给定一张 \(n \times m\) 的网格图,其中有障碍,每行每列不超过一个,每个障碍周围 \(8\) 格无障碍。求任选两个无障碍点之间路径的期望长度。
考虑推一下路径期望长度的式子:设无障碍点为“好点”,有障碍点为“坏点”,两个不同“好点” \(i\) 和 \(j\) 之间的距离为 \(d(i,j)\) 。“好点”总数为 \(p\) 。则路径期望长度 \(= \frac{\sum_{i=1}^p \sum_{j=1}^p d(i,j)}{p^2}\) 。
然后推两个不同“好点”间距离:对于大部分“好点”,两点间距离就是其曼哈顿距离。而对于如下图中的 \(A\) 点和 \(B\) 点(左边的“好点”同行右侧有“坏点” \(1\) 、右边的“好点”同行左侧有“坏点” \(2\) 且“坏点” \(1\) 在“坏点” \(2\) 左侧),则两“好点”间距为其曼哈顿距离 \(+2\) 。
然后就是计算曼哈顿距离:考虑分行和列分别来做。
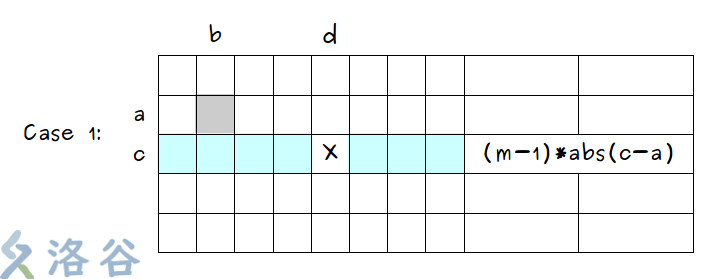
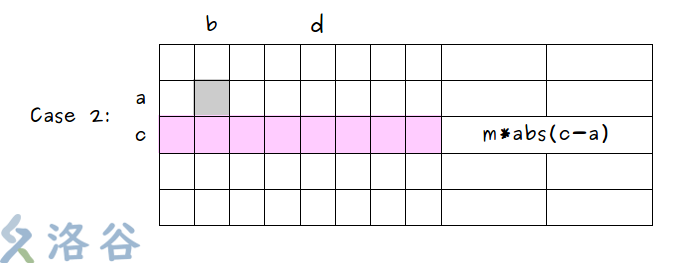
以行为例,枚举行数 \(a\) ,对于每一行的“好点”整体计算在竖直方向走过的距离。如下图,对于一个“好点” \((a,b)\) ,其到第 \(c\) 行所有点竖直方向上的距离之和等于第 \(c\) 行所有“好点”的数量 \(\times\) 第 \(c\) 行与第 \(a\) 行之间的距离差。
由题可知每行有 \(m\) 个点,则第 \(c\) 行有“坏点”时,对答案贡献了 \((m-1) \times abs(c-a)\) (如下图 \(Case\) \(1\) );第 \(c\) 行没有“坏点”时,对答案贡献了 \(m \times abs(c-a)\) (如下图 \(Case\) \(2\) )。
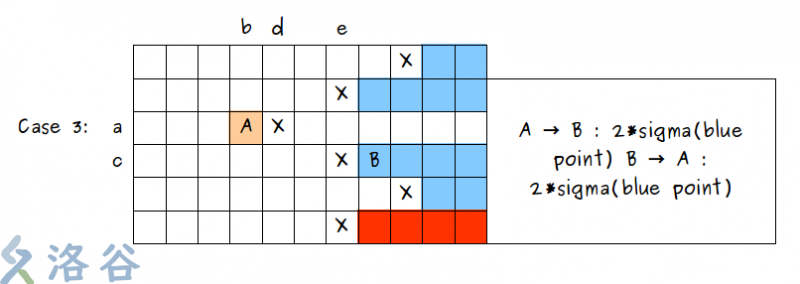
最后考虑曼哈顿距离 \(+2\) 的“好点”如何补上 \(2\) 的绕路:之前大多数人听到的做法会有重复,我这儿讲一个不去重的!

还是分行和列考虑:以行为例,枚举行数 \(a\) 。当第 \(a\) 行有“坏点”时,这个“坏点”左边所有的点都有可能绕路。
检查上下的所有行,维护一个块(如下图蓝色部分)使得在这个块之内所有的“好点”都需要绕路:
向下维护时,只要当前行的“坏点”在其下面一行的“坏点”的左边,就可以将该“坏点”右边的所有点加入块内;
如果当前行的“坏点”在其上面一行的“坏点”的右边,则将该“坏点”右边的所有“好点”加入块内后结束维护(如红色“好点”均不需要加入块内)。整个块的下边缘向右下方发展。
向上维护时同理,整个块的下边缘向右上方发展。上下都结束之后,设蓝点总数为 \(q\) ,对于第 \(a\) 行的一个点 \((a,b)\) 来说,它到块内任何一个点的绕路都为 \(2 \times q\) 。
这样就计算了一次从左上方到右下方的“好点”和从左下方到右上方的“好点”的路径。此时只要将刚刚计算的值 \(\times 2\) ,便得出了该“好点”到所有需要绕路的“好点”和所有需要绕路到该“好点”去的“好点”绕路长之和。
算出该值后,乘上第 \(a\) 行“坏点”左边的“好点”的个数加入答案即可。
每一行做完一次如下的操作后,枚举列再做一次类似的操作即可。
整个过程就是这样,如果还没明白或者觉得需要证明的,评论区见!感谢您的耐心阅读!
代码如下:
#include<bits/stdc++.h>
using namespace std;
inline int read()
{
int ret=0,f=1;
char ch=getchar();
while(ch>'9'||ch<'0')
{
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
{
ret=(ret<<1)+(ret<<3)+ch-'0';
ch=getchar();
}
return ret*f;
}
int n,m,totx,tot,hangx[2005],liex[2005];
double ans;
char s[2005];
inline long long finds(int n,int m,int a[])
{
long long ret=0;
for(register int i=1;i<=n;i++)
{
long long sum=0,cnt=m-a[i];
for(register int j=1;j<=n;j++)
{
if(a[j])
sum+=(m-1)*abs(i-j);
else
sum+=m*abs(i-j);
}
if(a[i])
ret+=(m-1)*sum;
else
ret+=m*sum;
if(a[i])
{
int l=i-1,r=i+1;
while(a[l+1]<a[l])
{
cnt+=m-a[l];
l--;
}
while(a[r-1]<a[r])
{
cnt+=m-a[r];
r++;
}
ret+=4*cnt*(a[i]-1);
}
}
return ret;
}
int main()
{
n=read();
m=read();
for(register int i=1;i<=n;i++)
{
scanf("%s",&s);
for(register int j=1;j<=m;j++)
{
if(s[j-1]=='X')
{
hangx[i]=j;
liex[j]=i;
totx++;
}
}
}
tot=n*m-totx;
ans=(finds(n,m,hangx)+finds(m,n,liex))*1.0/tot/tot;
printf("%0.6lf\n",ans);
return 0;
}