概述
一个主播开播到用户能观看,一共经历了以下几个过程:
- 采集:通过摄像头,麦克风等采集图像和音频数据
- 编码:将采集到音频和图像数据,编码压缩,降低数据大小,并尽可能的保留精度。
- 封装:将编码后的数据,封装成各个格式,大家比较熟悉的如:FLV,MP4
- 推流:将完成封装的数据,采用HTTP或者RTMP协议推送到服务端
- 分发:直播流服务将数据分发给各个客户端,也就是每个用户的浏览器或App上。
- 播放:浏览器或App将收到的直播流数据进行解析或转码,并播放。
采集
这里的概念我做了很多简化。
更加详细的定义可以参考:音视频基本概念:分辨率、帧速率、码流、采样位深、采样率、比特率
采集分为音频采集和视频采集两个部分。
音频采集
通过麦克风等设备将环境中的模拟信号采集成 PCM 编码的原始数据。
音频的一些关键参数定义:
- 采样率
每秒钟取得声音样本的次数。采样频率越高,数据量就越大,同时音频质量也就越高 - 位宽
声卡的分辨率。它的数值越大,分辨率也就越高, 但数据量也越大。位宽的大小可以是:4bit、8bit、16bit、32bit 等等,常用的位宽是 8bit 或者 16bit。 - 声道数(channels)
声道数一般表示声音录制时的音源数量。如常见的单声道,就是声道数为1的。 - 音频帧
音频数据是流式的,本身没有明确的一帧帧的概念,一般约定俗成取 2.5ms~60ms 为单位的数据量为一帧音频。这个时间被称之为“采样时间”,其长度没有特别的标准,它是根据编解码器和具体应用的需求来决定的。
视频采集
视频采集其实是一个图像采集的过程,视频的播放,其实也是一张张图片的快速切换。图像的采集过程主要由摄像头等设备拍摄成 YUV 编码的原始数据。
- 图像格式
通常采用 YUV 格式存储原始数据信息。 - 传输通道
正常情况下视频的拍摄只需 1 路通道,但如果是想拍一个全景视频,则需要通过不同角度拍摄,然后将多路视频数据合并。 - 分辨率
屏幕上的点、线和面都是由像素组成的,显示器可显示的像素越多,就越清晰,但数据量就越大。而分辨率就是指显示器所能显示的像素的多少。所以分辨率是一个很重要的参数。 - 采样率
跟音频的采样率类似,采样率越高,视频质量越好,数据量越大。 - 码率
码率(Data Rate)是指视频文件在单位时间内使用的数据流量。视频文件的码率越大,压缩比就越小,画面质量就越高。码率越大,说明单位时间内取样率越大,数据流,精度就越高。
编码
编码是一个数据压缩的过程。将音视频的原始数据,经过一系列算法,将其压,以减少数据量。为什么音视频数据能压缩呢?因为原始数据中存在大量的冗余。
- 数据冗余
如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。消除这些冗余并不会导致信息损失,属于无损压缩。
以时间冗余为例。序列图像(如电视图像和运动图像)一般是位于时间轴区间内的一组连续画面,其中的相邻帧,或者相邻场的图像中,在对应位置的像素之间,亮度和色度信息存在着极强的相关性。举个实际的例子说明一下,比如你拍一段视频,是一个苹果放在桌子上,一直没人动他,周围的光线也不会变化(室内嘛),那么这段时间的图像是相似的,也就存在冗余了。 - 视觉冗余。
人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。这种压缩属于有损压缩。
这里列举一下常见的音视频编码格式:
视频编码格式
| 格式 | 说明 | 专利 | 开源库 |
|---|---|---|---|
| H.264/MPEG-4 AVC | 又称为MPEG-4第10部分,一种面向块的基于运动补偿的编解码器标准 | 使用 [H.264/MPEG-4 AVC的产品制造商和服务提供商需要向他们的产品所使用的专利的持有者支付专利许可费用。 | openh264,x264 |
| HEVC/H.265 | 又称为H.265和MPEG-H第2部分,是一种视频压缩标准,被视为是ITU-T H.264/MPEG-4 AVC标准的继任者。 | HEVC Advance 要求所有包括苹果、YouTube、Netflix、Facebook、亚马逊等使用 H.265 技术的内容制造商上缴内容收入的 0.5%作为技术使用费 | libde265,x265 |
| VP8 | 一个开放的影像压缩格式,最早由On2 Technologies开发,随后由Google发布 | 免费、开源 | libvpx |
| VP9 | 为了替换老旧的VP8影像编码格式并与动态专家图像组(MPEG)主导的高效率视频编码(H.265/HEVC)竞争所开发的影像编码格式。 | 免费、开源 | libvpx |
从上面的表格可以看出,未来应该是H.265和VP9的相互加量,关于两种格式的比较,可以参考H.265和VP9,哪个更有前途 。
其他更加详细的视频格式比较可以参考视频编解码器。
音频编码
| 格式 | 说明 | 专利 | 开源库 |
|---|---|---|---|
| MPEG-4 AAC | 一种基于MPEG-2的有损数字音频压缩的专利音频编码标准 | AAC 编解码器的所有制造商或开发商都需要专利许可 | |
| MP3 | 动态图像专家组-2 音频层III,当今流行的一种数字音频编码和有损压缩格式 | 与MP3相关的专利已于2017年4月16日全数过期。MP3进入公有领域后,任何人使用皆无须付专利授权费 | |
| WAV | 是微软与IBM公司所开发在个人计算机存储音频流的编码格式,需要特别注意的是,WAV文件与无损文件是不完全相同的,WAV文件只是不去对原有文件去做压缩。 | 这个不清楚 |
上面三种都是比较常见的,音频的编码格式还包括很多种,具体的可以参考音频编码格式的比较。但是音频好像没有单独对应的库,但都能通过ffmpeg内置的编解码器来解决。
封装
说到封装,可能很多人都会跟编码混在一起。其实两者是有区别的。区分封装和编码,要明确以下几点:
- 不同的封装格式对编码各自的支持是不一样的。各种封装格式支持的编码格式可参考:Comparison of video container formats。而造成这个现象的原因,从编码的表格中也可以看出,编码是有专利权,拥有专利权的公司可以通过收取专利费来盈利。
- 封装是一个把音频和视频数据整合在一起的过程,除此之外,还可以附带其他数据,如脚本(典型的如:FLV封装格式),字幕等信息。因此视频的封装格式,算是一种容器。真正的压缩,取决于编码格式。
- 视频封装格式的存在是必要的,否则播放器无法实现进度条拖动等功能。
经过了封装这一步才能,才构成了我们日常播放的视频文件。
推流
参考文档:
直播协议对比
直播协议和推流
入门 | 直播协议简述
所谓推流,就是将采集到的音视频数据推送到的服务端。当前比较热门的直播流协议有一下几种:
| 协议 | 简介 | 优点 | 缺点 |
|---|---|---|---|
| RTMP | 是最初由Macromedia为通过互联网在Flash播放器与一个服务器之间传输流媒体音频、视频和数据而开发的一个专有协议。Macromedia后被Adobe Systems收购,该协议也已发布了不完整的规范供公众使用。 | 1. 实时性高:一般能做到3秒内 2. 支持加密:同系列的rtmpe和rtmps为加密协议 3. 主流编码器都支持该协议,如:ffmpeg |
1. H5 不支持 2. 协议复杂,开发成本高 3. Cache麻烦:流协议做缓存不方便。 |
| HTTP+FLV | FLV是Adobe主推的一种视频封装格式,结合HTTP协议实现实时数据传播。 | 1. HTTP 性能很高,协议简单,高性能服务框架完善(如:nginx) 2. 没有碎片:http相比hls没有碎片。 3. 穿墙:http端口是互联网必定会开放的端口,但RMTP端口则不一定 |
1.需要http长连接 2.h5中需要使用插件。 3.需要flash技术支持,不支持多音频流,多视频流,不便于拖动 |
| HLS | 是一个由苹果公司提出的基于HTTP的流媒体网络传输协议 | 1. 基于HTTP,性能好,也可以穿墙。 2. 在iOS上支持良好 3. 客户端实现简单,只需支持HTTP协议即可 |
1. 延迟高:与ts切片长度有关,大约3个切片长度时间的延迟,基本上HLS的延迟在10秒以上。 2. 服务端实现复杂:相对于Flv的标准开放文档是11页,ts的174页标准就显得很复杂。 3. 文件碎片:若分发HLS,码流低,切片较小时,会导致太多的文件碎片 |
分发
分发,是服务端将各,采用的也是上面几种常见的直播流协议。这里就不多做说明啦。
播放
这里引用雷神博客里的一张图(https://blog.csdn.net/leixiaohua1020/article/details/18893769)
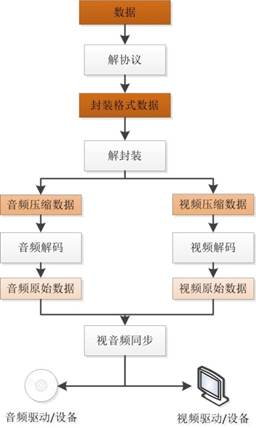
播放则是一个解封装,解编码的过程,这些格式都在上面有提到,也不多做说明啦。有兴趣的可以看「视频直播技术详解」系列之六:现代播放器原理