OSI协议
图解

详解
1 应用层 (Application):
2 网络服务与最终用户的一个接口。
3 协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
4
5 表示层(Presentation Layer):
6 数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层)
7 格式有,JPEG、ASCll、DECOIC、加密格式等
8
9 会话层(Session Layer):
10 建立、管理、终止会话。(在五层模型里面已经合并到了应用层)
11 对应主机进程,指本地主机与远程主机正在进行的会话
12
13 传输层 (Transport):
14 定义传输数据的协议端口号,以及流控和差错校验。
15 协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
16
17 网络层 (Network):
18 进行逻辑地址寻址,实现不同网络之间的路径选择。
19 协议有:ICMP IGMP IP(IPV4 IPV6) ARP RARP
20
21 数据链路层 (Link):
22 建立逻辑连接、进行硬件地址寻址、差错校验等功能。(由底层网络定义协议)
23 将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正
24
25 物理层(Physical Layer):
26 是计算机网络OSI模型中最低的一层
27 物理层规定:为传输数据所需要的物理链路创建、维持、拆除
28 而提供具有机械的,电子的,功能的和规范的特性
29 简单的说,物理层确保原始的数据可在各种物理媒体上传输。局域网与广域网皆属第1、2层
30 物理层是OSI的第一层,它虽然处于最底层,却是整个开放系统的基础
31 物理层为设备之间的数据通信提供传输媒体及互连设备,为数据传输提供可靠的环境
TCP/IP协议
图解


TCP/IP三次握手四次挥手

序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生;给字节编上序号后,就给每一个报文段指派一个序号;序列号seq就是这个报文段中的第一个字节的数据编号。
确认号ack:占4个字节,期待收到对方下一个报文段的第一个数据字节的序号;序列号表示报文段携带数据的第一个字节的编号;而确认号指的是期望接收到下一个字节的编号;因此当前报文段最后一个字节的编号+1即为确认号。
确认ACK:占1位,仅当ACK=1时,确认号字段才有效。ACK=0时,确认号无效
同步SYN:连接建立时用于同步序号。当SYN=1,ACK=0时表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使得SYN=1,ACK=1。因此,SYN=1表示这是一个连接请求,或连接接受报文。SYN这个标志位只有在TCP建产连接时才会被置1,握手完成后SYN标志位被置0。
终止FIN:用来释放一个连接。FIN=1表示:此报文段的发送方的数据已经发送完毕,并要求释放运输连接
PS:ACK、SYN和FIN这些大写的单词表示标志位,其值要么是1,要么是0;ack、seq小写的单词表示序号。

三次握手过程理解

第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手过程理解

1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
常见面试题
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
Http协议
Http与Https的区别:
- HTTP 的URL 以http:// 开头,而HTTPS 的URL 以https:// 开头
- HTTP 是不安全的,而 HTTPS 是安全的
- HTTP 标准端口是80 ,而 HTTPS 的标准端口是443
- 在OSI 网络模型中,HTTP工作于应用层,而HTTPS 的安全传输机制工作在传输层
- HTTP 无法加密,而HTTPS 对传输的数据进行加密
- HTTP无需证书,而HTTPS 需要CA机构wosign的颁发的SSL证书
什么是Http协议无状态协议?怎么解决Http协议无状态协议?
-
无状态协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息
可以使用Cookie来解决无状态的问题,Cookie就相当于一个通行证,第一次访问的时候给客户端发送一个Cookie,当客户端再次来的时候,拿着Cookie(通行证),那么服务器就知道这个是”老用户“。- 也就是说,当客户端一次HTTP请求完成以后,客户端再发送一次HTTP请求,HTTP并不知道当前客户端是一个”老用户“。
URI和URL的区别
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
- Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的
- URI一般由三部组成:
- ①访问资源的命名机制
- ②存放资源的主机名
- ③资源自身的名称,由路径表示,着重强调于资源。
URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
- URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
- 采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:
- ①协议(或称为服务方式)
- ②存有该资源的主机IP地址(有时也包括端口号)
- ③主机资源的具体地址。如目录和文件名等
URN,uniform resource name,统一资源命名,是通过名字来标识资源,比如mailto:[email protected]。
- URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news 和 isbn URI 都是 URN 的示例。
在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。
在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。
相反的是,URL类可以打开一个到达资源的流。
常用的HTTP方法有哪些?
- GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器
- POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。
- PUT: 传输文件,报文主体中包含文件内容,保存到对应URI位置。
- HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。
- DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。
- OPTIONS:查询相应URI支持的HTTP方法。
HTTP请求报文与响应报文格式
请求报文包含四部分:
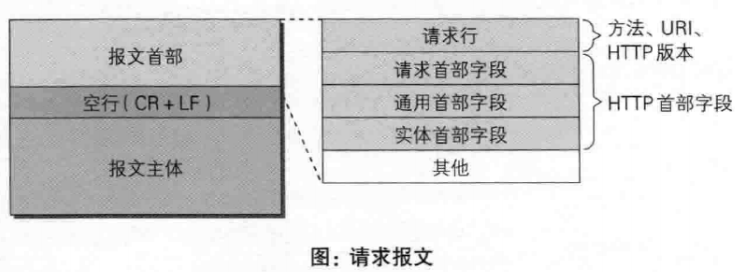
- a、请求行:包含请求方法、URI、HTTP版本信息
- b、请求首部字段
- c、请求内容实体
- d、空行
响应报文包含四部分:
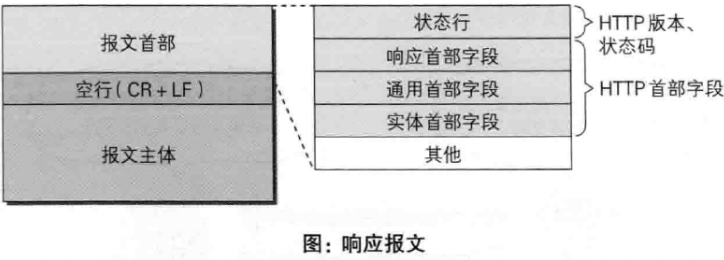
- a、状态行:包含HTTP版本、状态码、状态码的原因短语
- b、响应首部字段
- c、响应内容实体
- d、空行
常见的首部:
-
通用首部字段(请求报文与响应报文都会使用的首部字段)
- Date:创建报文时间
- Connection:连接的管理
- Cache-Control:缓存的控制
- Transfer-Encoding:报文主体的传输编码方式
-
请求首部字段(请求报文会使用的首部字段)
- Host:请求资源所在服务器
- Accept:可处理的媒体类型
- Accept-Charset:可接收的字符集
- Accept-Encoding:可接受的内容编码
- Accept-Language:可接受的自然语言
-
响应首部字段(响应报文会使用的首部字段)
- Accept-Ranges:可接受的字节范围
- Location:令客户端重新定向到的URI
- Server:HTTP服务器的安装信息
-
实体首部字段(请求报文与响应报文的的实体部分使用的首部字段)
- Allow:资源可支持的HTTP方法
- Content-Type:实体主类的类型
- Content-Encoding:实体主体适用的编码方式
- Content-Language:实体主体的自然语言
- Content-Length:实体主体的的字节数
- Content-Range:实体主体的位置范围,一般用于发出部分请求时使用
HTTPS工作原理
- 一、首先HTTP请求服务端生成证书,客户端对证书的有效期、合法性、域名是否与请求的域名一致、证书的公钥(RSA加密)等进行校验;
- 二、客户端如果校验通过后,就根据证书的公钥的有效, 生成随机数,随机数使用公钥进行加密(RSA加密);
- 三、消息体产生的后,对它的摘要进行MD5(或者SHA1)算法加密,此时就得到了RSA签名;
- 四、发送给服务端,此时只有服务端(RSA私钥)能解密。
- 五、解密得到的随机数,再用AES加密,作为密钥(此时的密钥只有客户端和服务端知道)。
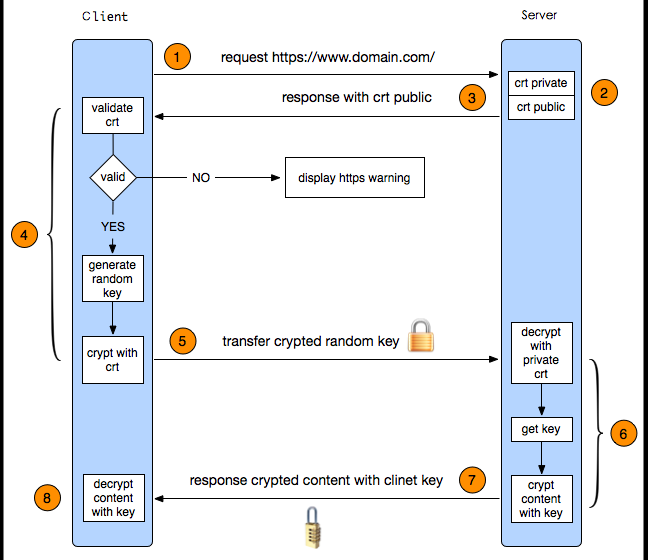
1. 客户端发起HTTPS请求
这个没什么好说的,就是用户在浏览器里输入一个https网址,然后连接到server的443端口。
2. 服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)。这套证书其实就是一对公钥和私钥。如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3. 传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4. 客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随即值。然后用证书对该随机值进行加密。就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5. 传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6. 服务段解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7. 传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在客户端被还原
8. 客户端解密信息
客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。
一次完整的HTTP请求所经历的7个步骤
HTTP通信机制是在一次完整的HTTP通信过程中,Web浏览器与Web服务器之间将完成下列7个步骤:
- 建立TCP连接
在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建 Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则, 只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。
- Web浏览器向Web服务器发送请求行
一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令。例如:GET /sample/hello.jsp HTTP/1.1。
-
Web浏览器发送请求头
- 浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。
-
Web服务器应答
- 客户机向服务器发出请求后,服务器会客户机回送应答, HTTP/1.1 200 OK ,应答的第一部分是协议的版本号和应答状态码。
-
Web服务器发送应答头
- 正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。
-
Web服务器向浏览器发送数据
- Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据。
-
Web服务器关闭TCP连接
- 一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码:
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
建立TCP连接->发送请求行->发送请求头->(到达服务器)发送状态行->发送响应头->发送响应数据->断TCP连接
最具体的HTTP请求过程:
当我们在web浏览器的地址栏中输入: www.baidu.com,然后回车,到底发生了什么
过程概览
1.对www.baidu.com这个网址进行DNS域名解析,得到对应的IP地址
2.根据这个IP,找到对应的服务器,发起TCP的三次握手
3.建立TCP连接后发起HTTP请求
4.服务器响应HTTP请求,浏览器得到html代码
5.浏览器解析html代码,并请求html代码中的资源(如js、css图片等)(先得到html代码,才能去找这些资源)
6.浏览器对页面进行渲染呈现给用户
注:1.DNS域名解析采用的是递归查询的方式,过程是,先去找DNS缓存->缓存找不到就去找根域名服务器->根域名又会去找下一级,这样递归查找之后,找到了,给我们的web浏览器
2.为什么HTTP协议要基于TCP来实现? TCP是一个端到端的可靠的面相连接的协议,HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,会重传)
3.最后一步浏览器是如何对页面进行渲染的? a)解析html文件构成 DOM树,b)解析CSS文件构成渲染树, c)边解析,边渲染 , d)JS 单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
下面我们来详细看看这几个过程的具体细节:
1.域名解析
a)首先会搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)
b)如果浏览器自身的缓存里面没有找到,那么浏览器会搜索系统自身的DNS缓存
c)如果还没有找到,那么尝试从 hosts文件里面去找
d)在前面三个过程都没获取到的情况下,就递归地去域名服务器去查找,具体过程如下
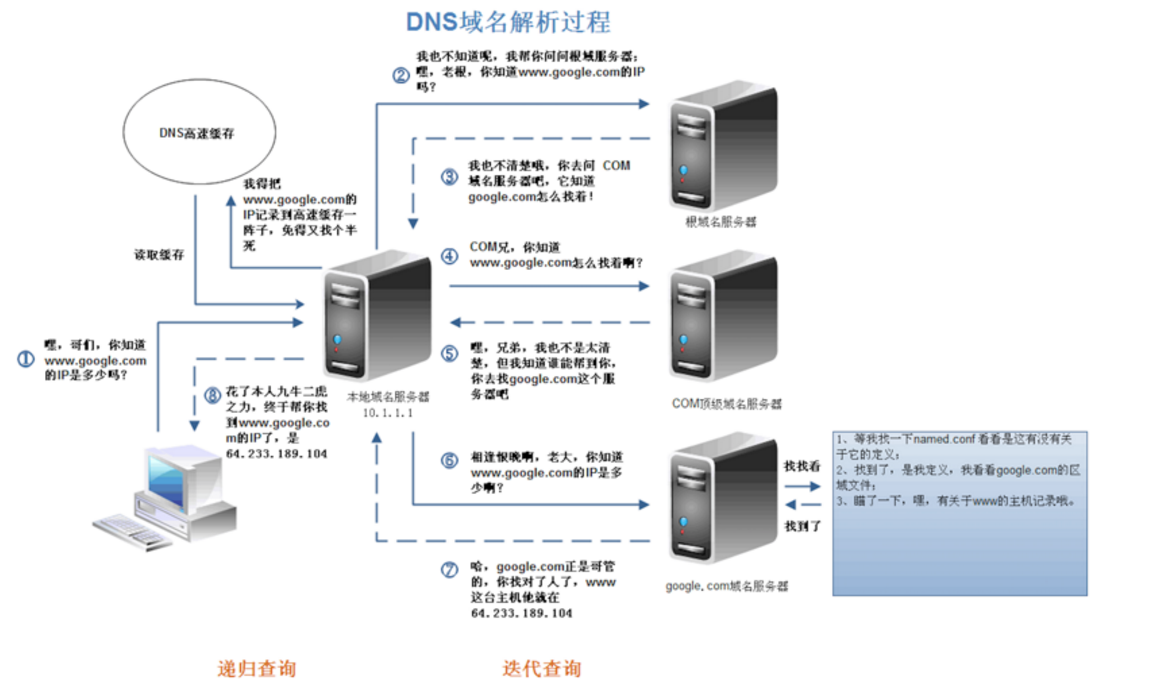
DNS优化:两个方面:DNS缓存、DNS负载均衡
2.TCP连接(三次握手)
拿到域名对应的IP地址之后,User-Agent(一般指浏览器)会以一个随机端口(1024<端口<65535)向服务器的WEB程序(常用的有httpd,nginx)等的80端口。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间有各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终达到WEB程序,最终建立了TCP/IP的连接
图解:
3.建立TCP连接之后,发起HTTP请求
HTTP请求报文由三部分组成:请求行,请求头和请求正文
请求行:用于描述客户端的请求方式,请求的资源名称以及使用的HTTP协议的版本号(例:GET/books/java.html HTTP/1.1)
请求头:用于描述客户端请求哪台主机,以及客户端的一些环境信息等
注:这里提一个请求头 Connection,Connection设置为 keep-alive用于说明 客户端这边设置的是,本次HTTP请求之后并不需要关闭TCP连接,这样可以使下次HTTP请求使用相同的TCP通道,节省TCP建立连接的时间
请求正文:当使用POST, PUT等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中(GET方式是保存在url地址后面,不会放到这里)
4.服务器端响应http请求,浏览器得到html代码
HTTP响应也由三部分组成:状态码,响应头和实体内容
状态码:状态码用于表示服务器对请求的处理结果
列举几种常见的:200(没有问题) 302(要你去找别人) 304(要你去拿缓存) 307(要你去拿缓存) 403(有这个资源,但是没有访问权限) 404(服务器没有这个资源) 500(服务器这边有问题)
若干响应头:响应头用于描述服务器的基本信息,以及客户端如何处理数据
实体内容:服务器返回给客户端的数据
注:html资源文件应该不是通过 HTTP响应直接返回去的,应该是通过nginx通过io操作去拿到的吧
5.浏览器解析html代码,并请求html代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这是时候就用上 keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里面的顺序,但是由于每个资源大小不一样,而浏览器又是多线程请求请求资源,所以这里显示的顺序并不一定是代码里面的顺序。
6.浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求的静态资源和html代码进行渲染,渲染之后呈现给用户
浏览器是一个边解析边渲染的过程。首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
自此一次完整的HTTP事务宣告完成.
总结:
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
常见的HTTP相应状态码
- 200:请求被正常处理( OK )
- 204:请求被受理但没有资源可以返回
- 206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。
- 301:永久性重定向
- 302:临时重定向
- 303:与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过GET方法重定向到另一个URI上
- 304:发送附带条件的请求时,条件不满足时返回,与重定向无关( Not Modified )
- 307:临时重定向,与302类似,只是强制要求使用POST方法
- 400:请求报文语法有误,服务器无法识别
- 401:请求需要认证
- 403:请求的对应资源禁止被访问
- 404:服务器无法找到对应资源( Not Found )
- 500:服务器内部错误( Internal Server Error )
- 502:前面代理服务器联系不到后端的服务器出现( Bad Gateway )
- 503:服务器正忙
- 504:这个是代理能联系到后端的服务器,但是后端的服务器在规定的时间内没有给代理服务器响应( Gateway Timeout )
HTTP1.1版本新特性
- a、默认持久连接节省通信量,只要客户端服务端任意一端没有明确提出断开TCP连接,就一直保持连接,可以发送多次HTTP请求
- b、管线化,客户端可以同时发出多个HTTP请求,而不用一个个等待响应
-
c、断点续传
- 实际上就是利用HTTP消息头使用分块传输编码,将实体主体分块传输。
HTTP优化方案
简要概括一下:
- TCP复用:TCP连接复用是将多个客户端的HTTP请求复用到一个服务器端TCP连接上,而HTTP复用则是一个客户端的多个HTTP请求通过一个TCP连接进行处理。前者是负载均衡设备的独特功能;而后者是HTTP 1.1协议所支持的新功能,目前被大多数浏览器所支持。
- 内容缓存:将经常用到的内容进行缓存起来,那么客户端就可以直接在内存中获取相应的数据了。
- 压缩:将文本数据进行压缩,减少带宽
- SSL加速(SSL Acceleration):使用SSL协议对HTTP协议进行加密,在通道内加密并加速
- TCP缓冲:通过采用TCP缓冲技术,可以提高服务器端响应时间和处理效率,减少由于通信链路问题给服务器造成的连接负担。
Centos 启动流程

openssl创建CA和申请证书

Docker面试题
如何批量删除或者停止运行的容器?
docker kill/rm `docker ps -aq`
如何查看镜像支持的环境变量?
使用sudo docker run IMAGE env
本地的镜像文件都存放在哪里
Docker相关的本地资源存放在/var/lib/docker/目录下,其中container目录存放容器信息,graph目录存放镜像信息,aufs目录下存放具体的镜像底层文件。
构建Docker镜像应该遵循哪些原则?
整体远侧上,尽量保持镜像功能的明确和内容的精简,要点包括:
# 尽量选取满足需求但较小的基础系统镜像,建议选择debian:wheezy镜像,仅有86MB大小
# 清理编译生成文件、安装包的缓存等临时文件
# 安装各个软件时候要指定准确的版本号,并避免引入不需要的依赖
# 从安全的角度考虑,应用尽量使用系统的库和依赖
# 使用Dockerfile创建镜像时候要添加.dockerignore文件或使用干净的工作目录
容器退出后,通过docker ps 命令查看不到,数据会丢失么?
容器退出后会处于终止(exited)状态,此时可以通过 docker ps -a 查看,其中数据不会丢失,还可以通过docker start 来启动,只有删除容器才会清除数据。
在这里还要注意开启容器的时候是否添加了--rm参数
如何控制容器占用系统资源(CPU,内存)的份额?
在使用docker create命令创建容器或使用docker run 创建并运行容器的时候,可以使用-c|–cpu-shares[=0]参数来调整同期使用CPU的权重,使用-m|–memory参数来调整容器使用内存的大小。
如何临时退出一个正在交互的容器的终端,而不终止它?
按Ctrl+p,后按Ctrl+q,如果按Ctrl+c会使容器内的应用进程终止,进而会使容器终止。
很多应用容器都是默认后台运行的,怎么查看它们的输出和日志信息?
使用docker logs,后面跟容器的名称或者ID信息
使用docker port 命令映射容器的端口时,系统报错Error: No public port ‘80’ published for …,是什么意思?
创建镜像时Dockerfile要指定正确的EXPOSE的端口,容器启动时指定PublishAllport=true
可以在一个容器中同时运行多个应用进程吗?
一般不推荐在同一个容器内运行多个应用进程,如果有类似需求,可以通过额外的进程管理机制,比如supervisord来管理所运行的进程
如何控制容器占用系统资源(CPU,内存)的份额?
在使用docker create命令创建容器或使用docker run 创建并运行容器的时候,可以使用-c|–cpu-shares[=0]参数来调整同期使用CPU的权重,使用-m|–memory参数来调整容器使用内存的大小。
仓库(Repository)、注册服务器(Registry)、注册索引(Index)有何关系?
首先,仓库是存放一组关联镜像的集合,比如同一个应用的不同版本的镜像,注册服务器是存放实际的镜像的地方,注册索引则负责维护用户的账号,权限,搜索,标签等管理。注册服务器利用注册索引来实现认证等管理。
从非官方仓库(如:dl.dockerpool.com)下载镜像的时候,有时候会提示“Error:Invaild registry endpoint https://dl.docker.com:5000/v1/…”?
Docker 自1.3.0版本往后以来,加强了对镜像安全性的验证,需要手动添加对非官方仓库的信任。
DOCKER_OPTS=”–insecure-registry dl.dockerpool.com:5000”
重启docker服务
Docker的配置文件放在那里。如何修改配置?
Ubuntu系统下Docker的配置文件是/etc/default/docker,CentOS系统配置文件存放在/etc/sysconfig/docker
如何更改Docker的默认存储设置?
Docker的默认存放位置是/var/lib/docker,如果希望将Docker的本地文件存储到其他分区,可以使用Linux软连接的方式来做。
Docker与虚拟化
Docker与LXC(Linux Container)有何不同?
LXC利用Linux上相关技术实现容器,Docker则在如下的几个方面进行了改进:
移植性:通过抽象容器配置,容器可以实现一个平台移植到另一个平台;
镜像系统:基于AUFS的镜像系统为容器的分发带来了很多的便利,同时共同的镜像层只需要存储一份,实现高效率的存储;
版本管理:类似于GIT的版本管理理念,用户可以更方面的创建、管理镜像文件;
仓库系统:仓库系统大大降低了镜像的分发和管理的成本;
周边工具:各种现有的工具(配置管理、云平台)对Docker的支持,以及基于Docker的Pass、CI等系统,让Docker的应用更加方便和多样化。
Docker与Vagrant有何不同?
两者的定位完全不同
Vagrant类似于Boot2Docker(一款运行Docker的最小内核),是一套虚拟机的管理环境,Vagrant可以在多种系统上和虚拟机软件中运行,可以在Windows。Mac等非Linux平台上为Docker支持,自身具有较好的包装性和移植性。
原生Docker自身只能运行在Linux平台上,但启动和运行的性能都比虚拟机要快,往往更适合快速开发和部署应用的场景。
开发环境中Docker与Vagrant该如何选择?
Docker不是虚拟机,而是进程隔离,对于资源的消耗很少,单一开发环境下Vagrant是虚拟机上的封装,虚拟机本身会消耗资源。
如何将一台宿主机的docker环境迁移到另外一台宿主机?
停止Docker服务,将整个docker存储文件复制到另外一台宿主机上,然后调整另外一台宿主机的配置即可
Docker容器创建后,删除了/var/run/netns 目录下的网络名字空间文件,可以手动恢复它:
# 查看容器进程ID,比如1234
sudo docker inspect --format='{{. State.pid}}' $container_id
1234
# 到proc目录下,把对应的网络名字空间文件链接到/var/run/netns,然后通过正常的系统命令查看操作容器的名字空间。
什么是Docker?
Docker是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保您的应用程序在任何环境中无缝运行。
CI(持续集成)服务器的功能是什么?
CI功能就是在每次提交之后不断地集成所有提交到存储库的代码,并编译检查错误
什么是Docker镜像?
Docker镜像是Docker容器的源代码,Docker镜像用于创建容器。使用build命令创建镜像
什么是Docker容器?
Docker容器包括应用程序及其所有依赖项,作为操作系统的独立进程运行
Docker容器有几种状态?
Docker容器可以有四种状态:
运行
已暂停
重新启动
已退出
Docker使用流程
1)创建Dockerfile后,您可以构建它以创建容器的镜像
2)推送或拉取镜像。
Dockerfile中最常见的指令是什么?
Dockerfile中的一些常用指令如下:
FROM:指定基础镜像
LABEL:功能是为镜像指定标签
RUN:运行指定的命令
CMD:容器启动时要运行的命令
Dockerfile中的命令COPY和ADD命令有什么区别?
COPY与ADD的区别COPY的<src>只能是本地文件,其他用法一致
docker常用命令?
docker pull 拉取或者更新指定镜像
docker push 将镜像推送至远程仓库
docker rm 删除容器
docker rmi 删除镜像
docker images 列出所有镜像
docker ps 列出所有容器
entrypoint & cmd 指令的区别
这主要考察 Dockerfile 良好实践中关于容器启动时运行的命令。
entrypoint 和 cmd 命令都是设置容器启动时要执行的命令,但用法稍有不同。entrypoint 和 cmd 指令都是在 Dockerfile 中定义,但在镜像构建过程中并不会被执行,只有当容器启动时,entrypoint 和 cmd 指令设置的命令才会被执行。Dockerfile 中可以有多个 entrypoint 指令,但生效的只有最后一个 entrypoint 指令,cmd 指令也类似,两者的区别主要如下:
entrypoint 指令一般用来设置容器启动后要执行的命令,这对容器来说,往往是固定不变的。
cmd 指令一般用来设置容器启动后执行命令的默认参数,这对容器来说,往往是可以改变的,cmd 能够被docker run 后面跟的命令行参数替换,一般而言,两者是可以结合使用的。
举个例子
FROM baseimage:v1.0
ENTRYPOINT ["/usr/sbin/nginx"]
CMD [""]
从以上 Dockerfile 设置的 entrypoint 和 cmd 指令来看,容器启动时会运行 nginx 进程,而 cmd 指令可以在执行 docker run 传入参数进行覆盖,如 docker run --name:** -p **:** -g "daemon off",其中 -g "daemon off" 将会被作为命令参数追加到 entrypoint 后面的指令,也就是说最后容器的启动命令为:/usr/sbin/nginx -g "daemon off;",以前台进程来运行 nginx 进程。
如何覆盖 entrypoint 和 cmd 指令
这个问题是考察 entrypoint 和 cmd 的格式
CMD 有三种格式:
(1) Exec 格式:CMD ["executabel", "param1", "param2"],这是 CMD 的推荐格式
(2) CMD ["param1", "param2"],这种模式和 entrypoint 结合使用,为 entrypoint 提供额外的参数,此时 entrypoint 必须使用 exec 格式。
(3) Shell 格式:CMD command param1 param2
ENTRYPOINT 有两种格式:
(1) Exec 格式:ENTRYPOINT ["executable", "param1", "param2"],这是 ENTRYPOINT 的推荐方式
(2) Shell 格式:ENTRYPOINT command param1 param2
其中,CMD 无论是哪种格式,都会被 docker run 命令带的参数直接覆盖
而 ENTRYPOINT 无论是哪种格式,ENTRYPOINT 指令一定会被执行,并不会被覆盖,但 ENTRYPOINT 在选择格式时必须格外小心,因为这两种格式的效果差别很大。
Exec 格式
ENTRYPOINT 中的参数始终会被使用,而 CMD 的额外参数可以在容器启动时动态替换掉。
Shell 格式
ENTRYPOINT 的 shell 格式会忽略任何 CMD 或者 docker run 提供的任何参数。
ADD 和 COPY 指令有什么区别?推荐使用哪种方式
这几道面试题都是 Dockerfile 良好实践中的知识点,这道题主要考察在构建镜像时,如何向镜像拷贝文件。
ADD 指令
ADD 指令的功能是将主机构建环境(上下文)目录中的文件和目录,拷贝到镜像中,如果源文件是个归档文件(压缩文件,如tar, gzip, bzip2),ADD 指令会自动进行解压,如:
ADD /foo.tar.gz /tmp/
上述指令会将 foo.tar.gz 压缩文件解压到容器的 /tmp 目录下。
COPY指令
COPY 指令和 ADD 指令类似,都是负责拷贝文件或者目录到容器里,但 COPY 指令功能更简洁和易懂,COPY 是ADD 的一种简化版本,目的在于满足大多数人复制文件到容器的需求,在大多数情况下,都建议使用 COPY 指令,除非你明确需要ADD指令。
两个 namespace 如何进行通信
这道题主要考察 Docker 主机两个 namespace(容器)或者是容器与主机如何进行通信的原理。
我们都知道,Docker 是基于 LXC容器技术 namespace 来实现资源的隔离,基于 LXC容器技术 cgroups 来实现资源的限制,Docker 采用虚拟网络设置(Virtual Network Device)的方式,将不同命名空间的网络设备连接到一起,这种设备对都是成对存在的,一端作为容器的网卡eth0,一端连接到宿主机上的docker网桥 veth,从而实现 Docker 主机上不同 namespace通信,详情可见下图:

简述 Docker 如何用 namespace 来进行资源隔离
这道题主要也是考察 namespace 相关的知识。
Docker 主要通过六大 Namespace 来实现资源的隔离,如下:
(1) Mount Namespace,挂载命名空间,用来隔离挂载目录,让不同 Namespace 拥有独立的挂载结构,而程序中对挂载信息的修改不会影响到其他 Namespace 中程序的运行。
(2) UTS Namespace,UTS Namespace,用来隔离主机名和域名,通过UTS Namespace,让不同 Namespace 拥有独立的主机名称和网络访问域名。
(3) IPC Namespace,进程通信命名空间,用来隔离进程间通信,主要作用于 消息队列、信号量或者是管道,IPC 只能做到同一个命名空间进行通信,无法做到不同命名空间进行信息交换通信。
(4) PID Namespace,进程命名空间,用来隔离进程的运行信息,PID Namespace 让命名空间拥有独立的进程号管理。
(5) Networt Namespace,网络命名空间,用来隔离网络协议栈,包括网络设备接口、IPV4 和 IPV6 协议等。
(6) User Namespace,用户命名空间,用来隔离用户和用户组信息,通过严格的用户隔离机制,避免 Namespace 中的程序直接操作到宿主机或者其他 Namespace 中的用户。
Kubernetes面试题
基础篇
1.kubernetes 包含几个组件。各个组件的功能是什么。组件之间是如何交互的。
2.k8s 的 pause 容器有什么用。是否可以去掉。
3.k8s 中的 pod 内几个容器之间的关系是什么。
4.一个经典 pod 的完整生命周期。
5.k8s 的 service 和 ep 是如何关联和相互影响的。
6.详述 kube-proxy 原理,一个请求是如何经过层层转发落到某个 pod 上的整个过程。请求可能来自 pod 也可能来自外部。
7.rc/rs 功能是怎么实现的。详述从 API 接收到一个创建 rc/rs 的请求,到最终在节点上创建 pod 的全过程,尽可能详细。另外,当一个 pod 失效时,kubernetes 是如何发现并重启另一个 pod 的?
8.deployment/rs 有什么区别。其使用方式、使用条件和原理是什么。
9.cgroup 中的 cpu 有哪几种限制方式。k8s 是如何使用实现 request 和 limit 的。
拓展实践篇
1.设想一个一千台物理机,上万规模的容器的 kubernetes 集群,请详述使用 kubernetes 时需要注意哪些问题?应该怎样解决?(提示可以从高可用,高性能等方向,覆盖到从镜像中心到 kubernetes 各个组件等)
2.设想 kubernetes 集群管理从一千台节点到五千台节点,可能会遇到什么样的瓶颈。应该如何解决。
3.kubernetes 的运营中有哪些注意的要点。
4.集群发生雪崩的条件,以及预防手段。
5.设计一种可以替代 kube-proxy 的实现。
6.sidecar 的设计模式如何在 k8s 中进行应用。有什么意义。
7.灰度发布是什么。如何使用 k8s 现有的资源实现灰度发布。
8.介绍 k8s 实践中踩过的比较大的一个坑和解决方式。
shell面试题
linux系统 /home目录下有一个文件test.xml,内容如下,
1 <configuration>
2
3 <artifactItems>
4
5 <artifactItem>
6
7 <groupId>zzz</groupId>
8
9 <artifactId>aaa</artifactId>
10
11 </artifactItem>
12
13 <artifactItem>
14
15 <groupId>xxx</groupId>
16
17 <artifactId>yyy</artifactId>
18
19 </artifactItem>
20
21 <!-- </artifactItem> <groupId>some groupId</groupId> <
22
23 <version>1.0.1.2.333.555</version> </artifactItem> -->
24
25 </artifactItems>
26
27 </configuration>
请写出shell脚本删除文件中的注释部分内容,获取文件中所有artifactItem的内容,并用如下格式逐行输出 artifactItem:groupId:artifactId
分析:这个文件比较特殊,但是却很有规律。注释部分内容其实就是<!-- -->中间的内容,所以我们想办法把这些内容删除掉就ok了。而artifactItem的内容,其实就是获取<artifactItem></artifactItem>中间的内容。然后想办法用提到的格式输出即可。
答案:
1 #!/bin/bash
2
3 egrep -v '<!--|-->' 1.txt |tee 2.txt //这行就是删除掉注释的行
4
5
6
7 grep -n 'artifactItem>' 2.txt |awk '{print $1}' |sed 's/://' > /tmp/line_number.txt
8
9 n=`wc -l /tmp/line_number.txt|awk '{print $1}'`
10
11
12
13 get_value(){
14
15 sed -n "$1,$2"p 2.txt|awk -F '<' '{print $2}'|awk -F '>' '{print $1,$2}' > /tmp/value.txt
16
17 nu=`wc -l /tmp/value.txt|awk '{print $1}'`
18
19 for i in `seq 1 $nu`
20
21 do
22
23 x=`sed -n "$i"p /tmp/value.txt|awk '{print $1}'`
24
25 y=`sed -n "$i"p /tmp/value.txt|awk '{print $2}'`
26
27 echo artifactItem:$x:$y
28
29 done
30
31 }
32
33
34
35 n2=$[$n/2]
36
37 for j in `seq 1 $n2`
38
39 do
40
41 m1=$[$j*2-1]
42
43 m2=$[$j*2]
44
45 nu1=`sed -n "$m1"p /tmp/line_number.txt`
46
47 nu2=`sed -n "$m2"p /tmp/line_number.txt`
48
49 nu3=$[$nu1+1]
50
51 nu4=$[$nu2-1]
52
53 get_value $nu3 $nu4
54
55 done
linux系统中,根目录/root/下有一个文件 ip-pwd.ini,内容如下
10.111.11.1,root,xyxyxy
10.111.11.1,root,xzxzxz
10.111.11.1,root,123456
10.111.11.1,root,xxxxxx
……
文件中每一行的格式都为linux服务器的ip root root密码 请用一个shell批量将这些服务器中的所有tomcat进程kill掉
讲解: 有了ip,用户名和密码,剩下的就是登录机器,然后执行命令了。批量登录机器,并执行命令,咱们课程当中有讲过一个expect脚本。所以本题就是需要这个东西来完成。
答案:
首先编辑expect脚本 kill_tomcat.expect
#!/usr/bin/expect
set passwd [lindex $argv 0]
set host [lindex $argv 1]
spawn ssh root@$host
expect {
"yes/no" { send "yes\r"; exp_continue}
"password:" { send "$passwd\r" }
}
expect "]*"
send "killall java\r"
expect "]*"
send "exit\r"
编辑完后需要给这个文件执行权限 chmod a+x kill_tomcat.expect
然后编辑shell脚本
#!/bin/bash
n=`wc -l ip-pwd.ini`
for i in `seq 1 $n`
do
ip=`sed -n "$n"p ip-pwd.ini |awk -F ',' '{print $1}'`
pw=`sed -n "$n"p ip-pwd.ini |awk -F ',' '{print $3}'`
./kill_tomcat.expect $pw $ip
done
查看test.txt文件中已aaa结尾的所有行。
答案:grep 'aaa$' test.txt
查找当前路径下文件名包含test的所有文件
答案:find ./ -name “*test*”
进入/home/imix目录创建 testing目录 并拷贝testing目录到/tmp下,并删除源目录
答案:
cd /home/imix
mkdir testing
cp -r testing /tmp/
rm -rf /home/imix/testing
输出当前路径下的文件详细信息并以空格分割打印第九个域并过滤包含agent字符串的结果
答案:ls -l |awk ‘{print $9}’ |grep ‘agent’
给test.sh文件可执行权限 给 check.sh文件同组和非同组用户读权限
答案:
chmod a+x test.sh
chown g+r,o+r check.sh
将当前服务器磁盘占用情况以GB的方式显示,并写入/tmp目录下的disk.txt文件
答案:df -h > /tmp/disk.txt
输出当前服务器上的时间信息,格式为 YYYYMMDD-HH:MM:DD
答案:date +%Y%m%d-%H:%M:%S
在当前服务器上查看远程服务器199.31.176.70上1521端口是否开通?
答案:telnet 199.31.176.70 1521
在当前用户创建一个计划任务 每周一到周五凌晨3点执行/home/imix下的app.sh脚本
答案:0 3 * * 1-5 /bin/sh /home/imix/app.sh
请使用条件函数if撰写一个shell函数 函数名为 f_judge,实现以下功能 当/home/log 目录存在时 将/home目录下所有tmp开头的文件或目录移至/home/log 目录。 当/home/log目录不存在时,创建该目录,然后退出。
答案:
#!/bin/bash
f_judge (){
if [ -d /home/log ]
then
mv /home/tmp* /home/log/
else
mkdir -p /home/log
exit
fi
}
统计ip访问情况,要求分析nginx访问日志,找出访问页面数量在前十位的ip
cat access.log | awk '{print $1}' | uniq -c | sort -rn | head -10
使用tcpdump监听主机为192.168.1.1,tcp端口为80的数据,同时将输出结果保存输出到tcpdump.log
tcpdump 'host 192.168.1.1 and port 80' > tcpdump.log
如何将本地80 端口的请求转发到8080 端口,当前主机IP 为192.168.2.1
iptables -A PREROUTING -d 192.168.2.1 -p tcp -m tcp -dport 80 -j DNAT-to-destination 192.168.2.1:8080
实时抓取并显示当前系统中tcp 80端口的网络数据信息,请写出完整操作命令
tcpdump -nn tcp port 80
查看http的并发请求数与其TCP连接状态
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
还有ulimit -n 查看linux系统打开最大的文件描述符,这里默认1024
不修改这里web服务器修改再大也没用,若要用就修改很几个办法,这里说其中一个:
修改/etc/security/limits.conf
soft nofile 10240
hard nofile 10240
重启后生效
用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}'| sort | uniq -c | sort -nr |head -20
写一个脚本,实现判断192.168.1.0/24网络里,当前在线的IP有哪些,能ping通则认为在线
#!/bin/bash
for ip in seq 1 255
do
{
ping -c 1 192.168.1.$ip > /dev/null 2>&1
if [ $? -eq 0 ]; then
echo 192.168.1.$ip UP
else
echo 192.168.1.$ip DOWN
fi
}&
done
wait
已知 apache 服务的访问日志按天记录在服务器本地目录/app/logs 下,由于磁盘空间紧张,现在要求只能保留最近 7 天的访问日志!请问如何解决? 请给出解决办法或配置或处理命令
创建文件脚本:
#!/bin/bash
for n in seq 14
do
date -s "11/0$n/14"
touch accesswww(date +%F).log
done
解决方法:
pwd/application/logs
find /application/logs/ -type f -mtime +7 -name "*.log"|xargs rm –f
也可以使用-exec rm -f {} \;进行删除
请执行命令取出 linux 中 eth0 的 IP 地址(请用 cut,有能力者也可分别用 awk,sed 命令答)
cut方法1:
ifconfig eth0|sed -n '2p'|cut -d ":" -f2|cut -d " " -f1
192.168.20.130
awk方法2:
ifconfig eth0|awk 'NR==2'|awk -F ":" '{print $2}'|awk '{print $1}'
192.168.20.130
awk多分隔符方法3:
ifconfig eth0|awk 'NR==2'|awk -F "[: ]+" '{print $4}'
192.168.20.130
sed方法4:
ifconfig eth0|sed -n '/inet addr/p'|sed -r 's#^.ddr:(.)Bc.*$#\1#g'
192.168.20.130
如何向脚本传递参数 ?
./script argument
例子: 显示文件名称脚本
./show.sh file1.txt
cat show.sh
#!/bin/bash
echo $1
如何在脚本中使用参数 ?
第一个参数 : $1,第二个参数 : $2
例子 : 脚本会复制文件(arg1) 到目标地址(arg2)
./copy.sh file1.txt /tmp/
cat copy.sh
#!/bin/bash
cp $1 $2
如何计算传递进来的参数 ?
$#
如何在脚本中获取脚本名称 ?
$0
如何检查之前的命令是否运行成功 ?
$?
如何获取文件的最后一行 ?
tail-1
如何获取文件的第一行 ?
head-1
如何获取一个文件每一行的第三个元素 ?
awk'{print $3}'
假如文件中每行第一个元素是 FIND,如何获取第二个元素
awk'{ if ($1 == "FIND") print $2}'
如何调试 bash 脚本
将 -xv 参数加到 #!/bin/bash 后
例子:
#!/bin/bash –xv
举例如何写一个函数 ?
function example {
echo "Hello world!"
}
如何向连接两个字符串 ?
V1="Hello"
V2="World"
V3=${V1}${V2}
echo $V3
输出
HelloWorld
如何进行两个整数相加 ?
V1=1
V2=2
let V3=$V1+$V2
echo $V3
输出
3
两个整数相加,还有若干种方法实现:
A=5
B=6
echo $(($A+$B)) # 方法 2
echo $[$A+$B] # 方法 3
expr $A + $B # 方法 4
echo $A+$B | bc # 方法 5
awk 'BEGIN{print '"$A"'+'"$B"'}' # 方法 6
如何检查文件系统中是否存在某个文件 ?
if [ -f /var/log/messages ]
then
echo "File exists"
fi
写出 shell 脚本中所有循环语法 ?
for 循环 :
foriin$(ls);do
echo item:$i
done
while 循环 :
#!/bin/bash
COUNTER=0
while [ $COUNTER -lt 10 ]; do
echo The counter is $COUNTER
let COUNTER=COUNTER+1
done
until 循环 :
#!/bin/bash
COUNTER=20
until [ $COUNTER -lt 10 ]; do
echo COUNTER $COUNTER
let COUNTER-=1
done
每个脚本开始的 #!/bin/sh 或 #!/bin/bash 表示什么意思 ?
这一行说明要使用的 shell。#!/bin/bash 表示脚本使用 /bin/bash。对于 python 脚本,就是 #!/usr/bin/python。
如何获取文本文件的第 10 行 ?
head -10 file|tail -1
bash 脚本文件的第一个符号是什么
#
命令:[ -z "" ] && echo 0 || echo 1 的输出是什么
0
命令 “export” 有什么用 ?
使变量在子 shell 中可用。
如何在后台运行脚本 ?
在脚本后面添加 “&”。
更好的答案是:
nohup command&
大部分时间我们可能是远程使用Linux,我碰到过由于网络断线使得在后台运行的command &没了...
"chmod 500 script" 做什么 ?
使脚本所有者拥有可执行权限。
">" 做什么 ?
重定向输出流到文件或另一个流。
& 和 && 有什么区别
& - 希望脚本在后台运行的时候使用它
&& - 当前一个脚本成功完成才执行后面的命令/脚本的时候使用它
什么时候要在 [ condition ] 之前使用 “if” ?
当条件满足时需要运行多条命令的时候。
命令: name=John && echo 'My name is $name' 的输出是什么
variable
bash shell 脚本中哪个符号用于注释 ?
#
命令: echo ${new:-variable} 的输出是什么
variable
' 和 " 引号有什么区别 ?
' - 当我们不希望把变量转换为值的时候使用它。
" - 会计算所有变量的值并用值代替。
如何在脚本文件中重定向标准输出和标准错误流到 log.txt 文件 ?
在脚本文件中添加 "exec >log.txt 2>&1" 命令。
如何只用 echo 命令获取字符串变量的一部分 ?
echo ${variable:x:y}
x - 起始位置
y - 长度
例子:
variable="My name is Petras, and I am developer."
echo ${variable:11:6} # 会显示 Petras
如果给定字符串 variable="User:123:321:/home/dir",如何只用 echo 命令获取 home_dir ?
echo ${variable#*:*:*:}
或
echo ${variable##*:}
如何从上面的字符串中获取 “User” ?
echo ${variable%:*:*:*}
或
echo ${variable%%:*}
如何使用 awk 列出 UID 小于 100 的用户 ?
awk -F: '$3<100' /etc/passwd
写程序为用户计算主组数目并显示次数和组名
cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g
do
{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2
done
如何在 bash shell 中更改标准的域分隔符为 ":" ?
IFS=":"
如何获取变量长度 ?
${#variable}
如何打印变量的最后 5 个字符 ?
echo ${variable: -5}
${variable:-10} 和 ${variable: -10} 有什么区别?
${variable:-10} - 如果之前没有给 variable 赋值则输出 10;如果有赋值则输出该变量
${variable: -10} - 输出 variable 的最后 10 个字符
如何只用 echo 命令替换字符串的一部分 ?
echo ${variable//pattern/replacement}
哪个命令将命令替换为大写 ?
tr '[:lower:]' '[:upper:]'
如何计算本地用户数目 ?
wc -l /etc/passwd|cut -d" " -f1 或者 cat /etc/passwd|wc -l
不用 wc 命令如何计算字符串中的单词数目 ?
set ${string}
echo $#
"export $variable" 或 "export variable" 哪个正确 ?
export variable
如何列出第二个字母是 a 或 b 的文件 ?
ls -d ?[ab]*
如何将整数 a 加到 b 并赋值给 c ?
c=$((a+b))
或
c=`expr $a + $b`
或
c=`echo "$a+$b"|bc`
如何去除字符串中的所有空格 ?
echo $string|tr -d " "
重写这个命令,将输出变量转换为复数: item="car"; echo "I like $item" ?
item="car"; echo "I like ${item}s"
写出输出数字 0 到 100 中 3 的倍数(0 3 6 9 …)的命令 ?
for i in {0..100..3}; do echo $i; done
或
for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
如何打印传递给脚本的所有参数 ?
echo $*
或
echo $@
[ $a == $b ] 和 [ $a -eq $b ] 有什么区别
[ $a == $b ] - 用于字符串比较
[ $a -eq $b ] - 用于数字比较
= 和 == 有什么区别
= - 用于为变量赋值
== - 用于字符串比较
写出测试 $a 是否大于 12 的命令 ?
[ $a -gt 12 ]
写出测试 $b 是否小于等于 12 的命令 ?
[ $b -le 12 ]
如何检查字符串是否以字母 "abc" 开头 ?
[[ $string == abc* ]]
[[ $string == abc* ]] 和 [[ $string == "abc*" ]] 有什么区别
[[ $string == abc* ]] - 检查字符串是否以字母 abc 开头
[[ $string == "abc" ]] - 检查字符串是否完全等于 abc
如何列出以 ab 或 xy 开头的用户名 ?
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
bash 中 $! 表示什么意思 ?
后台最近执行命令的 PID.
$? 表示什么意思 ?
前台最近命令的结束状态。
如何输出当前 shell 的 PID ?
echo $$
如何获取传递给脚本的参数数目 ?
echo $#
$* 和 $@ 有什么区别*
$* - 以一个字符串形式输出所有传递到脚本的参数
$@ - 以 $IFS 为分隔符列出所有传递到脚本中的参数
如何在 bash 中定义数组 ?
array=("Hi" "my" "name" "is")
如何打印数组的第一个元素 ?
echo ${array[0]}
如何打印数组的所有元素 ?
echo ${array[@]}
如何输出所有数组索引 ?
echo ${!array[@]}
如何移除数组中索引为 2 的元素 ?
unset array[2]
如何在数组中添加 id 为 333 的元素 ?
array[333]="New_element"
shell 脚本如何获取输入的值 ?
a) 通过参数
./script param1 param2
b) 通过 read 命令
read -p "Destination backup Server : " desthost
在脚本中如何使用 "expect" ?
/usr/bin/expect << EOD
spawn rsync -ar ${line} ${desthost}:${destpath}
expect "*?assword:*"
send "${password}\r"
expect eof
EOD
Shell脚本是什么、它是必需的吗?
答:一个Shell脚本是一个文本文件,包含一个或多个命令。作为系统管理员,我们经常需要使用多个命令来完成一项任务,我们可以添加这些所有命令在一个文本文件(Shell脚本)来完成这些日常工作任务。
什么是默认登录shell,如何改变指定用户的登录shell
答:在Linux操作系统,“/bin/bash”是默认登录shell,是在创建用户时分配的。使用chsh命令可以改变默认的shell。示例如下所示:
# chsh <username> -s <new_default_shell>
# chsh linuxtechi -s /bin/sh
可以在shell脚本中使用哪些类型的变量?
答:在shell脚本,我们可以使用两种类型的变量:
系统定义变量
用户定义变量
系统变量是由系统系统自己创建的。这些变量通常由大写字母组成,可以通过“set”命令查看。
用户变量由系统用户来生成和定义,变量的值可以通过命令“echo $<变量名>”查看。
如何将标准输出和错误输出同时重定向到同一位置?
答:这里有两个方法来实现:
方法一:
2>&1 (# ls /usr/share/doc > out.txt 2>&1 )
方法二:
&> (# ls /usr/share/doc &> out.txt )
shell脚本中“if”语法如何嵌套?
答:基础语法如下:
if [ Condition ]
then
command1
command2
…..
else
if [ condition ]
then
command1
command2
….
else
command1
command2
…..
fi
fi
shell脚本中“$?”标记的用途是什么? ?
答:在写一个shell脚本时,如果你想要检查前一命令是否执行成功,在if条件中使用“$?”可以来检查前一命令的结束状态。简单的例子如下:
root@localhost:~# ls /usr/bin/shar
/usr/bin/shar
root@localhost:~# echo $?
0
如果结束状态是0,说明前一个命令执行成功。
root@localhost:~# ls /usr/bin/share
ls: cannot access /usr/bin/share: No such file or directory
root@localhost:~# echo $?
2
如果结束状态不是0,说明命令执行失败。
在shell脚本中如何比较两个数字 ?
答:在if-then中使用测试命令( -gt 等)来比较两个数字,例子如下:
#!/bin/bash
x=10
y=20
if [ $x -gt $y ]
then
echo “x is greater than y”
else
echo “y is greater than x”
fi
shell脚本中break命令的作用 ?
答:break命令一个简单的用途是退出执行中的循环。我们可以在while和until循环中使用break命令跳出循环。
shell脚本中continue命令的作用 ?
答:continue命令不同于break命令,它只跳出当前循环的迭代,而不是整个循环。continue命令很多时候是很有用的,例如错误发生,但我们依然希望继续执行大循环的时候。
告诉我shell脚本中Case语句的语法 ?
答:基础语法如下:
case word in
value1)
command1
command2
…..
last_command
!!
value2)
command1
command2
……
last_command
;;
esac
shell脚本中while循环语法 ?
答:如同for循环,while循环只要条件成立就重复它的命令块。不同于for循环,while循环会不断迭代,直到它的条件不为真。基础语法:
while [ test_condition ]
do
commands…
done
如何使脚本可执行 ?
答:使用chmod命令来使脚本可执行。例子如下:
# chmod a+x myscript.sh
“#!/bin/bash”的作用 ?
答:#!/bin/bash是shell脚本的第一行,称为释伴(shebang)行。这里#符号叫做hash,而! 叫做 bang。它的意思是命令通过 /bin/bash 来执行。
shell脚本中for循环语法 ?
答:for循环的基础语法:
for variables in list_of_items
do
command1
command2
….
last_command
done
如何调试shell脚本 ?
答:使用'-x'参数(sh -x myscript.sh)可以调试shell脚本。另一个种方法是使用‘-nv'参数( sh -nv myscript.sh)。
shell脚本如何比较字符串?
答:test命令可以用来比较字符串。测试命令会通过比较字符串中的每一个字符来比较。
Bourne shell(bash) 中有哪些特殊的变量 ?
答:下面的表列出了Bourne shell为命令行设置的特殊变量。
内建变量
解释
$0
命令行中的脚本名字
$1
第一个命令行参数
$2
第二个命令行参数
…..
…….
$9
第九个命令行参数
$#
命令行参数的数量
$*
所有命令行参数,以空格隔开
How to test files in a shell script ?
在shell脚本中,如何测试文件 ?
答:test命令可以用来测试文件。基础用法如下表格:
Test
用法
-d 文件名
如果文件存在并且是目录,返回true
-e 文件名
如果文件存在,返回true
-f 文件名
如果文件存在并且是普通文件,返回true
-r 文件名
如果文件存在并可读,返回true
-s 文件名
如果文件存在并且不为空,返回true
-w 文件名
如果文件存在并可写,返回true
-x 文件名
如果文件存在并可执行,返回true
在shell脚本中,如何写入注释 ?
答:注释可以用来描述一个脚本可以做什么和它是如何工作的。每一行注释以#开头。例子如下:
#!/bin/bash
# This is a command
echo “I am logged in as $USER”
如何让 shell 就脚本得到来自终端的输入?
答:read命令可以读取来自终端(使用键盘)的数据。read命令得到用户的输入并置于你给出的变量中。例子如下:
# vi /tmp/test.sh
#!/bin/bash
echo ‘Please enter your name'
read name
echo “My Name is $name”
# ./test.sh
Please enter your name
LinuxTechi
My Name is LinuxTechi
如何取消变量或取消变量赋值 ?
答:“unset”命令用于取消变量或取消变量赋值。语法如下所示:
# unset <Name_of_Variable>
如何执行算术运算 ?
答:有两种方法来执行算术运算:
使用expr命令(# expr 5 + 2) 2.用一个美元符号和方括号($[ 表达式 ])例如:test=$[16 + 4] ; test=$[16 + 4]
do-while语句的基本格式 ?
答:do-while语句类似于while语句,但检查条件语句之前先执行命令(LCTT 译注:意即至少执行一次。)。下面是用do-while语句的语法
do
{
statements
} while (condition)
在shell脚本如何定义函数呢 ?
答:函数是拥有名字的代码块。当我们定义代码块,我们就可以在我们的脚本调用函数名字,该块就会被执行。示例如下所示:
$ diskusage () { df -h ; }
如何在shell脚本中使用BC(bash计算器) ?
答:使用下列格式,在shell脚本中使用bc:
variable=`echo “options; expression” | bc`
用sed修改test.txt的23行test为tset;
sed–i ‘23s/test/tset/g’ test.txt
查看/web.log第25行第三列的内容。
sed–n ‘25p’ /web.log | cut –d “ ” –f3
head–n25 /web.log | tail –n1 | cut –d “ ” –f3
awk–F “ ” ‘NR==23{print $3}’ /web.log
删除每个临时文件的最初三行。
sed–i ‘1,3d’ /tmp/*.tmp
脚本编程:求100内的质数。
#!/bin/bash
i=1
while[ $i -le 100 ];do
ret=1
for(( j=2;j<$i;j++ ));do
if [ $(($i%$j))-eq 0 ];then
ret=0
break
fi
done
if[ $ret -eq 1 ];then
echo-n "$i "
fi
i=$((i+1 ))
done
晚上11点到早上8点之间每两个小时查看一次系统日期与时间,写出具体配置命令
echo1 23,1-8/2 * * * root /tmp/walldate.sh >> /etc/crontab
编写个shell脚本将当前目录下大于10K的文件转移到/tmp目录下
#!/bin/bash
fileinfo=($(du./*))
length=${#fileinfo[@]}
for((i=0;i<$length;i=$((i+2 ))));do
if[ ${fileinfo[$i]} -le 10 ];then
mv ${fileinfo[$((i+1 ))]} /tmp
fi
done
如何将本地80端口的请求转发到8080端口,当前主机IP为192.168.2.1
/sbin/iptables-t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to 192.168.2.1:8080
/sbin/iptables-t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to 8080
在11月份内,每天的早上6点到12点中,每隔2小时执行一次/usr/bin/httpd.sh 怎么实现
echo"1 6-12/2 * * * root /usr/bin/httpd.sh >> /etc/crontab"
在shell环境如何杀死一个进程?
ps aux | grep ? | cut -f? 得到pid
cat/proc/pid
killpid
在shell环境如何查找一个文件?
find / -name abc.txt
在shell里如何新建一个文件?
touch ~/newfile.txt
linux下面的sed和awk的编写
1)如何显示文本file.txt中第二大列大于56789的行?
awk -F "," '{if($2>56789){print $0}}' file.txt
2)显示file.txt的1,3,5,7,10,15行?
sed -n "1p;3p;5p;7p;10p;15p" file.txt
awk 'NR==1||NR==3||NR==5||…||NR=15{print $0}' file.txt
3)将file.txt的制表符,即tab,全部替换成"|"
sed-i "s#\t#\|#g" file.txt
把当前目录(包含子目录)下所有后缀为“.sh”的文件后缀变更为“.shell”
#!/bin/bash
str=`find./ -name \*.sh`
fori in $str
do
mv$i ${i%sh}shell
done
编写shell实现自动删除50个账号功能,账号名为stud1至stud50
#!/bin/bash
for((i=1;i<=50;i++));do
userdel stud$i
done
请用Iptables写出只允许10.1.8.179 访问本服务器的22端口。
/sbin/iptables -A input -p tcp -dport 22 -s 10.1.8.179 -j ACCEPT
/sbin/iptables -A input -p udp -dport 22 -s 10.1.8.179 -j ACCEPT
/sbin/iptables -P input -j DROP
在shell中变量的赋值有四种方法,其中,采用name=12的方法称( A )。
A直接赋值 B使用read命令
C使用命令行参数 D使用命令的输出
有文件file1
1)查询file1里面空行的所在行号
grep -n ^$ file1
2)查询file1以abc结尾的行
grep abc$ file1
3)打印出file1文件第1到第三行
head -n3 file1
sed "3q" file1
sed -n "1,3p" file1
假设有一个脚本scan.sh,里面有1000行代码,并在vim模式下面,请按照如下要求写入对应的指令
1)将shutdown字符串全部替换成reboot
:%s/shutdown/reboot/g
2)清空所有字符
:%d
3)不保存退出
q!
1到10数字相加,写出shell脚本
#!/bin/bash
j=0
for((i=1;i<=10;i++));do
j=$[j+i ]
done
echo $j
常见shell有哪些?缺省的是哪个?
/bin/sh /bin/bash /bin/ash /bin/bsh /bin/csh /bin/tcsh /sbin/nologin
Shell循环语句有哪些?
for while until
用SHELL模拟LVS,脚本怎么写
/sbin/iptable -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to192.168.1.11-192.168.1.12
找出系统内大于50k,小于100k的文件,并删除它们。
#!/bin/bash
file=`find / -size +50k -size -100k`
for i in $file;do
rm -rf $i
done
脚本(如:目录dir1、dir2、dir3下分别有file1、file2、file2,请使用脚本将文件改为dir1_file1、dir2_file2、dir3_file3)
#!/bin/bash
file=`ls dir[123]/file[123]`
for i in $file;do
mv $i ${i%/*}/${i%%/*}_${i##*/}
done
将A 、B、C目录下的文件A1、A2、A3文件,改名为AA1、AA2、AA3.使用shell脚本实现。
#!/bin/bash
file=`ls [ABC]/A[123]`
for i in $file;do
mv $i ${i%/*}/A${i#*/}
done
每天晚上 12 点,打包站点目录/var/www/html 备份到/data 目录下(最好每次备份按时间生成不同的备份
cat a.sh
#/bin/bash
cd /var/www/ && /bin/tar zcf /data/html-date +%m-%d%H.tar.gz html/
crontab –e
00 00 * /bin/sh /root/a.sh
将/usr/local/test目录下大于100K 的文件转移到/tmp 目录下。
find /usr/local/test -type f -size +100k -exec mv {} /tmp \;
如何将本地80端口的请求转发到8080端口,当前主机IP为192.168.16.1,其中本地网卡eth0:
# iptables -t nat -A PREROUTING -d 192.168.16.1 -p tcp --dport 80 -j DNAT --to 192.168.16.1:8080
或者:
# iptables -t nat -A PREROUTING -i eth0 -d 192.168.16.1 -p tcp -m tcp --dport 80 -j REDIRECT --to-ports 8080
这个月内,每天的早上 6 点到 12 点中,每隔 2 小时创建一个test.txt文件,内容为ok,如何实现?
a、crontab -e 进入编辑模式
b、添加以下内容 0 6-12/2 * 4 * /bin/touch test.txt (以4月为例)
c、启动服务 service crontab start;chkconfig crontab on
linux系统中如何获取pid为100的进程所监听的tcp端口,请给出详细命令?
netstat -nlpt |grep 100
使用for循环在/oldboy目录下通过随机小写10个字母加固定字符串oldboy批量创建10个html文件,名称例如为:
root@oldboy oldboy]# sh /server/scripts/oldboy.sh
[root@oldboy oldboy]# ls
coaolvajcq_oldboy.html qnvuxvicni_oldboy.html vioesjmcbu_oldboy.html
gmkhrancxh_oldboy.html tmdjormaxr_oldboy.html wzewnojiwe_oldboy.html
jdxexendbe_oldboy.html ugaywanjlm_oldboy.html xzzruhdzda_oldboy.html
qcawgsrtkp_oldboy.html vfrphtqjpc_oldboy.html
[root@cjy linux-20]# vim 2.sh
#!/bin/bash
WORK_DIR=/oldboy/
create(){
i=1
while (($i<11))
do
cd $WORK_DIR && touch `tr -dc "a-z"</dev/urandom |head -c 10`_oldboy.html
i=$(($i+1))
done
}
check(){
if [ -d $WORK_DIR ];
then
create
else
mkdir $WORK_DIR
create
fi
}
check
[root@cjy linux-20]# ./2.sh
[root@cjy linux-20]# ls /oldboy/
daijyyadst_oldboy.html mjmcfvvjcq_oldboy.html qmgbrihbco_oldboy.html yrxovjbwlv_oldboy.html
djfhdphvqf_oldboy.html mohijpfehs_oldboy.html xdtspqouln_oldboy.html
gjczumsnfy_oldboy.html nfwzssqtus_oldboy.html yhqruiiota_oldboy.htm
请用至少两种方法实现!
将以上文件名中的oldboy全部改成oldgirl(用for循环实现),并且html改成大写
[root@cjy linux-20]# vim 3_1.sh
#!/bin/bash
change_name(){
DIR=/oldboy
FILE=`ls /oldboy`
GIRL=_oldgirl.HTML
for i in $FILE
do
c=`echo $i | cut -c 1-10`
mv $DIR/$c* $DIR/$c$GIRL
done
}
change_name
[root@cjy linux-20]# vim 3_2.sh
#!/bin/bash
change_name(){
DIR=/oldboy
FILE=`ls /oldboy`
GIRL=_oldgirl.HTML
for i in $FILE
do
c=`echo $i | awk -F '_' '{print $1}'`
mv $DIR/$c* $DIR/$c$GIRL
done
}
change_name
[root@cjy linux-20]# ./3_1.sh
[root@cjy linux-20]# ls /oldboy/
daijyyadst_oldgirl.HTML mjmcfvvjcq_oldgirl.HTML qmgbrihbco_oldgirl.HTML yrxovjbwlv_oldgirl.HTML
djfhdphvqf_oldgirl.HTML mohijpfehs_oldgirl.HTML xdtspqouln_oldgirl.HTML
gjczumsnfy_oldgirl.HTML nfwzssqtus_oldgirl.HTML yhqruiiota_oldgirl.HTML
批量创建10个系统帐号oldboy01-oldboy10并设置密码(密码为随机8位字符串)。
#!/bin/bash
for i in `seq 01 10`
do
useradd oldboy$i
password=`head -c 500 /dev/urandom | md5sum | head -c 8`
echo $password|passwd --stdin oldboy$i
done
四剑客面试题
find
1、找出/tmp目录下,属主不是root,且文件名不以f开头的文件
解:find /tmp/ ! \( -user root -o -name "f*" \)
2、查找/etc/下,除/etc/sane.d目录的其它所有.conf后缀的文件
解:find /etc/ -path /etc/sane.d -a -prune -o -name "*.conf"
3、查找/etc/下,除/etc/sane.d目录和/etc/fonts目录的其他所有.conf后缀的文件
解:find /etc/ \( -path /etc/sane.d -o -path /etc/fonts \) -a -prune -o -name "*.conf
4、查找/var目录下属主为root,且属组为mail的所有文件
解:find /var -user root -a -group mail
5、查找/var目录下不属于root、lp、gdm的所有文件
解:find /var ! \( -user root -o -user lp -o -user gdm \)
6、查找/var目录下最近一周内其内容修改过,同时属主不为root,也不是postfix的文件
解:find /var -mtime -8 ! \( -user root -o -name "postfix" \) -ls
7、查找当前系统上没有属主或属组,且最近一个周内曾被访问过的文件
解:find / -nouser -nogroup -atime -8
8、查找/etc目录下大于1M且类型为普通文件的所有文件
解:find /etc -size +1M -type f
9、查找/etc目录下所有用户都没有写权限的文件
解:find /etc -perm 444
10、查找/etc目录下至少有一类用户没有执行权限的文件
解:find /etc ! -perm /222
11、查找/etc/init.d目录下,所有用户都有执行权限,且其它用户有写权限的文件
解:find /etc/init.d -perm -111 -perm -002
学习grep、sed、awk之前,肯定是要先了解正则表达式。

学习之前,我们要先建立两个文件来练习。
vim a.txt
cp /etc/passwd passwd
grep和正则表达式
一、 正则表达式
1、单个字符
特定字符:某个具体字符(grep '1' passwd)
范围内字符: []括号里边代表的是1个字符。
数字字符:[0-9],[259]
小写字符:[a-z]
大写字符:[A-Z]
例:
grep '[0-9]' passwdgrep '[259]' passwd
grep '[a-z]' passwd
grep '[a-zA-Z]' passwd (包括所有字母)
反向字符:^
取反:[^0-9] , [^0] (‘^’一定要放倒中括号里边才行)
grep '[^0-9]' passwd(过滤以数字开头的行)
任意字符: .
.代表任何1个字符。
2、边界字符:头尾字符
^:表示以某字符开头。(注意[^]的意思是取反)
$:表示以某字符结尾。
例如:grep '^root' passwdgrep 'bash$' passwd
^$:表示空行。
元字符(代表普通字符或特殊字符)
\w:匹配任何字类字符(数字、字母、下划线)
\W: 匹配任何非字类字符(数字、字母、下划线)
\b:代表单词分隔
例:grep '\w' passwd
grep '\W' passwd
grep '\bx\b' passwd
字符串 ‘root’‘1000’‘n…x’
[A-Z][a-z]:匹配出挨在一起的2个大小字母,如Gz、Af、Td
[0-9][0-9]:匹配挨在一起的2位数,如45,56,28,96
3、重复字符
*:0次或者多次匹配前面的字符
+:1次或者多次匹配前面的字符(+不能直接用,需要加\来转义)
?:0次或1次匹配前面的字符(?不能直接用,需要加\来转义)
例:grep 'se*' a.txt
grep 'se\+' a.txt
grep 'se\?' a.txt
如果要匹配多字符重复,需要用括号将多字符括起来。
例:
grep '\(se\)*' a.txt 注意()不能直接使用,需要转义,前边加\。
重复特定次数: {n,m} 代表重复n-m次
那么我们就可以这样理解为:
*:{0,1}
+:{1,}
?: {0,1}
例:过滤重复数字2-3次的行
grep '[0-9]\{2,3\}' passwd 注意:{}也是需要转义的符号,前边加\.
任意字符串的表示: .*
例:^r.* 表示以r开头的任意字符串。
n.*x:表示n和x之间有任意个字符
n...x:表示n和x之间有3个任意字符
逻辑或: | (也是需要转义,前边加\)
例:过滤掉#开头的行和空行
grep -v '^$\|^#' nginx.conf(-v是取反的意思)
案例:
1、 匹配4-10位的QQ号码
grep '^[0-9]\{4,10\}$' a.txt
2、 匹配15或者18位×××号(支持带X的)
分析,×××开始位不能为0,结尾包括x,中间部分是13位或16数字重复。(注意转义符号)
grep '^[1-9]\([0-9]\{13\}\|[0-9]\{16\}\)[0-9xX]$' a.txt
3、 匹配密码(由数字、字母和下划线组成)
grep '^\w\+$' a.txt
说明:
grep高亮显示:grep =’grep –color=auto’这样写只是临时生效,断开重新连接后就不行了。如果想永久生效,可以写进全局变量文件中:/etc/profile
在文件的结尾添加:
alias grep='grep --color=auto'
[root@rescue ~]# source /etc/profile
这样就可以了。
巧妙破解sed
1、 sed是如何进行文本处理的?

(1)命令行格式
sed [options] ‘command’ file(s)
optiones(选项): -e ; -n
command命令:行定位(正则)+sed命令(操作)
1、sed操作命令
-p 打印相关的行,要和-n参数一起使用。
例:sed -n 'p' passwd如果不加-n会每行显示两次。
定位1行:x或/正则/ 用x(代表数字)或者正则表达式来定位,正则两边要加/隔开。
例:打印第10行的内容。
sed -n '10p' passwd
sed -n '/redis/p' passwd
定位多行:x,y 或者/正则/
例:打印10-20行的内容:
nl passwd |sed -n '10,20p'
nl passwd |sed -n '/uucp/,/redis/p'两个例子的效果是一样的。
打印除第10行的所有内容:用“!”
nl passwd |sed -n '10!p'
打印除10-20的所有行:
nl passwd |sed -n '10,20!p'
定位间隔几行:x~y
例:间隔5行打印
nl passwd |sed -n '1~5p'
基本操作命令(2)
a(新增行)
i (插入行)
c(替代行)
d(删除行)
例:在第5行后面增加“=========”
nl passwd |sed '5a =========='
在1-5行后分辨增加“=========”
nl passwd |sed '1,5a =========='
在第5行前面插入“=========”
nl passwd |sed '5i =========='
在1-5行前分辨插入“=========”
nl passwd |sed '1,5i =========='
替换22行内容为“11111”
nl passwd | sed '22c 11111'
22-24行替换为“11111”
nl passwd | sed '20,24c 111111111
删除“redis”行
nl passwd |sed '/redis/d'
实战应用一:优化服务器配置
在ssh的配置文件行尾加入相应文本:
Port 52112
PermitRootLogin no
[root@rescue ~]# sed '$a \ Port 52112 \n PermitRootLogin no' ssh_config
解释一下:
$a代表在行尾增加
\Port 52112:在前边加“\和两个空格是为了对齐,\为转义符”
\n:表示回车
如果:[root@rescue ~]# sed -i '$a \ Port 52112 \n PermitRootLogin no' ssh_config
其中-i表示直接修改源文件
实例2、删除a.txt文本中的空行
sed '/^$/d' a.txt由于^$属于正则,所以要用//隔离起来。
实例3、服务器日志处理
找出log日志中error信息。
sed -n '/error/p' secure
基本操作命令(2)
-s(替换):原内容/,#替换后内容,其中/,#随便一个都可以
例:将passwd文件中的nologin全部替换为qqqqq
sed 's/nologin/qqqqqqqqqq/' passwd
-g(全局)
例:将passwd文件中所有的:替换为%
sed 's/:/%/g' passwd
实战应用:
筛选数据,筛选出eth0的ip。(思路,将IP前后的内容全部替换为空)
ifconfig eth0 |sed -n '/inet/p' |sed 's/inet.*r://'|sed 's/B.*$//'
高级操作命令:
{}:多个sed命令同时使用,用;分开
例如:在passwd文件中删除20-24行,并替换nologin为qqq
nl passwd |sed '{20,24d;s/nologin/qqqq/}'
n:读取下一个输入行(用下一个命令处理)
例如:打印偶数行:
nl passwd |sed -n '{n;p}'或:nl passwd |sed -n '1~2p'
打印奇数行:
nl passwd |sed -n '{p;n}'或nl passwd |sed -n '2~2p'
&:替换固定字符串
例:passwd文件中的用户名后边加空格
sed 's/^[a-z_-]\+/& ' passwd
解释:
^[a-z_-]的意思是以a-z任意字母开头后边跟横线的内容
+的意思是重复1或者多次。
&的后边跟着一个空格,&代表的是前面^[a-z_-]。
大小写转换
\u 表示对首字母转换为大写
\l 对首字母转换为小写
\U 对一串字符转换成大写
\L 对一串字符转换成小写
案例一:将用户名的首字母转换为大写
[root@rescue ~]# sed 's/^[a-z_-]\+/\u/' passwd
\( \) 替换某种(部分)字符串 \1,\2
\1就代表第一个括号中的内容,\2就代表第二个括号中的内容
例:获取eth0网卡的IP地址
ifconfig eth0 |sed -n '/inet/p' |sed 's/ine.*r:\([0-9.]\+\) .*$/\1/'
r:复制指定文件插入到匹配行
w:复制匹配行拷贝指定文件里
例:文件123.txt
[root@rescue ~]# cat 123.txt
3823098908230
3823232343
833121332文件abc.txt
[root@rescue ~]# cat abc.txt
dasajlkl
asgfsdfsfsd
ferewejlfdas
现将读取123.txt的内容插入到abc.txt的第一行之后
sed '1r 123.txt' abc.txt
复制123.txt内容到abc.txt的第一行之后
sed '1w abc.txt' 123.txt
q:退出sed
例:匹配到第10行后退出sed
nl passwd |sed '10q'
轻松玩转awk
awk是一款文本与数据处理工具,可以统计、制表、编程等。
命令格式:
awk [option] ‘command’ file
awk的内置参数一:
$0: 表示当前整个行
$1: 每行第一个字段
$2: 每行第二个字段
$3: 每行第三个字段
分隔符: -F
例:打印passwd文件中的用户名一列
awk -F ':' '{print $1}' passwd
打印用户名和UID两列
awk -F ':' '{print $1,$3}' passwd 打印两项内容用都好隔开
或:awk -F ':' '{print $1" "$3}' passwd 双引号中间加一个空格。
增加用户名和UID两列说明字符:
awk -F ':' '{print "User:"$1"\t""UID:"$3}' passwd
“User:”和”UID”是$1和$3前边增加的说明,”\t”表示的是table键。
awk的内置参数二:
NR:行号,每行的记录号
NF:列号,字段数量变量
FILENAME:正在处理的文件名
例:
[root@rescue ~]# awk -F ':' '{print NR,NF}' passwd
案例一:
显示/etc/passwd每行的行号,每行的列数,对应行的用户名(两种方法:print,printf)
方法一:awk -F ':' '{print "Line:"NR, "Col:"NF,"User:"$1}' passwd
标红部分都是字段的说明,用引号引起来。
方法二:awk -F ':' '{printf("Line:%s Col:%s User:%s\n",NR,NF,$1)}' passwd
\n表示回车符,不加的话不会断行。
案例二:
显示/etc/passwd中用户ID大于100的行号和用户名 (使用if….else)
awk -F ':' '{if ($3>100) print "Line:"NR,"User:"$1}' passwd
案例三:
在服务器log中找出“error”的发生日期
方法一:sed -n '/error/p' secure | awk '{print $1,$2,$3}'
方法二:awk '/error/{print $1,$2,$3}' secure
awk——逻辑判断式
~:匹配正则表达式
!~:不匹配正则表达式
==: 等于
!=:不等于
<:小于
>:大于
例1:匹配passwd文件第一个字段是否为m,是m则打印出来
awk -F ':' '$1~/^m.*/{print $1}' passwd
例2:匹配passwd文件中UID大于100的则输出用户名和UID
awk -F ':' '$3>100{print $1,$3}' passwd
awk——扩展格式
BEDIN{print “start”} command END {PRINT “END”}
例:
awk -F ':' 'BEGIN{print "Line Col User"}{print NR,NF,$1}END{print"-----"FILENAME"-----"}' passwd
awk处理过程
案例一:统计当前文件夹下的文件/文件夹占用的大小
ls -l |awk 'BEGIN{size=0}{size+=$5}END{print "size is " size/1024/1024"M"}'
案例二:统计显示/etc/passwd的账户总人数
awk -F ':' 'BEGIN{count=0}$1!~/^$/{count++}END{print " count = "count}' passwd