范涛
发表于2017-04-06
FastText github路径:
https://github.com/facebookresearch/fastText
参考文献:
前言
Facebook 在2016年第一次对外公开FastText算法时候,应该是引起很大一番讨论,因为论文提到他以更快的速度达到和DNN类似的效果。这里不再争论这点。当时吸引我一点的是他在大规模数据集上的扩展性和速度上都很棒,因为这两点十分适合工业界应用。当时正好在做query意图识别相关的任务,语料也是几百万。最开始拿的是Navie Bayies做baseline,Navie Bayies这种生成模型在大语料下不仅训练耗时,关键让人失望的是,预测速度变得也不那么快。基于当时的现状,我觉得我可以接受些许准确率损失,来换来模型训练和预测时效性得显著提高。这个时候,我直接拿FastText来进行query 意图识别。结果FastText的效果果然没让我失望,训练耗时从之前几个小时到现在的几分钟,预测速度那叫一个快啊。更让我惊喜的是,准确性上一点也不差,有些场景比NB还好。
FastText 重点解析
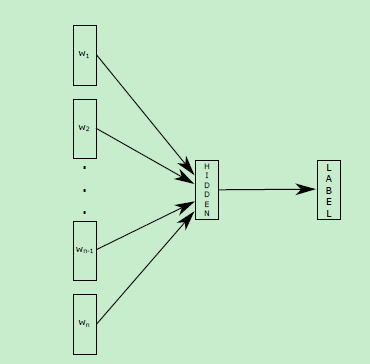
FasText中分类模型示意图:
FastText 代码组织结构图如下(原图源于
https://heleifz.github.io/14732610572844.html博客):

model 模块结构图如下(原图源于
https://heleifz.github.io/14732610572844.html博客):

训练部分核心代码:
主要功能就是如何计算梯度和更新,以及输出权重矩阵wo,输入矩阵wi如何更新等。隐层hidden其实就是输入矩阵wi的各个词的平均,是一个一维向量。

采用二分类,计算logloss,更新梯度和输出权重矩阵。
wo+=hidden*(label-sigmoid(woi * hidden))*lr隐层的梯度grad+=woi *(label-sigmoid(woi * hidden))* lr公式的由来可以参考Word2vector中cbow负采样模型求解。截图如下:

负采样模式计算loss,更新梯度和更新权重矩阵:
初正样本外,负样本是随机采样。target可以分类label, 也可以是word。采样命中率和词频或者label频率正相关。

层次softmax模式计算loss,更新梯度和更新权重矩阵:
首先是根据词频或者labels频率建立个huffman树,这个huffman数每层遍历进行二分类LR。
简单softmax模式计算loss,更新梯度和更新权重矩阵: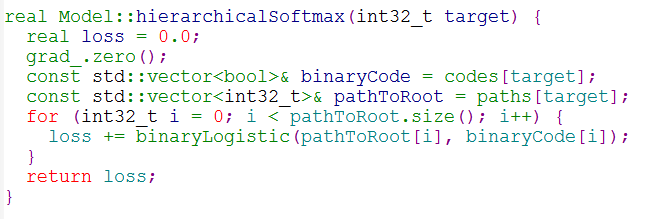

模型训练更新参数总入口:
先前向传播计算隐层hidden,计算loss,然后反向更新梯度,再把梯度值进行按输入平均,反向更新到输入矩阵wi

skipgram 相对原始的word2vector做了修正,对一个词,扩展了这个词char-ngrams,比如“examples”这个词的char-ngrams可能是“am”,“exa”,“xamp”等,skipgram过程则修正为这个词以及这个词char-ngrams词向量平均来预测这个词的上下文。这么做的好处,《Enriching Word Vectors with Subword Information》这篇文章中给的解释如下:解决word2vector 中同一个词不同形态问题和更好的解决一些不常见词的词向量问题。值得说明的是比如“examples”中char-ngram 的“am”和单独一个单词“am”词向量是不一样的,因为两者对应的索引位置不同。比如char-ngram 出的词索引会放在bucket部分的。
如下面的这块代码:
char-Ngrams计算方式:

skipgram模型:

cbow模型:

分类模型:
分类模型每行输入line是个vector,这个vector包含了unigram,还包含wordgram. 分类模型没有采用char-ngrams。

分类预测模块:
wi是词向量输入矩阵,维度(词数量,词嵌入维度),隐层hidden其实就是输入向量矩阵wi的各个词的加权平均,是一个一维向量。wo是一个输出权重矩阵,维度(label数,嵌入维度)。最终的分类label确定方式,如果loss_name不是层次softmax的话,就是wo和hidden相乘得到个一维向量,看这个一维向量那个位置值最大,那这个位置对应的label就是最终分类标签。

词向量模型如何输出一个词的向量?
一个词的最终向量表示由这个词以及这个词char-ngrams词向量的平均值来表示。

词是如何存储和索引的?
可以看Dictionary模块。word是通过hash机制+线性寻址来索引的。下面是相关代码:

总结
最后想提下,FastText 中分类这块其实一个简单的线性分类器,他最大的优势是快速训练和预测,几百万的训练数据几分钟就搞定了,十分适用于工业界场景。如果要说有什么不足的话? 我觉得是不支持从已有训练好的大规模词向量模型进行fine-tune的机制。我觉得用已有更大规模的语料训练好的词向量模型fine-turn是有好处的,尤其如果分类任务的语料不够大的情形。其实仔细想想,FastText 框架如果想修改成支持fine-turn也是很方便的,就是类似里面“printVectors”函数,加载词向量模型来初始化input矩阵。