DDIA_Charpter3 学习笔记
索引:如果不建立索引,那么我们从Database中查询数据的时候,就没有查询规则,那样我们查询某条数据时只能遍历全部数据,时间复杂度为O(N),随着数据量的增大,查询性能会快速降低。所以创建索引可以提高查询效率,但是由于写入时需要同步维护索引结构,因此会降低写入效率。
Hash索引:
维护一个键值对,Key为索引值,Value为数据在硬盘中存储的地址。Hash索引的缺陷是,无法范围查询,对于某一个范围内的数据只能遍历。
B树:
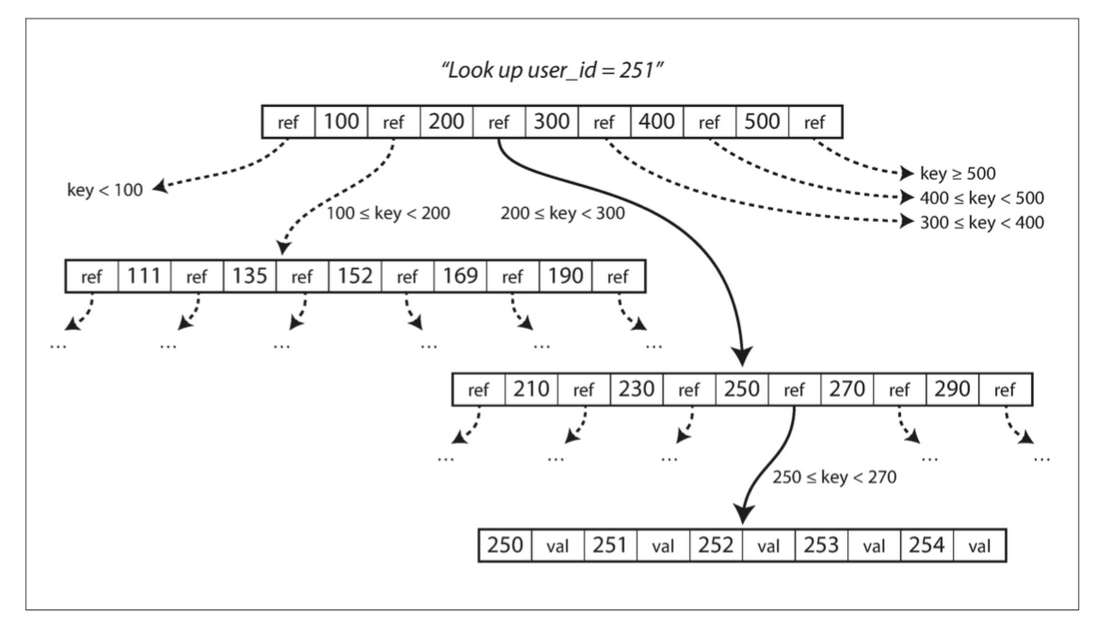
B树的每个结点指向一段磁盘空间,通常的大小是4KB或更大。B树的每个结点包含的数据:一组有序的索引值、和对应索引值对应的数据(指向数据的指针,B+树的非叶子结点不包含这类数据,因此树的高度更低)、一组指向其他结点的指针。
当B树添加索引时,首先找到目标索引所在的B树结点,并向有序的索引值中添加索引,如果结点有足够的空间则直接添加;如果空间不够,则将该结点分成两个结点,再添加。
B树的底层写操作是直接覆盖整个B树结点:因此,数据库提供了一个额外的数据结构:预写式日志(WAL, write-ahead-log)(也称为重做日志(redo log)),当需要对B树进行修改时首先需要将操作写入日志,当数据库再崩溃时可以根据该日志将B树恢复到一致的状态——因为一条数据可以有多个索引,因此需要维护多个B树,当多个B树维护到一半时数据库崩溃了,就造成了多个索引之间的结构不一致。
但是这样也造成了性能的开销——因为进行写操作时首先需要写入额外的数据结构;而且B树底层写操作是直接对B树结点进行Update,这些导致了资源的浪费(因为一个B树结点实际上存储了多条索引值)
聚簇索引(clustered index) (存储所有行数据)和 非聚集索引(nonclustered index) (存储索引对应的值和聚簇索引)
聚簇索引:不止存在于InnoDB引擎中,InnoDB引擎默认选取主键作为聚簇索引,如果不指定主键则选择第一个非空的唯一索引作为聚簇索引,如果不存在这样的索引,则会生成一个隐藏的唯一主键作为聚簇索引。
聚簇索引:聚簇索引的结点记录了整条数据,聚簇索引唯一地标识了对应的数据,既聚簇索引和一条数据具有一一对应的关系。
非聚簇索引:一条非唯一的索引无法直接查询到对应的数据,因为一张数据库表中可能有多个相同的索引值对应不同的数据,因此,需要一个索引唯一地标识出对应的数据。这个索引就被成为聚簇索引,其他的索引被称为非聚簇索引,作为该索引的辅助——既通过辅助索引查询到聚簇索引,聚簇索引对应的结点记录了整条数据(这个过程被成为回表)
覆盖索引:覆盖索引并不是一个索引类型,而是由于非聚簇索引也携带自身字段对应的值,如果查询语句查询的值只通过非聚簇索引包含的值就能完成,则成为该非聚簇索引为覆盖(了)索引。
——————————————————————————————————————————————————————————————————————————————————————
反直觉的是,内存数据库的性能优势并不是因为它们不需要从磁盘读取的事实。即使是基于磁盘的存储引擎也可能永远不需要从磁盘读取,因为操作系统缓存最近在内存中使用了磁盘块。相反,它们更快的原因在于省去了将内存数据结构编码为磁盘数据结构的开销。【44】。
OLTP在线事务处理——即使数据库开始被用于许多不同类型的博客文章,游戏中的动作,地址簿中的联系人等等,基本访问模式仍然类似于处理业务事务。应用程序通常使用索引通过某个键查找少量记录。根据用户的输入插入或更新记录。由于这些应用程序是交互式的,因此访问模式被称为 在线事务处理(OLTP, OnLine Transaction Processing) 。
OLAP在线分析处理——但是,数据库也开始越来越多地用于数据分析,这些数据分析具有非常不同的访问模式。通常,分析查询需要扫描大量记录,每个记录只读取几列,并计算汇总统计信息(如计数,总和或平均值),而不是将原始数据返回给用户。这些查询通常由业务分析师编写,并提供给帮助公司管理层做出更好决策(商业智能)的报告。为了区分这种使用数据库的事务处理模式,它被称为在线分析处理(OLAP, OnLine Analytice Processing)。
数据库通常对两种不同的使用场景做了不同的优化,虽然表面上看都是使用SQL语句对数据进行查询、聚合,但是内部优化不同。