本文为课程对应的学习笔记
- 地址http://www.auto-mooc.com/mooc/detail?mooc_id=F51511B0209FB73D81EAC260B63B2A21
课件资料存放地址:待更新
文章目录
ML系统结构与实现方法

机器学习是人工智能的方法,使用数据进行学习和预测。
传统的学习方法:KNN,决策树,SVM
深度学习是机器学习的方法,是传统方法的延伸和创新






1.0【传统】最近邻居法KNN-最简单ML

- 根据距离函数计算待分类样本X和每个训练样本的距离(判断依据),选择与待分
类样本距离最小的K个样本作为X的K个最近邻居,最后以这K个邻居中的最多的邻
居所属的种类作为X的类别
KNN 算法中,所选择的邻居都是已经正确分类的对象。相比于其他算法,**其时间复杂度和空间复杂度都很高,**但具有精度高、对异常值不敏感、无输入数据假定的优点。
简单一句话:物以类聚!
import matplotlib.pyplot as plt #这一句引用matplotlib.pyplot,并且as为一个更简单的名#字plt,可以在后面的调用中更方便
fig = plt.figure() #生成一个figure对象,就相当于图形的底板,还可以通过参数指定图形的大小
ax = fig.add_subplot(111) #111的意思,我们可以通过改变它的值来看一下
type1 = ax.scatter([1,2], [2,1], s=20, c='red') #接下来是准备点;第一类
type2 = ax.scatter([10,11], [11,10],s=30, c='green') #第二类的点
new = ax.scatter([9],[9],s=20,marker='x',c='blue') #除了两类之外的点;也就是我们需要对它进行分类的点
#ax.legend([type1, type2], [1,2],loc=2)
#ax.axis([-5000,100000,-2,25])
plt.xlabel('X axis') #可以对横轴和纵轴添加标记
plt.ylabel('Y axis')
plt.show()

1.1 核心算法
import operator
from numpy import *
training_set = array([[0,1],[1,0],[10,11],[11,10]])
test_set = [9,9]
labels = ['A','A','B','B']
#计算目标点和训练点之间的欧氏距离
def euclid_distance(x1, x2, dim):
#计算所有目标点和所有训练点之间的距离,并选出K个最近邻
def getNeighbors(training_set, test_set, k):
#对k个近邻进行合并,返回value最大的key
def get_label(index):
index = getNeighbors(training_set,test_set,3)
get_label(index)
1.2 sklearn库实现更简洁的代码
# iris数据集
iris = load_iris()
print(iris)
knn = neighbors.KNeighborsClassifier()
# 训练数据集
knn.fit(iris.data, iris.target)
# 预测
predict = knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(predict)
print(iris.target_names[predict])
1.3“鸢尾花类型”任务
1.4手写数字”项目任务
1、认识图像
彩色——黑白——灰度

数字0的数字存储形式

数据集

KNN 图像文本识别的步骤:一般为
- 图像预处理,
- 图片切割,
- 特征提取、
- 文本分类
- 图像文本输出
一、图像预处理
在图像预处理中,验证码识别还要对图像进行去燥,文字还原等比较复杂的处理。清晰的图片直接对其进行二值处理即可。

二值化处理:因为图片上的数据灰度值都是 75 或 76,所以只需把灰度值等于 75 或 76 的赋为 1,其余的为 0 。

二、图片切割

切割的过程其实就是对二值矩阵进行分片的过程,只要找到 0 到 1 和 1 到 0 的过度点
就可以判断出切割点的位置了
三、特征提取(图像的特征很多)
可以采用:选取 “1” 占所在区域的比例作为图片特征。首先将图片分为四部分,如下图所示:

然后计算左上部分 1 所占的比例 A1、左下部分 1 所占的比例 A2、右上部分 1 所占的比
例 A3、右下部分 1 所占的比例 A4 和所有 1 占整副图的比例 A5。这样,就提取出了此幅图
的特征向量 A=[A1,A2,A3,A4,A5]。
四、数字分类
- 求解待识别样本的特征向量 A=[A1,A2,A3,A4,A5]。
- 求解待识别样本的每个特征都和标准样本中的所有特征计算距离
- 对距离进行排序,并选出排名前 K 个的键值
- 统计 K 个键值中每个类别出现的个数,出现个数最多的类别就是最终的分类
五、图片数字输出
1.6 K值选择和整体要点

距离计算方法:


思考??几种计算方法应用与什么情况???【待解决】
另外一点:根据特征数据的取值空间,来调整坐标轴的比例。例如身高与健康程度的判断问题
样本不平衡时,应该考虑加权!

1.6 什么是欠拟合和过拟合??
参考:https://blog.csdn.net/u011630575/article/details/71158656
先看三张图片,这三张图片是线性回归模型 拟合的函数和训练集的关系
- 第一张图片拟合的函数和训练集误差较大,我们称这种情况为 欠拟合
- 第二张图片拟合的函数和训练集误差较小,我们称这种情况为 合适拟合
- 第三张图片拟合的函数完美的匹配训练集数据,我们称这种情况为 过拟合

类似的,对于逻辑回归同样也存在欠拟合和过拟合问题,如下三张图

如何解决欠拟合和过拟合问题
- 欠拟合问题,根本的原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大。
欠拟合问题可以通过增加特征维度来解决。
- 过拟合问题,根本的原因则是特征维度过多,导致拟合的函数完美的经过训练集,但是对新数据的预测结果则较差。
解决过拟合问题,则有2个途径:(需要继续学习才知道这里面的方法)
1、减少特征维度; 可以人工选择保留的特征,或者模型选择算法
2、正则化; 保留所有的特征,通过降低参数θ的值,来影响模型
2.0 第二章 朴素贝叶斯


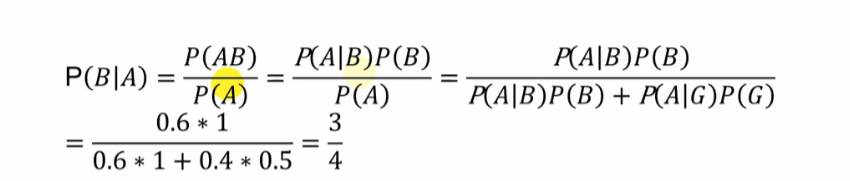

条件概率:就是指在事件 B 发生的情况下,事件 A 发生的概率,用 P(A|B)来表示

根据文氏图,可以很清楚地看到在事件 B 发生的情况下,事件 A 发生的概率就是 P(A∩B)除以 P(B)

我们把 P(A)称为"先验概率"(Prior probability),即在 B 事件发生之前,我们对 A 事件概率的一个判断。P(A|B)称为"后验概率" (Posterior probability),即在 B 事件发生之后,我们对 A 事件概率的重新评估。P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。所以,条件概率可以理解成下面的式子:
后验概率 = 先验概率 x 调整因子

这是个反常识的结果:真正病的概率大概1/11;原因是发病率低,健康人太多,而检测的假阳性概率相比于发病率来说太大(大了超多一个数量级别)

2.2 核心算法

2.3 算法拼写检测算法
code 地址:http://norvig.com/spell-correct.html
3.0 决策树
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映
射关系。

- 树中每个节点表示某个对象,
- 每个分叉路径则代表某个可能的属性值,
- 每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。

一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结点:通常用三角形来表示
递归
每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。
类型
- 分类树分析是当预计结果可能为离散类型(例如三个种类的花,输赢等)使用
的概念。 - 回归树分析是当局域结果可能为实数(例如房价,患者住院时间等)使用的概
念。 - CART 分析是结合了上述二者的一个概念。CART 是 Classification And
Regression Trees 的缩写. - en:CHAID(Chi-Square Automatic Interaction Detector)

插曲:计算机之父冯诺依曼建议用“熵entropy”,因为大家都不知道这个词的意思…
随机变量 X 的熵:
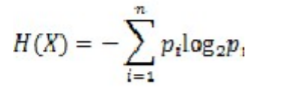
可以看出熵只与随机变量的结果相关!!
扔硬币的情况讨论,正反都是50%的概率


简单来说,熵是描述事物的混乱程度的(也可以说是不确定性)。例如:中国足球进入世界杯,这个不确定性可能是0,所以熵可能就是0;6面的色子的不确定性比12面色子的要低,所以熵也会比其低。现在就来看熵的公式:H = -∑ni=1p(xi)log2p(xi)
那6面色子的熵:1/6*log21/6的6倍,也就是2.585
以此类推,那12面的熵就是:3.585





- 参考:https://cloud.tencent.com/developer/article/1155550
所以决策树是一个递归算法,伪代码如下:
def createBranch():
检测数据集中的所有数据的分类标签是否相同:
If so return 类标签
Else:
寻找划分数据集的最好特征(划分之后信息熵最小,也就是信息增益最大的特征)
划分数据集
创建分支节点
for 每个划分的子集
调用函数 createBranch (创建分支的函数)并增加返回结果到分支节点中
return 分支节点
算法优缺点
- 优点:利于理解
- 缺点:容易过拟合

ID3倾向于过拟合,例如:对人的分类,有提供了身份证号码,ID3会认为身份证号码与人一一对应,因而认定熵为"零“,但这样的决策没有意义。
C4.5引入了信息增益率来作为选择属性的标准。

补充,条件熵(Conditional Entropy)与信息增益(Information Gain)
未完待续!
