前言
循环神经网络得益于其记忆功能使其擅长处理序列方面的问题,它能提取序列之间的特征,进而对序列输出进行预测。比如我说“我肚子饿了,准备去xx”,那么根据前面的序列输入来预测“xx”很可能就是“吃饭”。
单向循环神经网络
所谓的单向循环神经网络其实就是常见的循环神经网络,可以看到t时刻、t-1时刻、t+1时刻,不同时刻输入对应不同的输出,而且上一时刻的隐含层会影响当前时刻的输出。这种结构就是单向循环神经网络结构。
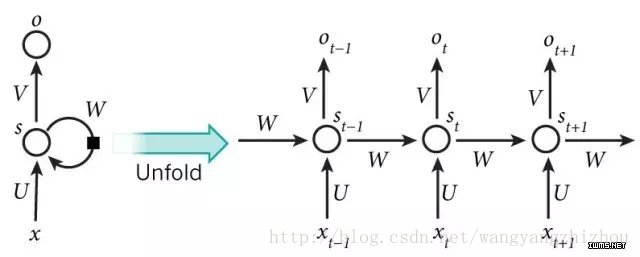
单向循环神经网络不足
从单向的结构可以知道它的下一刻预测输出是根据前面多个时刻的输入来共同影响的,而有些时候预测可能需要由前面若干输入和后面若干输入共同决定,这样会更加准确。比如我说“我肚子xx,准备去吃饭”,那么如果没有后面的部分就不能很好地推断出是“饿了”,也可以是“好疼”或“胖了”之类的。
双向循环神经网络
鉴于单向循环神经网络某些情况下的不足,提出了双向循环神经网络。因为是需要能关联未来的数据,而单向循环神经网络属于关联历史数据,所以对于未来数据提出了反向循环神经网络,两个方向的网络结合到一起就能关联历史与未来了。
双向循环神经网络按时刻展开的结构如下,可以看到向前和向后层共同连接着输出层,其中包含了6个共享权值,分别为输入到向前层和向后层两个权值、向前层和向后层各自隐含层到隐含层的权值、向前层和向后层各自隐含层到输出层的权值。

其实双向循环神经网络可以拆分成如下两个神经网络:


双向循环网络如何训练
前向传播
1. 沿着时刻1到时刻T正向计算一遍,得到并保存每个时刻向前隐含层的输出。
2. 沿着时刻T到时刻1反向计算一遍,得到并保存每个时刻向后隐含层的输出。
3. 正向和反向都计算完所有输入时刻后,每个时刻根据向前向后隐含层得到最终输出。
反向传播
1. 计算所有时刻输出层的δδ项。
2. 根据所有输出层的δδ项,使用 BPTT 算法更新向前层。
3. 根据所有输出层的δδ项,使用 BPTT 算法更新向后层。
实现代码
创建词汇
处理字符首先就是需要创建包含语料中所有的词的词汇,需要一个从字符到词汇位置索引的词典,也需要一个从位置索引到字符的词典。
def create_vocab(text):
unique_chars = list(set(text))
print(unique_chars)
vocab_size = len(unique_chars)
vocab_index_dict = {}
index_vocab_dict = {}
for i, char in enumerate(unique_chars):
vocab_index_dict[char] = i
index_vocab_dict[i] = char
return vocab_index_dict, index_vocab_dict, vocab_size批量生成器
创建一个批量生成器用于将文本生成批量的训练样本,其中text为整个语料,batch_size为批大小,vocab_size为词汇大小,seq_length为序列长度,vocab_index_dict为词汇索引词典。生成器的生成结构大致如下图,按文本顺序竖着填进矩阵,而矩阵的列大小为batch_size。
class BatchGenerator(object):
def __init__(self, text, batch_size, seq_length, vocab_size, vocab_index_dict):
self._text = text
self._text_size = len(text)
self._batch_size = batch_size
self.vocab_size = vocab_size
self.seq_length = seq_length
self.vocab_index_dict = vocab_index_dict
segment = self._text_size // batch_size
self._cursor = [offset * segment for offset in range(batch_size)]
self._last_batch = self._next_batch()
def _next_batch(self):
batch = np.zeros(shape=(self._batch_size), dtype=np.float)
for b in range(self._batch_size):
batch[b] = self.vocab_index_dict[self._text[self._cursor[b]]]
self._cursor[b] = (self._cursor[b] + 1) % self._text_size
return batch
def next(self):
batches = [self._last_batch]
for step in range(self.seq_length):
batches.append(self._next_batch())
self._last_batch = batches[-1]
return batches
构建图
分别定义向前和向后两个LSTM循环神经网络,需要指定隐含层的神经元数hidden_size,然后将创建的两个神经网络传入static_bidirectional_rnn完成双向循环神经网络的创建。
lstm_fw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0)
lstm_bw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0)
outputs, _, _ = rnn.static_bidirectional_rnn(lstm_fw_cell, lstm_bw_cell, sliced_inputs, dtype=tf.float32)接着创建占位符,主要有输入占位符和target占位符,输入占位符,与批大小和序列长度相关的结构[batch_size, seq_length]。最后是target占位符,结构与输入占位符是一样的。为更好理解这里给输入和target画个图,如下:
input_data = tf.placeholder(tf.int64, [batch_size, seq_length], name='inputs')
input_targets = tf.placeholder(tf.int64, [batch_size, seq_length], name='targets')

一般我们会需要一个嵌入层将词汇嵌入到指定的维度空间上,维度由embedding_size指定。同时vocab_size为词汇大小,这样就可以将所有单词都映射到指定的维数空间上。嵌入层结构如下图,通过tf.nn.embedding_lookup就能找到输入对应的词空间向量了,这里解释下embedding_lookup操作,它会从词汇中取到inputs每个元素对应的词向量,inputs为2维的话,通过该操作后变为3维,因为已经将词用embedding_size维向量表示了。
embedding = tf.get_variable('embedding', [vocab_size, embedding_size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
上面得到的3维的嵌入层空间向量,我们无法直接传入循环神经网络,需要一些处理。需要根据序列长度切割,通过split后再经过squeeze操作后得到一个list,这个list就是最终要进入到循环神经网络的输入,list的长度为seq_length,这个很好理解,就是由这么多个时刻的输入。每个输入的结构为(batch_size,embedding_size),也即是(20,128)。注意这里的embedding_size,刚好也是128,与循环神经网络的隐含层神经元数量一样,这里不是巧合,而是他们必须要相同,这样嵌入层出来的矩阵输入到神经网络才能刚好与神经网络的各个权重完美相乘。最终得到循环神经网络的输出和最终状态。
sliced_inputs = [tf.squeeze(input_, [1]) for input_ in
tf.split(axis=1, num_or_size_splits=seq_length, value=inputs)]经过2层循环神经网络得到了输出outputs,但该输出是一个list结构,我们要通过tf.reshape转成tf张量形式,该张量结构为(200,128)。同样target占位符也要连接起来,结构为(200,)。接着构建softmax层,权重结构为[hidden_size, vocab_size],偏置项结构为[vocab_size],输出矩阵与权重矩阵相乘并加上偏置项得到logits,然后使用sparse_softmax_cross_entropy_with_logits计算交叉熵损失,最后求损失平均值。
flat_outputs = tf.reshape(tf.concat(axis=1, values=outputs), [-1, 2 * hidden_size])
flat_targets = tf.reshape(tf.concat(axis=1, values=input_targets), [-1])
logits = tf.matmul(flat_outputs, weights) + biases
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=flat_targets)
mean_loss = tf.reduce_mean(loss)最后使用优化器对损失函数进行优化。为了防止梯度爆炸或梯度消失需要用clip_by_global_norm对梯度进行修正。
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(mean_loss, tvars), max_grad_norm)
optimizer = tf.train.AdamOptimizer(tf_learning_rate)
train_op = optimizer.apply_gradients(zip(grads, tvars))计算训练准确率。
prediction = tf.nn.softmax(logits)
correct_pred = tf.equal(tf.argmax(prediction, 1), flat_targets)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))创建会话
创建会话开始训练,设置需要训练多少轮,由num_epochs指定。epoch_size为完整训练一遍语料库需要的轮数。通过批量生成器获取一批样本数据,因为当前时刻的输入对应的正确输出为下一时刻的值,所以用data[:-1]和data[1:]得到输入和target。组织ops并将输入、target和状态对应输入到占位符上,执行。
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
for i in range(num_epochs):
data = train_batches.next()
inputs = np.array(data[:-1]).transpose()
targets = np.array(data[1:]).transpose()
ops = [mean_loss, train_op, tf_learning_rate, accuracy]
feed_dict = {input_data: inputs, input_targets: targets}
average_loss, __, lr, acc = session.run(ops, feed_dict)
if i % 100 == 0:
logging.info("average loss: %.5f,accuracy: %.3f", average_loss, acc)