1.图片识别引擎
1. OCR介绍
OCR(Optical Character Recognition)是指使用扫描仪或数码相机对文本资料进行扫描成图像文件,然后对图像文件进行分析处理,自动识别获取文字信息及版面信息的软件。
2.1 什么是tesseract
Tesseract,一款由HP实验室开发由Google维护的开源OCR引擎,特点是开源,免费,支持多语言,多平台。
2.2 图片识别引擎环境的安装
2.2.1 引擎的安装
- mac环境下直接执行命令
brew install --with-training-tools tesseract
2.2.2 windows环境下的安装
可以通过exe安装包安装,下载地址可以从GitHub项目中的wiki找到。安装完成后记得将Tesseract 执行文件的目录加入到PATH中,方便后续调用。
默认安装后的路径:C:\Program Files\Tesseract-OCR\ ,将其添加到环境变量。有可能也会是Program Files(x86)的路径下的文件夹

2.2.3 linux环境下的安装
sudo apt-get install tesseract-ocr
2.3 Python库的安装
- 1、PIL用于打开图片文件
pip(或pip3) install pillow
- 2、 pytesseract模块用于从图片中解析数据
pip/pip3 install pytesseract
2.4 图片识别引擎的使用
通过pytesseract模块的 image_to_string 方法就能将打开的图片文件中的数据提取成字符串数据,具体方法如下
from PIL import Image
import pytesseract
# 创建img对象,传入图片文件(所在路径)
im = Image.open('1.jpg')
# 调用识别引擎,得到string类型的结果
result = pytesseract.image_to_string(im)
print(result)
2.5 运行报错1
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
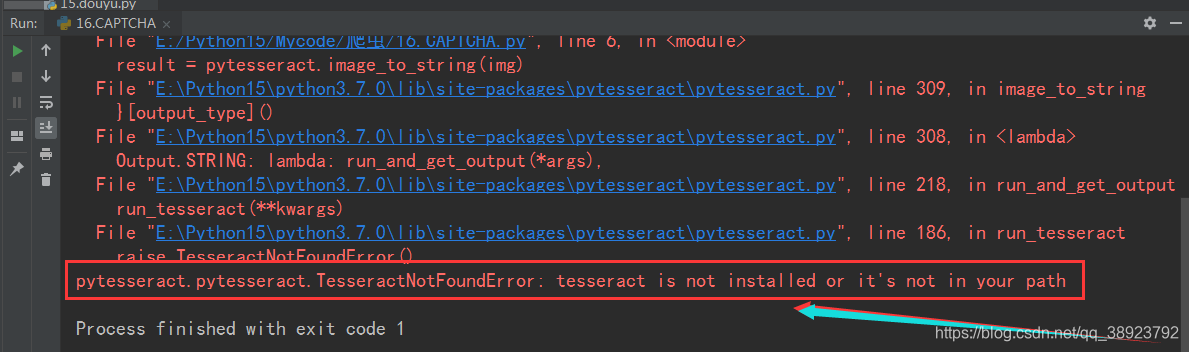
2.6 报错1解决办法
确保环境变量设置正确。
再将pytesseract.py源码中,Ctrl + F搜索tesseract_cmd:
tesseract_cmd = 'tesseract'
更改为:
tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'
再次运行之前的python脚本,成功.
2.7 报错2:
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file \\Program Files (x86)\\Tesseract-OCR\\eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'eng\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
2.8 报错2解决办法
点击系统变量新建增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径C:\Program Files\Tesseract-OCR\tessdata,全部确定,再次运行代码。
