文章目录
一、论文相关信息
1.论文题目
Rich feature hierarchies for accurate object detection and semantic segmentation
2.论文时间
2013年
2.论文文献
https://arxiv.org/abs/1311.2524
3.论文源码
暂无
二、论文背景及简介
在过去几年,目标检测常用的算法是机器学习的SIFT以及HOG,其使用机器学习方法融合多种低维图像特征和高维上下文环境的复杂融合系统的方法,结果准确率不高,且运行慢。同时,近几年,深度学习异军突起。RCNN作者便想使用卷积网络提取图像特征,用于目标检测。最终R-CNN在pascal VOC 2012数据集上取得了mAP 53.3%的成绩。
三、知识储备
1、selective search
selective search 是一种从一张图片中选择region proposal的方法。在之前的机器学习算法中,大多采用回归或者slide window的方法进行候选框的选择,十分耗时,该篇论文使用selective search 大大节省了时间。
selective search 根据图片的颜色直方图等大量的信息来对图片进行提取,其大体步骤如下:
- step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
- step2:找出相似度最高的两个区域,将其合并为新集,添加进R
- step3:从S中移除所有与step2中有关的子集
- step4:计算新集与所有子集的相似度
- step5:跳至step2,直至S为空
可以看selective search的论文进行更深一步了解
2、IOU
IOU是计算矩形框A、B的重合度的公式:IOU=(A∩B)/(A∪B),重合度越大,说明二者越相近。

3、mAP(mean Average Precision)
所有类AP(Average Precision)值的平均值
4、非极大值抑制(NMS)
当在图像中预测多个bbox时,由于预测的结果间可能存在高冗余(即同一个目标可能被预测多个矩形框),因此可以过滤掉一些彼此间高重合度的结果
具体操作就是根据各个bbox的score降序排序,剔除与高score bbox有较高重合度的低score bbox,那么重合度的度量指标就是IoU;
5、Bounding-box regression
经过NMS获得的候选框往往与ground-truth box有一定的差距,因此,我们需要通过Bounding-box regression来对得到的候选框进行一定程度的修正。
可以设region proposal 为 P = (Px,Py,Pw,Ph) , 设 ground-truth box 为 G = (Gx,Gy,Gw,Gh)


四、test阶段
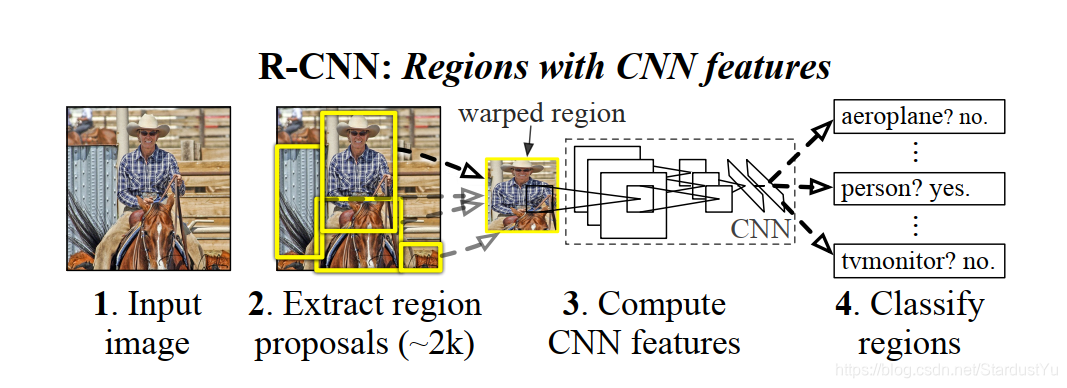
假设该模型为N分类结果,一些细节将会在下文进行介绍
- 输入一张图片
- 候选框提取:使用
selective search方法,获取该图片的候选框(region proposal),一般有2000多个,这里假设为2000 - 特征提取:将得到的候选区域,
resize后,送入卷积网络,在最后得到特征图(feature map) - 分类:根据
feature map使用线性SVM(每一个分类有一个SVM分类器),对得到的候选框进行打分 ,得到打分的矩阵(2000 * 20) - 候选框选择:使用非极大值抑制(
NMS),去除重复率高的一些候选框 - 回归:对最后的候选框进行回归修正(
Bounding-box regression),得到最后的Bounding box(b-box) 以及分类结果
五、train阶段
根据test阶段,我们可以知道在训练阶段,主要有三个任务,1、卷积网络的确定以及fine tuning 2、SVM的训练 3、Bounding-box regression的训练
下文将会对其原因以及细节进行讲解
1、卷积网络的确定以及fine tuning
检测问题中由于带标签的样本数据量比较少,难以进行大规模训练,因此在RCNN中,卷积网络使用在imageNet数据集上预训练好的AlexNet。当应用到自己的数据集上时,要进行适当的fine tuning。
在fine tuning 过程中,作者将region proposal与ground-truth box 的IOU大于0.5的设为正例(positive),剩下的作为反例(negative)。取代AlexNet的1000 way分类器,增加全连接层N+1 way(还有背景这个标签) 进行分类。一个batch有128个样本,其中32个正例,96个反例,因为IOU大于0.5的太少了。设置learning rate = 0.001 使用SGD 进行fine tuning
2、SVM的训练
在得到卷积网络后,下一步应该就要训练好分类器。在这里,作者使用了SVM对每一个分类进行二分类,而没有用softmax,具体细节可看下文细节说明。因此,N分类任务,就要训练N个SVM。
需要注意的是,在训练SVM时,其训练样本采用了不同的标注方式,在这里,作者只将ground-truth box作为positive , 将IOU 小于 0.3 的设为negative,0.3是作者调参调出来的。梯度下降来对SVM进行训练即可。
3、Bounding-box regression的训练
需要为每一个类别都训练一个regression
Bounding-box regression的完整训练过程将在本文的细节部分进行介绍
经过NMS获得的候选框往往与ground-truth box有一定的差距,因此,在论文中便使用Bounding-box regression的方式来对得到的候选框进行修正。
将NMS 获得的每个类别的region proposal(x、y、w、h),pool5输出的特征图(6 * 6 * 256维)作为输入,根据ground-truth box进行回归的训练。
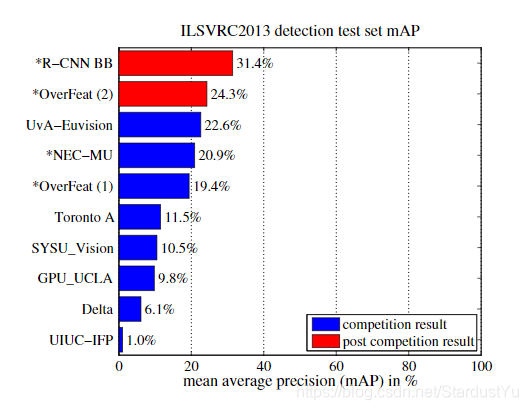
六、实验结果

七、论文细节
1、为什么SVM训练与fine tuning的样本采样方式不同?
其实,作者实现进行的SVM训练,之后再想到的fine tuning。由于SVM有较少的样本依旧训练的很好,所有作者给了SVM比较严格的样本点,数量少,但仍然可以训练的比较好。但是在卷积网络上,样本点太少,很难训练,所有作者利用了IOU 0.5~1之间的样本及进行fine turing
2、在Bounding-box regression 为何使用pool5输出的特征图?
在论文中,作者对
AlexNet的pool5、fc6、fc7得到的特征图进行了可视化的分析,作者发现,pool5的feature map与类别更加无关,所以可以把pool5之前的部分充当特征提取器,而fc6 fc7更适用于根据特征图进行分类,如果想要深入了解,请看论文。
3、在得到region proposal后,送入卷积网络时要进行缩放,缩放方式是怎样的?
在附录A中讨论了很多的预处理方法,

A. 原图
B. 等比例缩放,空缺部分用原图填充
C. 等比例缩放,空缺部分填充bounding box均值
D. 不等比例缩放到224x224
实验结果表明B的效果最好,但实际上还有很多的预处理方法可以用,比如空缺部分用区域重复。
八、论文不足
由于R-CNN流程众多,包括region proposal的选取,训练卷积神经网络,训练SVM和训练 regression,而且,对得到的每一个region proposal都要进行卷积,使得其训练时间很长(84小时),而且中间结果都要保存,占用磁盘大,而且测试一张图片的时间也较长(13s/image on a GPU or 53s/image on a CPU)。