从集群,从集群put数据时,会将该时间戳作为数据的时机生产时间戳写入。
到底有几个walgroup
在hbase2.X中,一个RS服务支持多wal,即walgroup。通过配置=来开启这个功能。 那么具体是几个呢?实际是通过org.apache.hadoop.hbase.wal.BoundedGroupingStrategy#NUM_REGION_GROUPS的配置值来决定的,默认是org.apache.hadoop.hbase.wal.BoundedGroupingStrategy#DEFAULT_NUM_REGION_GROUPS=2。 walgroup的格式为:providerId.regiongroup-0;providerId.regiongroup-1.

那么我们在扫描日志时,需要扫描RS服务有几个regiongroup-结尾的wal日志即可。 具体walgroup实现原理参见
hbase是如何实现类似于Linux的tail -f增量读取数据的?

上面代码中,是一个while循环,直到日志切换。由于一个wal日志的写入是耗时的,所以这里在消费的时候,读取wal文件到结尾后,需要再次进入while文件,从上次记录的位置(currentPosition)继续读取。
它最终调用的是org.apache.hadoop.fs.FSDataInputStream#seek方法,来跳转到指定的位置offset进行读取。这个offset就是wal日志文件中的position。
[root@node2 bin]# ./hbase wal -j -p -g 1802 wal日志路径这个命令的实现也是如此,使用-g参数跳转到指定position开始读取,其内部也是调用的FSDataInputStream#seek方法。
hadoop权威指南中说FSDataInputStream用法:该类尽量少用,尽量用流数据来构建数据的访问模式(如:mapreduce),而非大量的seek();,但是hbase确实这样用了。
日志滚动
有监听器监听日志的滚动操作。日志滚动roll后,新的日志信息会备记录在walGroup,采用串行复制保证数据的一致性,等老的日志复制完成后,新日志才开始复制。

rs宕机
当某台宕机后,其他rs会去其节点下抢注lock节点,竞争锁成功的RS会接管hlog日志的处理。由于在zk中记录了peer的元数据信息以及消费进度position信息,所以可以继续之前的复制进度继续复制。
日志归档
正常情况下,超过TTL时间的日志会被删除。清理线程会扫描复制队列,正在复制的数据不会被删除,即使peer是disable的。(这里待验证)
循环复制
The region server reads the edits sequentially and separates them into buffers, one buffer per table. After all edits are read, each buffer is flushed using Table, HBase’s normal client. The master’s UUID and the UUIDs of slaves which have already consumed the data are preserved in the edits they are applied, in order to prevent replication loops. 这里采用的是集群UUID的方式来实现的。写入WAL的数据中包含UUID,在复制时,判断UUID与自身集群的UUID是否一致,如果不一致则过滤掉不复制。
集群中会记录主从的clusterID:
public class ClusterMarkingEntryFilter implements WALEntryFilter {
privateUUID clusterId; //主的 ClusterId
private UUID peerClusterId;//从机器的ClusterId
private ReplicationEndpoint replicationEndpoint;
在ReplicationSource中也有,并且打印了复制方向:

在org.apache.hadoop.hbase.replication.ClusterMarkingEntryFilter#filter中,会将clusterID封装进WALKeyImpl,一起通过PB协议传到从集群。
从集群在收到复制数据写入WAL时,会将peerclusterID一起写入,具体存储在org.apache.hadoop.hbase.wal.WALKeyImpl#clusterIds中。
如此一来,在读取EAL日志时,过滤器中就可以很方便的通过cluster过滤了。 org.apache.hadoop.hbase.replication.ClusterMarkingEntryFilter#filter中关键代码:

串行复制
串行复制实现类是SerialReplicationSourceWALReader,他继承了ReplicationSourceWALReader。
SerialReplicationSourceWALReader中读取walentry的实现在org.apache.hadoop.hbase.replication.regionserver.SerialReplicationSourceWALReader#readWALEntries。与ReplicationSourceWALReader类似,主要做几件事:
- 检查当前路径是否可用
- 创建WALEntryBatch
- entryStream.peek()读取entry(这里不删除,在添加到WALEntryBatch后才将其删除)
- 过滤
- 校验是否可以推送到peer端
- 如果可以推送,则记录LastSeqId并且将entry真正删除。
这里看一个核心的实现,校验当前range是否复制完成org.apache.hadoop.hbase.replication.regionserver.SerialReplicationChecker#isRangeFinished:
private boolean isRangeFinished(long endBarrier, String encodedRegionName) throws IOException {
long pushedSeqId;
try {
pushedSeqId = storage.getLastSequenceId(encodedRegionName, peerId);
} catch (ReplicationException e) {
throw new IOException(
"Failed to get pushed sequence id for " + encodedRegionName + ", peer " + peerId, e);
}
// endBarrier is the open sequence number. When opening a region, the open sequence number will
// be set to the old max sequence id plus one, so here we need to minus one.
// endBarrier是打开的序列号。 打开区域时,打开的序列号将设置为旧的最大序列ID加1,因此这里我们需要减去1。
return pushedSeqId >= endBarrier - 1;
}
这里我已经验证,sequenceID是与region绑定的,他会一直递增,即使region发生迁移,RS集群重启等。region split后,生成新的region,sequenceID从1开始。
这里的barrier是存储在hbase:meta表中的: 在region打开,split,merge时,都会更新表中的数据。
将region 94f40784130a856032e0fa2283b322e5进行split:

将d68f5ade2d117eb1d3a4941fe8abcaf2和e847a881cfb28a341d97b761b19de573进行merge:

注意:
- 这里只有将表的REPLICATION_SCOPE属性设置为1,也就是开启了复制(可以不设置peer),才会有rep_barrier:seqnumDuringOpen及rep_barrier:parent。
- 如果不设置REPLICATION_SCOPE=1,hbase:meta中的老的region记录会被删除,也就是无法获取region的父子关系,他们的先后顺序。反之,老的数据会一直保留这两个关键信息:seqnumDuringOpen和parent
我们看一下hbase replication如何判断是否可以复制的。
总结一下,它校验了以下几个内容:
- 开启串行复制之前,首个barrier前的数据,允许push
- 如果当前region有parent,则需要等待parent复制完成
- 如果当前region状态是OPENING状态,并且处于最后一个range时,这时push是不安全的,即使上一个range是finished状态的
- 通过上述校验则允许复制
源码在org.apache.hadoop.hbase.replication.regionserver.SerialReplicationChecker#canPush(org.apache.hadoop.hbase.wal.WAL.Entry, byte[]):
private boolean canPush(Entry entry, byte[] row) throws IOException {
String encodedNameAsString = Bytes.toString(entry.getKey().getEncodedRegionName());
long seqId = entry.getKey().getSequenceId(); // 当前要复制的entry的SequenceId,如果可以复制,则复制完成后,它就是last sequence id
ReplicationBarrierResult barrierResult = MetaTableAccessor.getReplicationBarrierResult(conn,
entry.getKey().getTableName(), row, entry.getKey().getEncodedRegionName());
LOG.info("Replication barrier for {}: {}", entry, barrierResult);
long[] barriers = barrierResult.getBarriers();
int index = Arrays.binarySearch(barriers, seqId);
if (index == -1) {
LOG.debug("{} is before the first barrier, pass", entry);
// This means we are in the range before the first record openSeqNum, this usually because the
// wal is written before we enable serial replication for this table, just return true since
// we can not guarantee the order.
// 开启串行复制之前,首个barrier前的数据,允许push
pushed.getUnchecked(encodedNameAsString).setValue(seqId);
return true;
}
// The sequence id range is left closed and right open, so either we decrease the missed insert
// point to make the index start from 0, or increase the hit insert point to make the index
// start from 1. Here we choose the latter one.
// sequence id 是左闭右开的,这里确保index从1开始
if (index < 0) {
index = -index - 1;
} else {
index++;
}
if (index == 1) {
// we are in the first range, check whether we have parents
// 走到这里说明是region的第一个range复制区间,检查有没有parent,如果有,则需要等待parent复制完成
for (byte[] regionName : barrierResult.getParentRegionNames()) {
if (!isParentFinished(regionName)) {
LOG.debug("Parent {} has not been finished yet for entry {}, give up",
Bytes.toStringBinary(regionName), entry);
return false;
}
}
// 在将open sequence number写入hbase:meta表之前,我们会写入a open region marker到wal文件中,
//所以当region的状态是OPENING 状态,并且是处于最后一个range时,这时push是不安全的,即使上一个range是finished状态的
if (isLastRangeAndOpening(barrierResult, index)) {
LOG.debug("{} is in the last range and the region is opening, give up", entry);
return false;
}
LOG.debug("{} is in the first range, pass", entry);
recordCanPush(encodedNameAsString, seqId, barriers, 1);
return true;
}
// check whether the previous range is finished
// 检查上一个range是否已经完成
if (!isRangeFinished(barriers[index - 1], encodedNameAsString)) {
LOG.debug("Previous range for {} has not been finished yet, give up", entry);
return false;
}
if (isLastRangeAndOpening(barrierResult, index)) {
LOG.debug("{} is in the last range and the region is opening, give up", entry);
return false;
}
LOG.debug("The previous range for {} has been finished, pass", entry);
recordCanPush(encodedNameAsString, seqId, barriers, index);
return true;
}
hbase开启debug日志
编辑hbase-daemon.sh,搜索INFO,改为DEBUG即可。 hbase本身还有一些trace级别的日志,用于调试追踪,我们只需要将log级别改为trace级别即可。
