Pascal VOC 数据集的下载
# 下载2007年的训练数据
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
# 下载2007年的测试数据
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# 下载2012年的训练数据
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
http://academictorrents.com/details/df0aad374e63b3214ef9e92e178580ce27570e59
#各版本下载
http://bendfunction.f3322.net:666/share/Pascal%20VOC/下载好数据集后,解压后的目录如下所示:
VOCdevkit文件夹
数据集下载后解压得到一个名为VOCdevkit的文件夹,该文件夹结构如下:
└── VOCdevkit #根目录
└── VOC2012 #数据的年份,这里只下载了2012的,还有2007等其它年份的
├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一张图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages #存放源图片
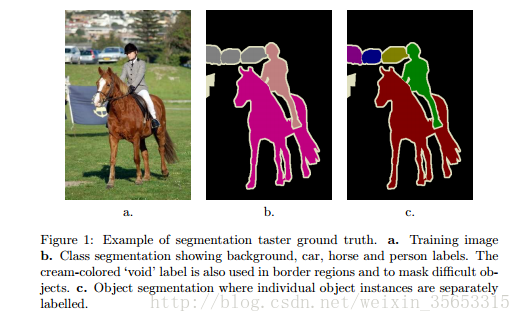
├── SegmentationClass #存放的是图片,分割后的效果,见下图
└── SegmentationObject #存放的是图片,分割后的效果,见下图

这里大概介绍一下各个文件夹的内容,更细节的介绍将在后文给出:
--Annotation文件夹存放xml文件,该文件是对图片的解释,每张图片都对于一个同名的xml文件。
--ImageSets文件夹存放txt文件,这些txt将数据集的图片分成了各种集合。如Main下的train.txt中记录的是用于训练的图片集合 -
--JPEGImages文件夹存放的是元数据集。
--SegmentationClass文件夹存放的图片标注出每一个像素的类别
--SegmentationObject文件夹存放的图片标注出每一个像素属于哪一个物体
Pascal VOC 数据集简介
做深度学习目标检测方面的开发者都会接触到PASCAL VOC这个数据集。一般都会按照它的格式准备自己的数据集。 PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。VOC2012:对于检测任务,VOC2012的trainval/test包含08-11年的所有对应图片。 trainval有11540张图片共27450个物体。 对于分割任务, VOC2012的trainval包含07-11年的所有对应图片, test只包含08-11。trainval有 2913张图片共6929个物体。
该赛事的主要目的是识别真实场景中一些类别的物体。在挑战中,这是一个监督学习的问题,训练集以带标签的图片的形式给出。这些物体包括20类:
Person: person ;人类:(人)
Animal: bird, cat, cow, dog, horse, sheep; 动物类(鸟、猫、牛、狗、马、羊);
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train ;交通工具类(飞机、自行车、船、公共汽车、轿车、摩托车、火车);
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor;室内类(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。
该赛事主要包括三类任务:分类(classification),检测(detection),和分割(segmentation)
Annotations:存放每张图片的XMLxml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片,共计17125个文件。该文件内容有每张图片目标的BBOX坐标、图片名称、类别等信息,文件的内容具体为:

<annotation>
<folder>VOC2012</folder> #表明比赛的数据年份
<filename>2007_000027.jpg</filename> #图片名称
<source> #表示图片来源是哪一年的数据集
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> #图像尺寸
<width>486</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented> #是否用于分割
<object> #包含的物体
<name>person</name> #物体类别
<pose>Unspecified</pose> #物体的姿势
<truncated>0</truncated> #物体是否被部分遮挡
<difficult>0</difficult> ##是否为难以辨识的物体, 主要指要结合背景才能判断出类别的物体。虽有标注, 但一般忽略这类物体 跳过难以识别的?
<bndbox> # #边界框bbox
<xmin>174</xmin>
<ymin>101</ymin>
<xmax>349</xmax>
<ymax>351</ymax>
</bndbox>
<part>#下面的数据是人体各个部位边界框
<name>head</name> #人的头
<bndbox>
<xmin>169</xmin>
<ymin>104</ymin>
<xmax>209</xmax>
<ymax>146</ymax>
</bndbox>
</part>
<part>
<name>hand</name> #人的手
<bndbox>
<xmin>278</xmin>
<ymin>210</ymin>
<xmax>297</xmax>
<ymax>233</ymax>
</bndbox>
</part>
<part>
<name>foot</name>#人的脚
<bndbox>
<xmin>273</xmin>
<ymin>333</ymin>
<xmax>297</xmax>
<ymax>354</ymax>
</bndbox>
</part>
<part>
<name>foot</name>#人的脚
<bndbox>
<xmin>319</xmin>
<ymin>307</ymin>
<xmax>340</xmax>
<ymax>326</ymax>
</bndbox>
</part>
</object>
</annotation>
ImageSets存放的是每一种类型的challenge对应的图像数据。 ImageSets下的四个文件夹,如下:

Action存放的是人的动作(running、jumping等等,这也是VOC challenge的一部分)

Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)

Main下存放的是图像物体识别的数据,总共分为20类。

Main文件夹下包含了20个分类的***_train.txt、***_val.txt和***_trainval.txt。

前面的表示图像的name,后面的1代表正样本,-1代表负样本。
_train中存放的是训练使用的数据,每一个class的train数据都有5717个。
_val中存放的是验证结果使用的数据,每一个class的val数据都有5823个。
_trainval将上面两个进行了合并,每一个class有11540个。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能重复,在选取训练数据的时候 ,也应该是随机产生的。
Segmentation下存放的是可用于分割的数据

主要看Segmentation文件夹。
ImageSets/Segmentation/train.txt:总共有1464行也就是1464张训练图片的名字;
ImageSets/Segmentation/val.txt:总共有1449行也就是1449张验证图片的名字;
ImageSets/Segmentation/trainval.txt:总共有2913行也就是2913张训练验证图片,上面两个的并集;
里面储存的是用于语义分割的图片的名字(无扩展名)。train和val两者没有交集,即训练数据和验证数据不能有重复,随机产生而trainval则是两者的总和。
JPEGImages文件夹中包含了PASCAL VOC提供的所有的就jpg图片,共计17125张,包括了训练和测试图片。
这些图像都以“年份_编号.jpg”格式命名。mode=RGB,format=JPEG。图片的像素尺寸大小不一,但是横向图的尺寸大约在500*375左右,纵向图的尺寸大约在375*500左右,长宽均不会超过512

SegmentationClass这里面包含了2913张图片,每一张图片都对应JPEGImages里面的相应编号的图片。
图片的像素颜色共有20种,对应20类物体。

SegmentationObject这里面同样包含了2913张图片,图片编号都与Class里面的图片编号相同。这里面的图片和Class里面图片的区别在于,这是针对Object的。在Class里面,一张图片里如果有多架飞机,那么会全部标注为红色。而在Object里面,同一张图片里面的飞机会被不同颜色标注出来。

参考:
https://blog.csdn.net/zz2230633069/article/details/84769339
https://blog.csdn.net/haoji007/article/details/80361587
https://www.e-learn.cn/content/qita/848225
https://blog.csdn.net/ouyangfushu/article/details/79543575
http://ai.baidu.com/forum/topic/show/593347
https://www.cnblogs.com/zyly/p/9248394.html#_label0_1
https://blog.csdn.net/LiJiancheng0614/article/details/77756252