引言和摘要对应
第一段:研究的意义
第二段:现有工作问题:一句话-》一段话-》related work
第三段:自己的方法如何解决上一段提出的问题,创新点是什么?
Digital Investigation
Tsinghua Science and Technology
期刊:
data & knowledge engineering
摘要:针对什么问题,提出什么办法,实验结果表明效果如何。
1 引言:提出问题,针对问题,文献1用了什么办法,文献2用了什么办法,有什么不足,本文提出**办法,有效可行。
3 问题模型:现在的应用是一个什么样的过程,说明清楚,可以作出流程图,针对某几个过程,有哪些问题,可以用什么办法解决。本文提出的办法,可以很好的解决。如何解决、如何设计,写个大概。
3 自己的方法:如何设计,数据结构创新的,要在写出具体的数据结构设计,并一定要结合自己的应用来说 ,某信息数据的数据结构设计如下,**表示用来干嘛干嘛。如果是算法、模型可以画出自己的流程,如何如何用。重要的是能套到自己应用的词,尽量写上,这样可体现你的东东确实在应用到实际当中,而不是乱编的。
4 具体算法或操作:具体说明,必须将自己的应用套上去,在某某应用中,在什么过程当中,如何具体应用。当然上一节说明清楚了,这节可不用,视情况将要自己的东东分为一两节。
(以上三节可视具体情况,合并在一起及分离开来)
5 理论分析:自己的办法为什么可行,与其它的比较分析一下。
6 实验结果:可以进行仿真实验,比较,得出对比图,本文提出的办法确实可行有效。
17年12月 Android Malware Detection using Deep Learning on API Method Sequences
通过DEX文件获取函数的API序列,编码后使用卷积神经网络分类,能够二分类和多分类,F1-score 96%-99%,FPR = 0.06%-2%。
p.s.本文和我提取特征的做法非常相似,但是,其只能做二分类和多分类,不具有可解释性。
其获取的API序列是每个函数中的API序列;我的是在函数调用图中游走的多个函数的API序列,更能反映软件的静态结构。
18年10月 第26届欧洲信号处理会议(EUSIPCO '18) Explaining Black-box Android Malware Detection
其他工作:,围绕输入点x计算的线性近似传递了有用的信息,用于解释学习算法[3]、[14]提供的局部预测。其基本思想是确定与局部梯度rf(x)的最高(绝对)值相关的那些最具影响力的特征,即与预测类相关的置信度f。然而,在稀疏数据的情况下,对于Android恶意软件,这些方法往往会识别出大量在给定应用程序中不存在的有影响力的特征,从而使得相应的预测难以解释。
使用基准数据进行体外评估十分脆弱,使用基于梯度的方法来识别最有影响力的局部特征(假定梯度越大的特征越重要)。
创新点:以前的基于梯度的解释方法难于解释稀疏数据,本文使用![]() ,
,![]() ,其中x是输入特征,倒三角f(x)表示特征x对应的梯度,r表示特征x对应的影响力。这种计算方式有利于解释稀疏数据,可以保证当x为空时,其对应影响力为0.。
,其中x是输入特征,倒三角f(x)表示特征x对应的梯度,r表示特征x对应的影响力。这种计算方式有利于解释稀疏数据,可以保证当x为空时,其对应影响力为0.。
同时,本文基于该方法提出了一种全局解释的方法,通过简单的平均不同样本下的r值,识别最具影响力的全局特征,这些特征描述了良性和恶意软件样本。
对于不可微分的模型,本文也提出了近似方法。
2018计算与人工智能国际会议论文集 Effective and Explainable Detection of Android Malware based on Machine Learning Algorithms
摘要:在本文中,我们介绍了两种机器学习支持的方法,用于android恶意软件的静态分析。第一种方法是基于静态分析,通过概率统计找到内容,减少了信息的不确定性。在分析现有数据集的基础上,提出了特征提取方法。这两种方法都是将高维数据转化为低维数据,以减少提取特征的维数和不确定性。在训练阶段,复杂度降低了16.7%,检测未知恶意软件族的能力得到了提高。
19年4月 IEEE 构建检测Android恶意应用程序的特性问题、分类和方向
https://www.cnblogs.com/yvlian/p/11865264.html
19年5月 计 算 机 研 究 与 发 展 机器学习模型可解释性方法、应用与安全研究综述
19年6月 Don’t Paint It Black: White-Box Explanations for Deep Learning in Computer Security
白盒解释比黑盒解释更简洁、稀疏、完整,效率更高。
安全领域的网络架构一般有:NLP、CNN、RNN。
解释的方法:
1)梯度和综合梯度:计算梯度的值或改变输入大小看输出的变化
2)分层关联传播(LRP)与深度挖掘:利用反向传播将高层的相关性分值递归地传播到低层直至传播到输入层(也支持前向、卷积、rnn)。前者有这样的约束,ril表示神经元i在l层的相关性![]() ;后者细化了这一约束:
;后者细化了这一约束:
ϵ-rule ->![]() ,赋予给特征的相关性之和应等于输出y,y'的差;
,赋予给特征的相关性之和应等于输出y,y'的差;
z-rule->和LRP的约束密切相关。
3)PatternNet 和PatternAttribution(都不适用RNN)
PatternNet:判定梯度并使用“信息的方向”代替网络权重;
PatternAttribution:基于LRP框架,计算输出为0的“根点”的解释。
4)DeConvNet 和GuidedBackProp(都只适用于CNN)
给定输出y,重构输入x,即,将输出映射回输入。
5)CAM, GradCAM,GradCAM++ (都只适用于最后一层是卷积层的CNN)
通过估计CNN中最后一层卷积的输出并进行全局平均池化来计算相关性分数。其分类被建模为最后一层激活值和权重的线性组合。
6)RTIS,MASK(都只适用于图像数据)
通过优化掩码m来计算相关性分数。
![]() ,使用一个稀疏的掩码m,确定输入x的相关特征。
,使用一个稀疏的掩码m,确定输入x的相关特征。
7)LIME和KernalSHAP
假定模型是一个非线性函数f。通过给输入值x加入一系列的扰动,得到x1,x2,...xL,通过f(xi)=yi得到一系列的点对(xi,yi),可以建模出一个线性回归模型g(x)作为f在x处的局部近似。 ![]()
8)LEMNA
使用混合回归模型做目标函数f的局部近似。
https://www.cnblogs.com/yvlian/p/11816658.html
本文还通过一个例子直觉的表现了黑盒的局限性,即,可能会学到一些假象:
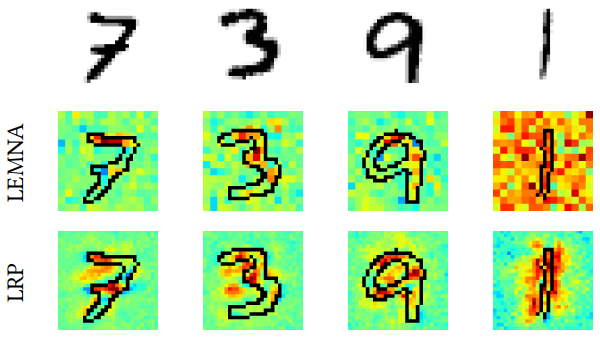 1709.06182A Survey of Machine Learning for Big Code and Naturalness
1709.06182A Survey of Machine Learning for Big Code and Naturalness
代码的许多方面,e.g.名称、格式、方法名的词法顺序,对程序语义没有影响,这正是在大多数程序分析中抽象它们的原因,但是为什么代码的统计属性如此重要呢?本文提出一种假说——自然假说:软件是人类交流的一种形式;软件语料库与自然语言语料库具有相似的统计特性;这些特性可以用来构建更好的软件工程工具。(p.s. 利用人类交流的统计数据是一种成熟有效的技术,应用广泛——Dan Jurafsky. 2000. Speech & Language Processing (3 ed.). Pearson Education. )
代码和自然语言的相似之处和不同点