前言
写这一篇文章的主要原因是因为在看论文的时候,有些名词真的对新手不友好。我看了论文也看不懂,有些只好请教我的老师才得以知道……简单对这些遇到的名词记录下,方便读者看论文。
可以简单看看「王垠」对于计算机视觉的理解的文章吧。
目录在全文的最末,跳转
名词解释
简单名词性解释
| 概念 | 说明 |
|---|---|
| 张量 | 多维数组。 |
| 深度学习 | 深层神经网络。深层神经网络是多层非线性变换最常用的一种方法。精确定义:一类通过多层非线性变换对高复杂性数据建模算法的合集。 |
| 线性模型的最大的局限性 | 只通过线性变换,任意层的全连接神经网络和单层神经网络模型的表达能力没有任何区别,而且它们都是线性模型。然而线性模型能够解决的问题是有限的,这就是线性模型的最大的局限性。 |
| 组合特征提取 | 深层神经网络实际上有组合特征提取的功能。这个特性对于解决不易提取特征向量的问题(比如图片识别、语音识别等)有很大的帮助。 |
| 过拟合 | 可以通过正则化,加参数来使得模型无法完美拟合数据来避免。 |
| concatenate | 类似于Python concat的操作。 神经网络中concatenate和add层的不同 - KUN的博客 - CSDN博客 |
| 上采样和下采样 | 上采样和下采样:上采样即以数量多一方为准,扩充少的一方;下采样就是从数量多的一方随机抽取和数量少的一方的样本数量。 上采样,在Caffe中也被称为反卷积(Deconvolution),可能叫做转置卷积(conv_transpose)更为恰当一点。 机器学习中欠拟合和过拟合/上采样和下采样 - nextdoor6的博客 - CSDN博客 |
| CRFs | Conditional random fields,条件随机场。 Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials - Orville的博客 - CSDN博客 |
| IU、IoU | 交并比。 深度学习中IU、IoU(Intersection over Union)的概念理解以及python程序实现 - OLDPAN的博客 - CSDN博客 |
| fine-tuing | 微调。 |
| Stride | 步进值,是在使用滤波器在输入矩阵上滑动的时候,每次滑动的距离。Stride值越大,得到的Feature Map的尺寸就越小。 常用机器学习算法汇总比较(完) - 掘金 |
| Zero-padding | 有时候在输入矩阵的边界填补0,这样就可以将滤波器应用到边缘的像素点上,一个好的Zero-padding是能让我们可以控制好特征图的尺寸的。使用改方法的卷积叫做wide convolution,没有使用的则是narrow convolution。 |
| 深度(Depth) | 深度等于滤波器的数量。 |
| BN | Batch Normalization,批标准化。 |
| LRN | 全称为Local Response Normalization,中文名称为局部响应归一化层。 |
| ReLU | Rectified Linear Units,整流线性单元。 作用:神经网络激励函数。 神经网络激励函数的作用是什么?有没有形象的解释? - 知乎 |
| Basic | 论文中Basic指的是浅层网络。 |
| Removing max pooling | 由于maxpool会引入更高频的激活,这样的激活会随着卷积层往后传播,使得grid问题更明显。 |
| Adding layers | 在网络最后增加更小空洞率的残参block, 有点类似于HDC。 |
| Removing residual connections | 去掉残参连接,防止之前层的高频信号往后传播。 |
| Max Pooling | 最大池化层。 更多请查看:CNN卷积神经网络算法之Max pooling池化操作学习 |
| Dropout | 随机失活(dropout)是对具有深度结构的人工神经网络进行优化的方法,在学习过程中通过将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性(co-dependence )从而实现神经网络的正则化(regularization),降低其结构风险(structural risk)。 原理解析可以看看这篇文章:深度学习中Dropout原理解析 。 |
| Group Conv | 分组卷积——深度学习之群卷积(Group Convolution)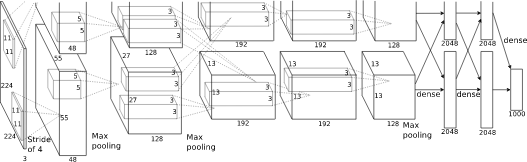 可以看看:王井东研究员在CSDN上对IGC Block做的讲座 |
| channel通道 | 一般 channels 的含义是,每个卷积层中卷积核的数量。 【CNN】理解卷积神经网络中的通道 channel |
| Multiply-Adds | 乘加,指的是模型的计算量。 |
计算机视觉概念
| 概念 | 说明 |
|---|---|
| low-level version 低级视觉 |
which concerns the extraction of image properties from the retinal image. 主要关注的是从视网膜图像中提取图像的特性。 |
| middle-level vision 中级视觉 |
which concerns the integration of image properties into perceptual organizations. 主要关注是将图像特性整合到知觉组织中。 |
| high-level vision 高级视觉 |
which concerns the everyday functionality of perceptual organizations. 主要关注的是知觉组织的日常功能。 |
数学概念
激活函数
激活函数实现去线性化。激活函数可以加入激活函数和偏置项。

- 更多的激活函数可见:激活函数
- 为什么需要激活函数:https://zhuanlan.zhihu.com/p/32824193
- 我觉得你应该看看博主写的东西,才能对激活函数有个比较充分的了解。
- 如果我们的神经网络函数是线性的,那么它的导数就是个常数,意味着Gradient和 无关了,也就意味着和输入无关了。
- 我们在做反向传播的时候,Gradient的改变也变成常数和输入的改变 无关了。
- 这个时候,就是我们激活函数(Activation Function)上场了,它对于提高模型鲁棒性,非线性表达能力,缓解梯度消失问题,将特征图映射到新的特征空间从而更有利于训练,加速模型收敛等问题都有很好的帮助。
- 神经网络激励函数的作用是什么?有没有形象的解释?
损失函数
- 神经网络模型的效果以及优化的目标是通过损失函数(
Loss Function)来定义的 。Softmax:将神经网络前向传播的到的解决变成概率分布。Softmax回归本身可以作为一个学习算法来优化分类结果,但在 TensorFlow中,Softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络的输出变成一个概率分布 。- 均方误差也是分类问题中的一种损失函数。
- 机器学习-损失函数
Softmax
- softmax分类器
- Logistic 分类器与 softmax分类器 - 殷大侠 - 博客园
- 指数分布族(The Exponential Family)与广义线性回归(Generalized Linear Model GLM) - bitcarmanlee的博客 - CSDN博客
- 广义线性模型(Generalized Linear Model)
和
介绍了 和 在应用和使用上的区别。
优化算法
- 神经网络优化算法
反向传播算法(back propagation)
给出了一个高效的方式在所有参数上使用梯度下降算法。
- 作用:训练神经网络的核心算法,可以根据定义好的算是函数优化神经网络中参数的取值,从而使得神经网络模型在训练数据集上的损失函数达到一个较小值。
- 神经网络模型中参数的优化过程直接决定了模型的质量。
梯度下降算法(gradient decent)
优化单个参数的取值
- 梯度下降算法会迭代更新参数Θ,不断沿着梯度的反方向让参数朝着总损失更小的方向更新。
- 梯度下降算法并不能保证被优化的函数达到全局最优解。
- 为了加速训练过程,可以使用随机梯度下降算法(stochastic gradient descent)。这个算法优化的不是全部训练数据上的损失函数,而是在每一轮迭代中,随机优化某一条训练数据上的损失函数。缺点很明显,可能使用随机梯度下降优化的到的神经网络模型甚至无法达到局部最优。
- 为了综合梯度下降算法和随机梯度下降算法的优缺点,可以每次计算一部分训练数据的损失函数,这一小部分数据称之为一个batch。

外链图片转存失败(img-yOFGJ2tP-1563377665002)(-ca68f214-eb30-4a09-abeb-c712b492c5bbuntitled]
机器学习
白化whitening
深度学习
卷积核的作用
- 实现跨通道的交互和信息整合。
- 进行卷积核通道数的降维和升维。
- 对于单通道
Feature Map用单核卷积即为乘以一个参数,而一般情况都是多核卷积多通道,实现多个Feature Map的线性组合。(简化模型) - 可以实现与全连接层等价的效果。如在
Faster-RCNN中用 的卷积核卷积 (如512)个特征图的每一个位置(像素点),其实对于每一个位置的 卷积本质上都是对该位置上 个通道组成的 维vector的全连接操作。
- 强烈推荐看卷积核的计算过程:CNN中卷积层的计算细节
Inception
- 模型的优化的本质就是将乘法变加法。
Inception提供并行计算的机构,优化网络的并行效果Inception是一个非常明显的“Split-Transform-Merge”结构,作者认为Inception不同分支的不同拓扑结构的特征有非常刻意的人工雕琢的痕迹,而往往调整Inception的内部结构对应着大量的超参数,这些超参数调整起来是非常困难的。所以作者的思想是每个结构使用相同的拓扑结构。- Inception的核心就是把Google Net的某一些大的卷积层换成 , , 的小卷积,这样能够大大的减小权值参数数量。
通过上面的推导和经典模型的案例分析,我们可以清楚的看到其实很多创新点都是围绕模型复杂度的优化展开的,其基本逻辑就是乘变加。模型的优化换来了更少的运算次数和更少的参数数量,一方面促使我们能够构建更轻更快的模型(例如MobileNet),一方面促使我们能够构建更深更宽的网络(例如Xception),提升模型的容量,打败各种大怪兽,欧耶~
- 卷积神经网络结构简述(二)Inception系列网络
- Inception-v4与Inception-ResNet结构详解(原创)
- 深度学习–Inception-ResNet-v1网络结构 - TiRan_Yang - CSDN博客
Inception迭代说明
Bottleneck
激活图谱
出处:Introducing Activation Atlases
We’ve created activation atlases (in collaboration with Google researchers), a new technique for visualizing what interactions between neurons can represent. As AI systems are deployed in increasingly sensitive contexts, having a better understanding of their internal decision-making processes will let us identify weaknesses and investigate failures.
我们已经创建了激活图谱(与谷歌研究人员合作),这是一种可视化神经元之间相互作用的新技术。随着人工智能系统被部署在越来越敏感的上下文环境中,更好地理解它们的内部决策过程将有助于我们发现模型的潜在问题和调研模型训练失败的原因。
Anchors的选取
BN
BN:Batch Normalization
- 解读Batch Normalization - shuzfan的专栏 - CSDN博客
- ducha-aiki/caffenet-benchmark
- BN放在激活函数的前后的对比实验
LRN
全称为Local Response Normalization,中文名称为局部响应归一化层。
在Very Deep Convolutional Networks for Large-Scale Image Recognition提出了LRN并没有什么提升,反而加大了内存消耗。
All hidden layers are equipped with the rectification (ReLU (Krizhevsky et al., 2012)) non-linearity.We note that none of our networks (except for one) containLocal Response Normalisation(LRN) normalisation (Krizhevsky et al., 2012): as will be shown in Sect. 4, such normalisationdoes not improve the performance on the ILSVRC dataset, but leads to increased memory con-sumption and computation time. Where applicable, the parameters for the LRN layer are thoseof (Krizhevsky et al., 2012)

- 首先在弄懂原理之前,希望读者能够认真看两边的公式,而不是直接看别人解释的原理。
- 是归一化后的值, 是通道的位置,代表更新的第几个通道的值, 与 代表代更新像素的位置。
- 是输入值,是激活函数ReLU的输出值。
-
、
、
、
都是自定义系数,在模型中属于超参数(
),一般设置
。
- 详情可见tensorflow的
tf.nn.lrn定义:def lrn(input, depth_radius=5, bias=1, alpha=1, beta=0.5, name=None):
- 详情可见tensorflow的
- 总的来说,是对输入值 除以一个数达到归一化的目的。
博客推荐
Google AI Blog
小众博客
科普类文章
| 文章 | 说明 |
|---|---|
| 详细解读神经网络十大误解,再也不会弄错它的工作原理 | |
| InfoQ - 促进软件开发领域知识与创新的传播 | |
| 整理一些机器学习入门方法和资料 |
计算机视觉
| 文章 | 说明 |
|---|---|
| 计算机视觉的前沿理论有哪些? | 计算机视觉的前沿理论有哪些? - 魏秀参的回答 - 知乎 |
| 计算机视觉的前沿理论有哪些? | 计算机视觉的前沿理论有哪些? - 者也的回答 - 知乎 |
大佬的博客
| 博客 | 说明 |
|---|---|
| Kaiming He 何恺明 | http://kaiminghe.com/ |
图像数据推荐
| 素材 | 说明 |
|---|---|
| alexkimxyz/nsfw_data_scraper | 色情图片素材 |
| 目标检测数据集PASCAL VOC简介 | 目标检测数据集PASCAL VOC简介 |
| 在COCO数据集中制作Darknet的训练集 - u014281900的专栏 - CSDN博客 | COCO数据集 |
| 训练样本集 - Touch_Dream的博客 - CSDN博客 | 图片训练合集 |
模型
| 模型 | 说明 |
|---|---|
| tensorflow/models | 官方模型,可以拿来迁移学习。 |
| cvdfoundation/google-landmark |
学习之路
| 文章 | 说明 |
|---|---|
| AI 卷积神经网络 CNN | |
| AlexNet | • 论文的重要贡献:证明CNN层数加深能带来更好的结果。 • 特征描述:和之前的神经网络相比,由于AlexNet采用了ReLU的非线性激活函数,一定程度上避免了梯度消失的现象;采用了dropout技术,随机丢弃连接的操作进一步增强网络的泛化能力。  • 上图中红色的字表示的是错误率。 |
| 深度学习、图像分类入门,从VGG16卷积神经网络开始 | 从卷积、池化、卷积核、Padding的基础概念讲起,介绍了VGG16模型。  • 多个小卷积核比单个大卷积核性能好 • 最佳模型:VGG16,从头到尾只有 卷积与 池化,简洁优美 • 通过增加深度能有效地提升性能 • LRN层无无性能增益 |
| ResNet | • 特点:ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元。 • 意义:ResNet通过残差学习解决了深度网络的退化问题,让我们可以训练出更深的网络,这称得上是深度网络的一个历史大突破吧。  |
| AI 全卷积神经网络FCN | • 特点:多次特征融合提高分割准确性。 • 改进:将CNN模型最后的全连接层改为卷积。  |
| U-Net | • U-Net采用了与FCN完全不同的特征融合方式:拼接! • 论文地址:U-Net: Convolutional Networks for Biomedical Image Segmentation  • U-Net式的channel维度拼接融合,对应 caffe的ConcatLayer层,对应tensorflow的tf.concat()。 |
| AI 空洞卷积 Dilated Convolution | • 图像分类任务采用的连续的Pooling和Subsampling层整合多尺度的内容信息,降低图像分辨率,以得到全局的预测输出。 • 在FCN中通过Pooling层增大感受野、缩小图像尺寸,然后通过Upsampling层来还原图像尺寸,但是这个过程中造成了精度的损失。为了减小这种精度的损失,理所当然想到的是去掉Pooling层,然而这样就导致特征图感受野太小。 • 空洞卷积(Dilated Convolution)这种不改变原图片大小(分辨率不变),同时又能提高感受野的卷积方式应运而生。 [外链图片转存失败(img-oNwcLTNi-1563377665005)(https://raw.githubusercontent.com/vdumoulin/conv_arithmetic/master/gif/dilation.gif)] |
| DenseNet | • 优点:相比ResNet拥有更少的参数数量;旁路加强了特征的重用;网络更易于训练,并具有一定的正则效果;缓解了gradient vanishing和model degradation的问题。 • 缺点:DenseNet架构由于特征重用而具有很高的计算效率。然而,原始的DenseNet实现可能需要大量的GPU内存。 • 节约内存的DenseNet实现(Memory-Efficient Implementation of DenseNets) 论文翻译 • 代码实现:Densely Connected Convolutional Networks (DenseNets)  |
| AI 语义分割 SegNet | • SegNet的主要动机是场景理解的应用(语义分割),主要动机是为了设计一个Memory and Computational Time均高效的网络结构用于道路和室内场景理解。 • 设计的最初目的就是为了从解决语义分割后边界精确定位的问题。  |
| AI 特征金字塔 FPN | • 主要解决的问题:物体检测的多尺度问题。 • 背景:在物体检测过程中,卷积过程步长stride越长,计算量越小,但是小物体检测的准确性会急剧下降。 • 目标:在尽量不增加计算量的情况下尽量提升小物体检测的准确性。  |
附录
- 按照国际惯例,不写附录总觉得有点欠缺……
- 文章链接都在上头文中,这里就不整理了吧!╮(╯▽╰)╭
其他
- AidLearning-FrameWork,感觉蛮有意思的,但是还是电脑方便……
- AidLearning App在Android手机上构建了一个带图形界面的Linux系统(不需要root),和你的Android系统共生共存,并内置了目前排名top7的深度学习框架包括Caffe、Tensorflow、Mxnet、pytorch、keras、ncnn、opencv,你不再需要复杂的配置和翻墙安装依赖包。

{kind=link}