这次带大家完成一个zookeeper分布式集群的搭建。
zookeeper是什么:
ZooKeeper是一个集中的服务,用于维护配置信息、命名、提供分布式同步和提供组服务。每次实现这些服务时,都有许多工作需要解决不可避免的错误和竞争条件。在实现这类服务的过程中,应用程序通常会忽略这些服务,这使得它们在发生变化时变得脆弱,并且难以管理。即使正确地执行这些服务,在部署应用程序时,这些服务的不同实现也会导致管理的复杂性。
简单的说就是:
一致,有头,数据树
zookeeper的用途:
#解决分布式系统数据的一致性问题(Consistency ACID)
#协调一堆动物
#hadoop/impala/shark/hive/…
#mahout
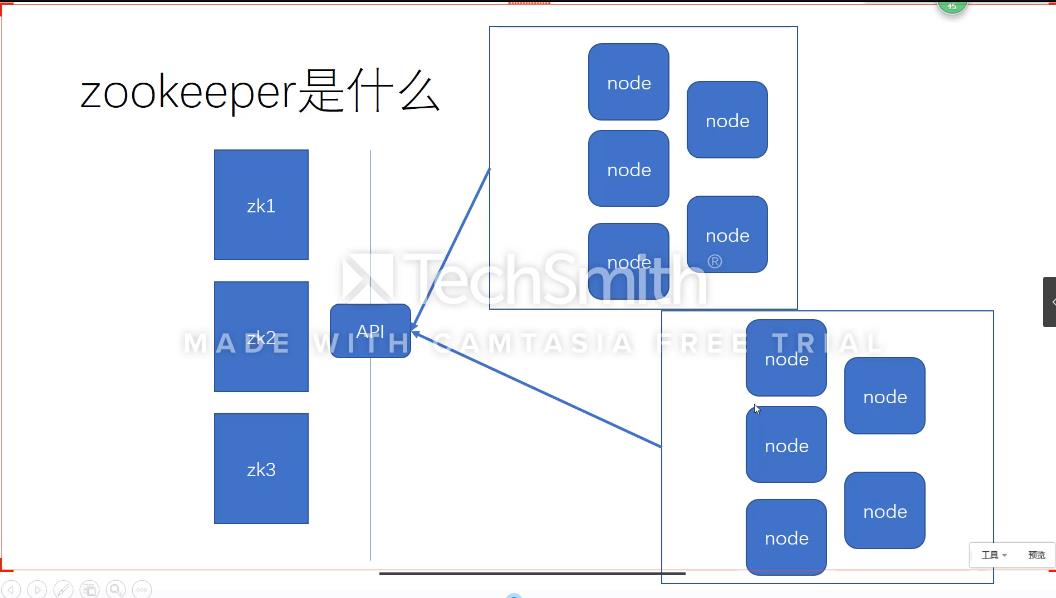
zookeeper集群的结构:
有一台机器是leader 剩下的都是follower(建议单间zookeeper集群的个数为单数,最少3台)

分布式的来源:
google的三篇论文
| 文章 | 衍生的技术 |
|---|---|
| GFS | HDFS |
| BigTable | HBase |
| MapReduce | HadoopMR |
步骤:
-
下载zookeeper,建议下载1.4.10版较稳定
-
上传到liunx虚拟机上
-
解压
命令:tar axvf 文件名.tar.gz (自行放置)
解压后目录:

-
scp -r 拷贝到三台机器
拷贝除一个文件用做更改配置文件:
cp zoo_sample.cfg zoo.cfg -
配置:
更改配置文件:
vim zoo.cfg
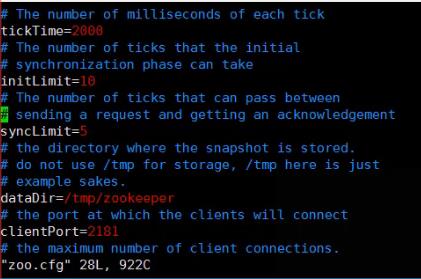
配置文件内容:
tickTime=2000:是一个计时单位,两秒钟一个计时单位
initLimit=10:有多少个计时单位,10个就是10乘以2000,也就是20秒
dataDir=/tam/zookeeper:zookeeper在硬盘上存储数据的地方
clientport=2181:客户端端口是2181
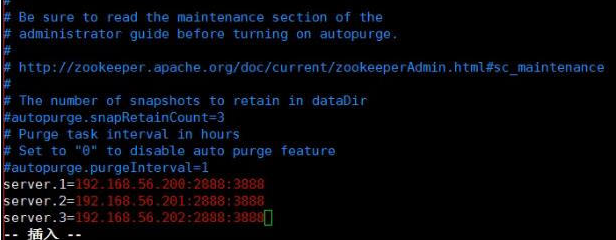
在文件的末尾加上三台虚拟机的IP地址:
:2888:3888为端口号
Server.1对应的是0号机
Server.2对应的是1号机
Server.3对应的是2号机
然后是更改各个虚拟机的myid:
vim myid
写入对应的ID好即可,Server.1对应的是0号机,在0号机的myid内写上1 即可
每台都需要更改
- 启动
执行vim myid以下的命令,到达bin目录下执行:
./zkServer.sh start 启动zookeeper
-
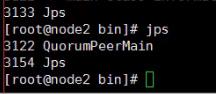
观察是否启动:
jps
出现QuorumPeerMain证明已启动
-
关闭
./zkServer.sh stop
-
观察运行状态:
bin/zkServer.sh status

-
创建一个节点命令:
create /app/config
-
zookeeper的API
zookeeper提供的一个API,不同的集群可以通过API去访问更改zookeeper数据树
zookeeper的应用场景:
#配置一致
#HA
#pub/sub
#naming service
#load balance
#分布式锁
…
下面我们写代码
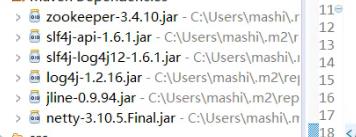
加入jar包:
这些jar包都是运行zookeeper所需要的
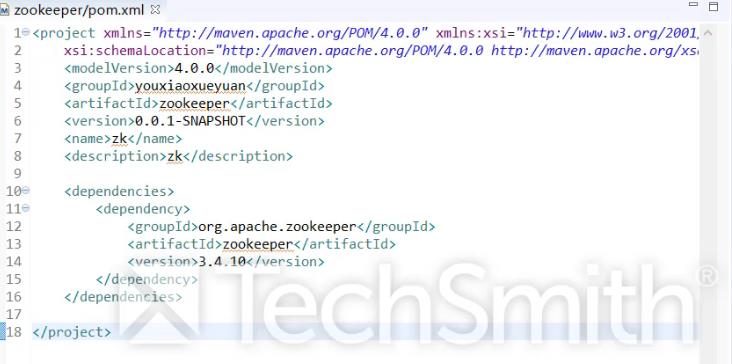
zookeeper的.xml文件:
写一个从远程连接zookeeper的小程序:
public class ZKClient{
public static void main(String[] args){
String CONN = "192.168.56.2181:200,192.168.56.201:2181,192.168.56.202:2181";
Zookeeper zk = new Zookeeper(CONN,5000,null);
//睡三秒钟等待zookeeper的连接
Thread.sleep(3000);
zk.create("/yxxy","yxxy".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);
//在睡两秒
Thread.sleep(2000);
//关闭连接
zk.close();
}
}
感谢各位看官老爷的关注,乐于分享,起因热爱;我是可爱的马小七!咱们下节再见!