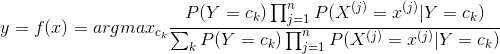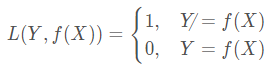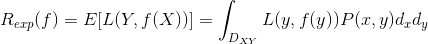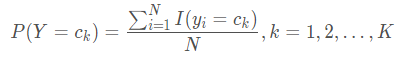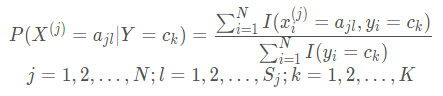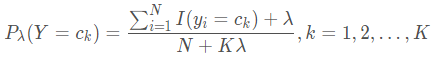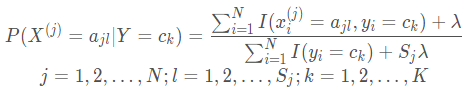(1)条件概率 :设A,B是两个事件,且P(A)>0,称
P
(
B
∣
A
)
=
P
(
A
B
)
P
(
A
)
P(B|A) = \frac {P(AB)}{P(A)}
P ( B ∣ A ) = P ( A ) P ( A B )
(2)乘法定理 :设P(A)>0,称
P
(
A
B
)
=
P
(
B
∣
A
)
P
(
A
)
P(AB) = {P(B|A)}{P(A)}
P ( A B ) = P ( B ∣ A ) P ( A )
(3)全概率公式 :设B1,B2,…,Bn是样本空间S的一个全划分,则:
P
(
A
)
=
P
(
A
∩
S
)
=
P
(
A
∩
(
B
1
∪
B
2
∪
.
.
.
∪
B
n
)
)
=
P
(
A
∩
B
1
)
+
P
(
A
∩
B
2
)
+
.
.
.
+
P
(
A
∩
B
n
)
=
P
(
A
∣
B
1
)
P
(
B
1
)
+
P
(
A
∣
B
2
)
P
(
B
2
)
+
.
.
.
+
P
(
A
∣
B
n
)
P
(
B
n
)
P(A)=P(A\cap S) \\ =P(A\cap(B1\cup B2\cup ...\cup Bn)) \\ =P(A\cap B1)+P(A\cap B2)+...+P(A\cap Bn) \\ =P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)P(Bn)
P ( A ) = P ( A ∩ S ) = P ( A ∩ ( B 1 ∪ B 2 ∪ . . . ∪ B n ) ) = P ( A ∩ B 1 ) + P ( A ∩ B 2 ) + . . . + P ( A ∩ B n ) = P ( A ∣ B 1 ) P ( B 1 ) + P ( A ∣ B 2 ) P ( B 2 ) + . . . + P ( A ∣ B n ) P ( B n )
(4)贝叶斯定理 :根据条件概率的定义,事件 A 发生的条件下事件 B 发生的概率、事件 B 发生的条件下事件 A 发生的概率分别为:
P
(
B
∣
A
)
=
P
(
A
B
)
P
(
A
)
P(B|A) = \frac {P(AB)}{P(A)}
P ( B ∣ A ) = P ( A ) P ( A B )
P
(
A
∣
B
)
=
P
(
A
B
)
P
(
B
)
P(A|B) = \frac {P(AB)}{P(B)}
P ( A ∣ B ) = P ( B ) P ( A B )
结合这两个方程式,我们可以得到:
P
(
B
∣
A
)
P
(
A
)
=
P
(
A
B
)
=
P
(
A
∣
B
)
P
(
B
)
{P(B|A)}{P(A)} = P(AB) = {P(A|B)}{P(B)}
P ( B ∣ A ) P ( A ) = P ( A B ) = P ( A ∣ B ) P ( B )
上式两边同除以 P(B),若P(B)>0,我们可以得到贝叶斯定理:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P(A|B) = \frac {{P(B|A)}{P(A)}}{P(B)}
P ( A ∣ B ) = P ( B ) P ( B ∣ A ) P ( A )
P(A)是 A 的先验概率,之所以称为“先验”是因为它不考虑任何 B 方面的因素。
输入: 训练数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
T= \{(x_{1},y_{1}),(x_{2},y_{2}),...,(x_{N},y_{N})\}
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) }
x
i
=
(
x
i
(
1
)
,
x
i
(
2
)
,
.
.
.
,
x
i
(
n
)
)
T
x_{i}=(x_{i}^{(1)},x_{i}^{(2)},...,x_{i}^{(n)})^{T}
x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( n ) ) T
输出: 类标记
y
=
{
c
1
,
c
2
,
.
.
.
,
c
k
}
y = \{c_{1},c_{2},...,c_{k}\}
y = { c 1 , c 2 , . . . , c k }
朴素贝叶斯法通过训练数据集学习联合概率分布P(X,Y):
先验概率分布 :
P
(
Y
=
c
k
)
P(Y=c_{k})
P ( Y = c k ) 条件概率分布 :
P
(
X
=
x
∣
Y
=
c
k
)
=
P
(
X
(
1
)
=
x
(
1
)
,
X
(
2
)
=
x
(
2
)
,
.
.
.
,
X
(
n
)
=
x
(
n
)
∣
Y
=
c
k
)
P(X=x | Y=c_{k}) \\= P(X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},...,X^{(n)}=x^{(n)} | Y=c_{k})
P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , X ( 2 ) = x ( 2 ) , . . . , X ( n ) = x ( n ) ∣ Y = c k )
朴素贝叶斯法假设各个特征之间相互独立,即用于分类的特征在类确定的条件下都是相互独立的,具体条件独立性假设 :
P
(
X
=
x
∣
Y
=
c
k
)
=
P
(
X
(
1
)
=
x
(
1
)
,
X
(
2
)
=
x
(
2
)
,
.
.
.
,
X
(
n
)
=
x
(
n
)
∣
Y
=
c
k
)
=
∏
j
=
1
n
P
(
X
(
j
)
=
x
(
j
)
∣
Y
=
c
k
)
P(X=x | Y=c_{k}) \\ = P(X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},...,X^{(n)}=x^{(n)} | Y=c_{k}) \\ = \prod_{j=1}^{n}P(X^{(j)}=x^{(j)}|Y=c_{k})
P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , X ( 2 ) = x ( 2 ) , . . . , X ( n ) = x ( n ) ∣ Y = c k ) = ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k )
朴素贝叶斯法分类时,对于给定输入的特征x,根据贝叶斯定理 计算后验概率
P
(
Y
=
c
k
∣
X
=
x
)
P(Y=c_{k}|X=x)
P ( Y = c k ∣ X = x )
朴素贝叶斯分类器 :
y
=
a
r
g
m
a
x
c
k
P
(
Y
=
c
k
)
∏
j
=
1
n
P
(
X
(
j
)
=
x
(
j
)
∣
Y
=
c
k
)
y=argmax_{c_{k}}P(Y=c_{k})\prod_{j=1}^{n}P(X^{(j)}=x^{(j)}|Y=c_{k})
y = a r g m a x c k P ( Y = c k ) ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k )
朴素贝叶斯法将实例分到后验概率最大的类中,如何得到最好的分类结果,只有损失函数值越小模型效果越好,等价于期望风险最小化,假设选取0-1损失函数 :
定义损失函数
L
(
Y
,
f
(
X
)
)
L(Y,f(X))
L ( Y , f ( X ) ) 期望风险函数 为
R
e
x
p
(
f
)
R_{exp}(f)
R e x p ( f )
H
(
X
)
=
∫
D
Y
L
(
y
,
f
(
y
)
)
P
(
y
∣
x
)
d
y
H(X)=\int_{D_{Y}}L(y,f(y))P(y|x)d_{y}
H ( X ) = ∫ D Y L ( y , f ( y ) ) P ( y ∣ x ) d y
那么期望风险函数可表示为:
R
e
x
p
(
f
)
=
E
[
L
(
Y
,
f
(
X
)
)
]
=
∫
D
X
H
(
X
)
∗
P
(
x
)
d
x
R_{exp}(f)=E[L(Y,f(X))]=\int_{D_{X}}H(X)*P(x)d_{x}
R e x p ( f ) = E [ L ( Y , f ( X ) ) ] = ∫ D X H ( X ) ∗ P ( x ) d x
我们发现上述推导得到的积分函数中,H(x)中的各项及P(x)都大于0 ,所以积分过程中不存在积分域内的两块积分相减的情况,因此,求期望风险最小化,就等价于求H(x)P(x)的最小值 。对于任意的一个x,P(X=x)为常数,那么最小值一定是在H(x)取最小值的时候取到 。因此对期望风险函数的求解可以转为所谓的求条件期望的最小值 :
H
(
X
)
=
∫
D
Y
L
(
y
,
f
(
y
)
)
P
(
y
∣
x
)
d
y
H(X)=\int_{D_{Y}}L(y,f(y))P(y|x)d_{y}
H ( X ) = ∫ D Y L ( y , f ( y ) ) P ( y ∣ x ) d y
而对于离散型随机变量,H(X) 可以转化为:
H
(
X
)
=
∑
k
=
1
K
[
L
(
c
k
,
f
(
X
)
)
]
P
(
c
k
∣
X
)
H(X)=\sum_{k=1}^{K}[L(c_{k},f(X))]P(c_{k}|X)
H ( X ) = ∑ k = 1 K [ L ( c k , f ( X ) ) ] P ( c k ∣ X )
取条件期望:
R
e
x
p
(
f
)
=
E
X
∑
k
=
1
K
[
L
(
c
k
,
f
(
X
)
)
]
P
(
c
k
∣
X
)
R_{exp}(f)=E_{X}\sum_{k=1}^{K}[L(c_{k},f(X))]P(c_{k}|X)
R e x p ( f ) = E X ∑ k = 1 K [ L ( c k , f ( X ) ) ] P ( c k ∣ X )
为了使期望风险最小化,只需要求条件期望的最小值,只需对X=x逐个极小化,由此得到:
f
(
x
)
=
a
r
g
m
a
x
c
k
P
(
c
k
∣
X
=
x
)
f(x)=argmax_{c_{k}}P(c_{k}|X=x)
f ( x ) = a r g m a x c k P ( c k ∣ X = x )
朴素贝叶斯法中,学习就是估计
P
(
Y
=
c
k
)
P(Y=c_{k})
P ( Y = c k )
P
(
X
(
j
)
=
x
(
j
)
∣
Y
=
c
k
)
P(X^{(j)}=x^{(j)}|Y=c_{k})
P ( X ( j ) = x ( j ) ∣ Y = c k )
先验概率
P
(
Y
=
c
k
)
P(Y=c_{k})
P ( Y = c k )
条件概率
P
(
X
(
j
)
=
a
j
l
∣
Y
=
c
k
)
P(X^{(j)}=a_{jl}|Y=c_{k})
P ( X ( j ) = a j l ∣ Y = c k )
x
i
(
j
)
x_{i}^{(j)}
x i ( j )
x
i
(
j
)
ϵ
{
a
j
1
,
a
j
2
,
.
.
.
,
a
j
s
j
}
x_{i}^{(j)}\epsilon \left \{ a_{j1},a_{j2},...,a_{js_{j}} \right \}
x i ( j ) ϵ { a j 1 , a j 2 , . . . , a j s j }
a
j
l
a_{jl}
a j l
先验概率
P
(
Y
=
c
k
)
P(Y=c_{k})
P ( Y = c k )
条件概率
P
(
X
(
j
)
=
a
j
l
∣
Y
=
c
k
)
P(X^{(j)}=a_{jl}|Y=c_{k})
P ( X ( j ) = a j l ∣ Y = c k )
λ
≥
0
\lambda\geq0
λ ≥ 0
λ
\lambda
λ 这样就弥补了极大似然估计可能会出现所要估计的概率值为0的缺陷 。当
λ
=
0
\lambda=0
λ = 0
λ
=
1
\lambda=1
λ = 1
有关极大似然估计法、贝叶斯估计法推导证明 朴素贝叶斯法中的概率公式请参照以下博客:证明朴素贝叶斯法中的概率估计公式
到此,朴素贝叶斯基本原理介绍完毕,如有错误欢迎指正,下节将将介绍python如何实现朴素贝叶斯分类算法及应用实例。
参考资料:李航《统计学习方法》