ptmalloc堆概述
1 概述
堆的概念
在程序运行过程中,堆可以提供动态分配的内存,允许程序申请大小未知的内存。堆其实就是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。
堆管理器
我们一般称管理堆的那部分程序为堆管理器。
· dlmalloc – General purpose allocator
· ptmalloc2 – glibc
· jemalloc – FreeBSD and Firefox
· tcmalloc – Google
· libumem – Solaris

堆管理器处于用户程序与内核中间,主要做以下工作
1. 响应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序。同时,为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
2. 管理用户所释放的内存。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
Dlmalloc
Linux 中早期的堆管理器。在并行处理多个线程时,会共享进程的堆内存空间。
Ptmalloc
Wolfram Gloger 在 Doug Lea 的基础上进行改进使其可以支持多线程,这个堆分配器就是 ptmalloc 。在 glibc-2.3.x. 之后,glibc 中集成了ptmalloc2。
可以下载glibc源码查看ptmalloc
查看glibc版本
millionsky@ubuntu-16:~/tmp$ ldd --version ldd (Ubuntu GLIBC 2.23-0ubuntu9) 2.23 |
堆的基本操作
#include <stdlib.h> /* ** 为0时返回最小的chunk,32位系统为16,64位系统为24/32。 */ void *malloc(size_t size); /* **除非被mallopt禁用,释放很大的内存空间时,程序会将这些内存空间还给系统。 */ void free(void *ptr); |
系统调用
brk/mmap/munmap
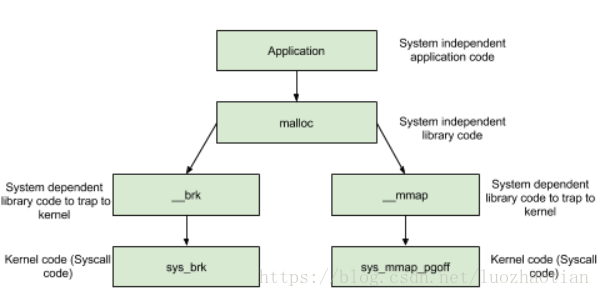
glibc函数
brk/sbrk/mmap/munmap
多线程支持
相对于dlmalloc,在glibc的ptmalloc实现中,比较好的一点就是支持了多线程的快速访问。在新的实现中,所有的线程共享多个堆。
2 ptmalloc堆数据结构
2.1 Chunk
2.1.1 Chunk概述
1. malloc 申请的内存为 chunk 。这块内存在 ptmalloc 内部用 malloc_chunk 结构管理chunk。当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中。
l Chunk的对齐:32位为8字节;64位为16字节
l Chunk的最小尺寸:32位为16字节;64位为24/32字节
/* The smallest possible chunk */
#define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))
2. Chunk有4种类型:
· Allocated chunk
· Free chunk
· Top chunk
· Last Remainder chunk
2.1.2 malloc_chunk数据结构
1. Ptmalloc使用malloc_chunk结构管理chunk。
这个结构跨越了两个chunks
第1个字段属于之前的chunk,第2/3/4字段属于当前的chunk;
只有当(size&1)==0时,prev_size字段才会被定义;
#define INTERNAL_SIZE_T size_t #define SIZE_SZ (sizeof (INTERNAL_SIZE_T))
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */ struct malloc_chunk *fd; /* double links -- used only if free. */ struct malloc_chunk *bk; /* Only used for large blocks: pointer to next larger size. */ struct malloc_chunk *fd_nextsize; /* double links -- used only if free. */ struct malloc_chunk *bk_nextsize; }; |
l fd 指向下一个(非物理相邻)空闲的 chunk,free chunk中才有
l bk 指向上一个(非物理相邻)空闲的 chunk,free chunk中才有
通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
l fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。只用于large chunk。
l bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。只用于large chunk。
l 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适chunk 时挨个遍历。
2. 一个已经分配的 chunk 的样子如下。我们称前两个字段称为 chunk header,后面的部分称为user data。每次 malloc 申请得到的内存指针,其实指向user data的起始处。
3. Chunk的标志位
² NON_MAIN_ARENA(A),当前 chunk 是否不属于主线程,1表示不属于,0表示属于。
² IS_MAPPED(M),当前 chunk 是否是由 mmap 分配的。
如果M位被设置,则其它位被忽略(因为mapped chunks既不在arena中,也不和free chunk相邻);(PS:这里没有怎么理解)
² PREV_INUSE(P),前一个 chunk 块是否被分配。
如果为0,则prev_size包含前一个chunk的大小;可计算出前一个chunk的位置;
如果为1,则不能确定前一个chunk的大小;
分配的第一个chunk通常会设置此位,防止访问不存在或不拥有的内存;
4. chunk中的空间复用
当一个 chunk 处于使用状态时,它的下一个 chunk 的 prev_size 域无效,所以下一个 chunk 的该部分也可以被当前chunk使用。这就是chunk中的空间复用。
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
2.1.3 Allocated chunk
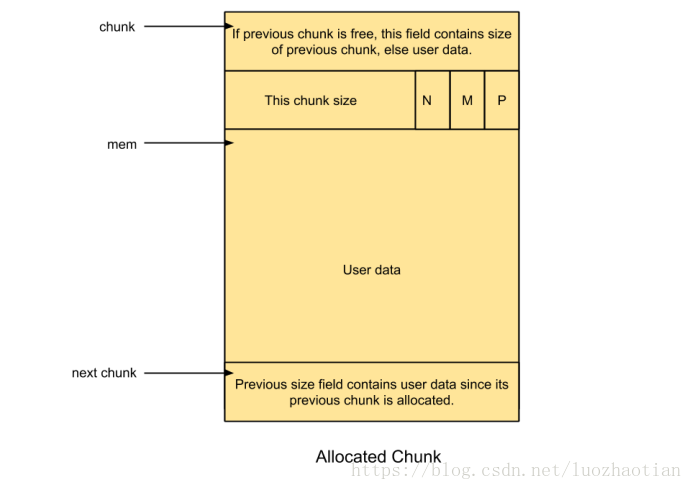
l prev_size
前一个chunk(物理相邻)如果为free chunk(size&1==0),则指示其大小;
l Size
该 chunk 的大小,大小必须是 2 * SIZE_SZ 的整数倍。
由于chunk必须是8的整数倍,低3比特对size字段没有意义,从高到低分别表示:
² NON_MAIN_ARENA(N),当前 chunk 是否不属于主线程,1表示不属于,0表示属于。
² IS_MAPPED(M),当前 chunk 是否是由 mmap 分配的。
² PREV_INUSE(P),前一个 chunk 块是否被分配。
堆中第一个被分配的内存块的 size 字段的P位都会被设置为1,以便于防止访问前面的非法内存。
2.1.4 Free chunk

prev_size: 两个free chunks不会连在一起,两个连在一起的chunk被释放时,会合并成一个free chunk。因此free chunk的前一个chunk是被分配的,由此prev_size包含前一个chunk的用户数据;
size: 包含free chunk的大小;
fd: Forward pointer – 指向相同bin中的下一个(非物理相邻的下一个chunk)free chunk;
bk: Backward pointer – 指向相同bin中的上一个(非物理相邻的上一个chunk)free chunk;
2.1.5 Top chunk
程序第一次进行 malloc 的时候,heap 会被分为两块,一块给用户,剩下的那块就是 top chunk。其实,所谓的top chunk 就是处于当前堆的物理地址最高的 chunk。这个 chunk 不属于任何一个 bin,它的作用在于当所有的bin 都无法满足用户请求的大小时,如果其大小不小于指定的大小,就进行分配,并将剩下的部分作为新的 top chunk。否则,就对heap进行扩展后再进行分配。在main arena中通过sbrk扩展heap,而在thread arena中通过mmap分配新的heap。
需要注意的是,top chunk 的 prev_inuse 比特位始终为1,否则其前面的chunk就会被合并到top chunk中。
1. Top chunk:位于arena顶部边界的chunk称为top chunk;
Top chunk不属于任何bin;
由于top chunk没有下一个连续的chunk,它不能使用下一个chunk的prev_size字段;
初始化之后,top chunk就一直存在,如果小于MINSIZE,则会被补充;
当任何bins中都没有可用的chunk时,就使用top chunk来处理用户的请求;
如果top chunk的大小大于用户请求的大小,则top chunk被切分成两个:
· User chunk (用户请求的大小) – 返回给用户.
· Remainder chunk (of remaining size) – 成为新的top chunk
如果top chunk的大小小于用户请求的大小,则使用sbrk(main arena)或mmap(thread arena)扩展top chunk;
2.1.6 Last Remainder chunk
Last Remainder chunk:最近对small chunk请求进行切分的剩余部分。Last remainder chunk帮助提高引用的位置,即连续的malloc请求small chunk很可能分配到相邻的位置;
当用户请求small chunk时,如果small bin或unsorted bin中没有可用的,则扫描binmaps查找next largest bin。找到后,进行切分,返回给用户,剩余的chunk加入unsorted bin。这个剩余的chunk就成为新的last remainder chunk。
当用户后续请求small chunk时,如果last remainder chunk是unsorted bin中的唯一的chunk,则last remainder chunk被切分,返回给用户,剩余的chunk加入unsorted bin。这个剩余的chunk就成为新的last remainder chunk。这样后续的内存分配都是相邻的。
2.2 Bins
注意:Bin的翻译为箱子,chunk的翻译为块;
1. Bin:freelist数据结构,用于保存free chunks。
2. 基于chunk size,bins被划分为以下几种类型:
l Fast bin(单链表,大小相同)
l Unsorted bin(环形双链表,乱序状态,空闲 chunk 回归所属 bin 之前的缓冲区)
l Small bin(环形双链表,大小相同)
l Large bin(环形双链表,按大小降序排列)
【bins】
l Bins:bin header的数组;
l 每个bin是free chunk的双链表;
l Bins这个数组(malloc_state中)存储unsorted、small、large bins;
#define NBINS 128
mchunkptr bins[ NBINS * 2 - 2 ];
l 总共128个bins,划分如下:
· Bin 0 – 不存在
· Bin 1 – Unsorted bin
· Bin 2 to Bin 63 – Small bin
· Bin 64 to Bin 126 – Large bin
3. 大部分bin持有的chunk大小,相对于malloc请求的大小是很罕见的,更常见的是chunk分片和合并。
4. 所有的过程都维护着一个不变式:合并后的chunk之间不能物理相邻;因此链表中的每个chunk的物理前面和后面都跟着使用中的chunk或内存的结尾;
5. bin中的chunks是按照大小和时间(最近最少使用)排序的;
排序对Small bins是不需要的,因为small bin中所有的chunk大小相同。
顺序排列可以提高效率,不需要足够的遍历就可以找到用户请求的数据;
相同大小的chunk是这样链接的:最近释放的放在前面;分配是从后面开始的。这会导致LRU(Least Recently Used,FIFO)分配顺序,每个chunk都会有相同的机会和毗邻的free chunk合并。
6. 为了简化双链表的使用,每个bin header就像malloc_chunk一样。这避免了类型转换。但为了节省空间,和提高位置,我们只分配了fd/bk这两个指针;然后使用重定位技巧将fd/bk视为一个malloc_chunk的字段;
注意:bins数组存储的不是mchunkptr,而是malloc_chunk中的fd/bk两个字段。Bins数组有127*2个元素,每个bin header占两个,因而总共可以存储127个bin。
索引对应关系为:
bin索引 Bins数组索引
0 不存在
1 2*(-1)
2 2*(0)
3 2*(1)
126 2*(124)
127 2*(125)
2.2.1 Fast bin
1. 大小为16~80/32~160字节的chunk称为fast chunk;
存储fast chunk的bins称为fast bins;
在所有的bins中,Fast bins在内存分配和释放上更快;
Fast bin是一个存储最近释放的small chunks的数组;
Fast bin特别设计为很多小的结构、对象或字符串;
大多数程序经常会申请以及释放一些比较小的内存块。如果将一些较小的 chunk 释放之后发现存在与之相邻的空闲的 chunk 并将它们进行合并,那么当下一次再次申请相应大小的 chunk 时,就需要对 chunk 进行分割,这样就大大降低了堆的利用效率。因为我们把大部分时间花在了合并、分割以及中间检查的过程中。因此,ptmalloc 中专门设计了 fast bin,对应的变量就是 malloc state 中的 fastbinsY。
2. fastbinsY这个数组存储fast bin。
typedef struct malloc_chunk *mfastbinptr; mfastbinptr fastbinsY[ NFASTBINS ]; |
相关的定义如下:
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[ idx ])
/* offset 2 to use otherwise unindexable first 2 bins */ #define fastbin_index(sz) \ ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2) /* The maximum fastbin request size we support */ #define MAX_FAST_SIZE (80 * SIZE_SZ / 4) #define NFASTBINS (fastbin_index(request2size(MAX_FAST_SIZE)) + 1) |
3. Fast Bin的数目:10
每个fast bin包含一个free chunks的单链表(即binlist);
因为fast bins中chunk不能从链表的中间移除,因此使用了单链表;
Chunk在fast bin链表中的添加和删除只发生在链表的头部--LIFO(一般的bin是FIFO);
4. Chunk size的间隔是8字节(32位)或16字节(64位)
Chunk size与fast bin index的对应:
Fast bin Index |
Chunk size(32) |
Chunk size(64) |
0 |
16 |
32 |
1 |
24 |
48 |
2 |
32 |
64 |
3 |
40 |
80 |
4 |
48 |
96 |
5 |
56 |
112 |
6 |
64 |
128 |
7 |
72 |
144 |
8 |
80 |
160 |
9 |
88 |
176 |
5. 某个特定的fast bin中chunks的大小是相同的
6. Malloc初始化时,最大的fastbin(用户数据)设置为64(32位)或128(64位)
因此默认时,大小[16,72]/[32,144]的chunks是fast chunks;
/* DEFAULT_MXFAST 64 (for 32bit), 128 (for 64bit) */ static void malloc_init_state(mstate av) { if (av == &main_arena) set_max_fast(DEFAULT_MXFAST); |
7. 不合并(No Coalescing)
fastbin的inuse位总是被设置;
两个free chunks可以是相邻的,不会合并成一个free chunk;
不合并会导致更多的分片,但可以提高速度;
Fast bin中的chunks只会成块合并(bulk);
8. Malloc(fast chunk)
· 初始时,fast bin max size and fast bin indices是空的,即时用户请求一个fast chunk,malloc也不会进入fast bin code,而是进入small bin code。
/* Maximum size of memory handled in fastbins. */ static INTERNAL_SIZE_T global_max_fast;
/* Fastbins */ mfastbinptr fastbinsY[ NFASTBINS ];
/* Fast bin code */ if ((unsigned long) (nb) <= (unsigned long) (get_max_fast())) {}
/* small bin code */ if (in_smallbin_range(nb)) {} |
· 之后,当fast bin max size and fast bin indices非空时,会计算fast bin index,并获取对应的binlist;
· Binlist中的第一个chunk从binlist中移除并返回给用户;
9. free(fast chunk) –
· 计算Fast bin index,获取对应的binlist;
· 将free chunk加入到获取的binlist的前端(front position);
2.2.2 Unsorted bin
chunk切分后的剩余部分、所有释放后返回的chunk,都会被放入unsorted bin,而不是对应的bins。Malloc会扫描unsorted bin来重用最近被释放的chunk,然后它们会被放入对应的bins。
因此,基本上,unsorted_chunks是一个队列。chunks在释放、切分的时候放入;在malloc的时候重用或放入对应的bins。
1. Bin的数目 - 1
Unsorted bin包含一个free chunks的环形双链表(即binlist);
2. Chunk size - 没有大小限制,任何大小的chunks都属于此bin;
unsorted bin 中的空闲 chunk 处于乱序状态,主要有两个来源
· 当一个较大的 chunk 被分割成两半后,如果剩下的部分大于MINSIZE,就会被放到 unsorted bin 中。
· 释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。
此外,Unsorted Bin 在使用的过程中,采用的遍历顺序是 FIFO 。
2.2.3 Small bin
1. 小于512/1024字节的chunk称为small chunk。
存储small chunk的bins称为small bins;
在内存的分配和释放上,Small bins比large bins快,比fast bins慢;
2. 相关定义
INTERNAL_SIZE_T:4/8字节
SIZE_SZ:4/8
MALLOC_ALIGNMENT:对齐单位,默认为8/16
#ifndef INTERNAL_SIZE_T
# define INTERNAL_SIZE_T size_t
#endif
#define SIZE_SZ (sizeof (INTERNAL_SIZE_T))
#ifndef MALLOC_ALIGNMENT
# define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) \
? __alignof__ (long double) : 2 * SIZE_SZ)
#endif
MIN_LARGE_SIZE:512/1024
#define NBINS 128 #define NSMALLBINS 64 #define SMALLBIN_WIDTH MALLOC_ALIGNMENT #define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ) #define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
#define in_smallbin_range(sz) \ ((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE) |
3. bins的数目--62
每个small bin包含一个free chunks的环形双链表(即binlist);
使用双链表的原因是:在small bins中chunks是从链表的中间拆除的。而链表是FIFO,添加发生在前端,删除发生在链表的尾端;
4. Chunk size的间隔 - 8字节/16字节;
Bin 2是第一个small bin;
一个Small bin中的chunks的大小是相同的,因而不需要排序;
32位 64位
Bin2 16 32
Bin3 24 48
Bin4 30 64
......
Bin63 504 1008
5. 合并
两个相邻的free chunk会合并成一个free chunk;
合并消除了碎片,但降低了速度;
6. malloc(small chunk) –
l 开始时,所有的small bins都是NULL,即时用户请求一个small chunk,也会进入unsorted bin code,而不是small bin code;
l 同样在第一次调用malloc的时候,small bin和large bin的数据结构(malloc_state中的bins)会被初始化,bins会指向自身表明它是空的;
l 之后当small bin非空时,对应的binlist中的最后一个chunk被移除和返回给用户;
7. free(small chunk) –
l 释放chunk时,检查它的前面和后面的chunk是否free chunk。如果是则合并;从相关的链表中unlink这些chunks,将新合并的chunk加入到unsorted bin的链表的开始;
2.2.4 Large bin
1. 大小大于等于512字节的chunk称为large chunk;
存储large chunk的bins称为large bins;
在内存的分配和释放上,large bins比small bins慢;
2. bins的数目--63
l 每个large bin包含一个free chunks的环形双链表(即binlist);
l 使用双链表的原因是:在large bins中chunks是从链表的任何位置增加和移除的(前面、中间、后面);
l Bin的索引和chunk size间隔(32位)
Bin count |
Bin index |
Chunk size |
31 |
64 ... 94 |
[512, +64) ... [512+64*30, +64) [2432, 2496) |
17 |
95 ... 111 |
[2496, 2560) ... [10240, +512) |
9 |
112 ... 120 |
[10752, 12288) ...+4096 [40960, +4096) [40960,45056) |
3 |
120 121 122 123 |
[45056, 65536) ...+32768 [131072, +32768) |
2 |
124 125 126 |
[163840, 262144) [262144,+262144) [524288,+262144) |
1 |
126 |
[786432, *) |
相关代码为:

3. 和small bin不一样,一个large bin中的chunks不是相同大小的;因此按照降序排列,大的chunk存储在前端,小的chunk存储在后端;
4. 合并
两个free chunk可以相邻,会合并成一个free chunk;
5. malloc(large chunk)
l 开始时,所有的large bins都是NULL,即时用户请求一个large chunk,也会进入next largest bin code,而不是large bin code;
l 同样在第一次调用malloc的时候,small bin和large bin的数据结构(malloc_state中的bins)会被初始化,bins会指向自身表明它是空的;
l 之后当large bin非空时,如果bin list中最大的chunk size大于用户请求的大小,会从后往前遍历binlist,找到一个最近大小的chunk。该chunk被划分为两个chunk:
· User chunk (用户请求的大小) – 返回给用户.
· Remainder chunk (of remaining size) – 增加到 unsorted bin.
l 如果用户请求的大小比binlist中最大的chunk还大,则进入next largest bin code。Next largest bin扫描binmaps(ps:应该是下一个大的binlist)来找到非空的next largest bin,如果找到了,则从该binlist中返回此chunk,切分后返回给用户,剩余的增加到unsorted bin;如果没有找到,则尝试使用top chunk处理用户的请求;
6. Fd_nextsize链表
l fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。只用于large chunk。
l bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。只用于large chunk。
l 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适chunk 时挨个遍历。大小相同时总是插入第二个位置。取出时也是取出第二个位置。这样可以避免调整fd_nextsize/bk_nextsize指针。
l 由于bin头不包含fd_nextsize/bk_nextsize指针,它不在fd_nextsize/bk_nextsize链表中。
如何理解呢?_int_malloc的源码中有插入和取出的逻辑
Large chunk插入示例
Ø 通过fd/bk链接起来的big chunk,fd链表中按大小降序排列
fd链表:Chunk1 > chunk2 > chunk3 > chunk6
此时fd_nextsize/bk_nextsize链表也是这样的
Fd_nextsize链表:Chunk1 > chunk2 > chunk3 > chunk6
Ø chunk4插入链表中,它的大小和chunk3相同
Chunk1 > chunk2 > chunk3 = chunk4 > chunk6 //fd链表
Chunk1 > chunk2 > chunk3 > chunk6 //fd_nextsize链表
Ø Chunk5插入链表中,它的大小和chunk3相同
Chunk1 > chunk2 > chunk3 = chunk5 = chunk4 > chunk6 //fd链表
Chunk1 > chunk2 > chunk3 > chunk6 //fd_nextsize链表
Large chunk取出示例
Ø 取出一个和chunk3大小相同的chunk
Chunk1 > chunk2 > chunk3 = chunk4 > chunk6 //fd链表
Chunk1 > chunk2 > chunk3 > chunk6 //fd_nextsize链表
3 实例
来自https://exploit-exercises.com/protostar/heap3/
测试环境:Ubuntu 16.04 64
测试结果:
l free chunk中只有fd链表,没有bk链表;
l Free chunk中prev_size为0
l free时P标志(PREV_INUSE)没有被清除
Heap3.c
millionsky@ubuntu-16:~/tmp/malloc$ gcc -m32 heap3.c (gdb) b main Breakpoint 1 at 0x8048531 (gdb) r AAAA BBBB CCCC |
3个malloc后面下断
(gdb) b *0x08048540 Breakpoint 2 at 0x8048540 (gdb) b *0x08048550 Breakpoint 3 at 0x8048550 (gdb) b *0x08048560 Breakpoint 4 at 0x8048560 |
【第一次分配】
第一次分配后
查看堆的位置和大小
堆的位置:0x0804b000
堆的大小:0x21000(132KB)
millionsky@ubuntu-16:~$ cat /proc/`pgrep a.out`/maps 08048000-08049000 r-xp 00000000 08:01 11143849 /home/millionsky/tmp/malloc/a.out 08049000-0804a000 r--p 00000000 08:01 11143849 /home/millionsky/tmp/malloc/a.out 0804a000-0804b000 rw-p 00001000 08:01 11143849 /home/millionsky/tmp/malloc/a.out 0804b000-0806c000 rw-p 00000000 00:00 0 [heap] |
查看分配的chunk
当前有两个chunk
第一个chunk的size为0x28,P位为1;
第二个chunk的size为0x20fd8,P为为1
这两个chunk占用了整个当前的堆的空间;
(gdb) p/x $eax $1 = 0x804b008 (gdb) x/14wx $eax-8 0x804b000: 0x00000000 0x00000029 0x00000000 0x00000000 0x804b010: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b020: 0x00000000 0x00000000 0x00000000 0x00020fd9 0x804b030: 0x00000000 0x00000000 |
【第三次分配】
现在有4个chunk了
(gdb) p/x $eax $3 = 0x804b058 (gdb) x/34wx 0x804b000 0x804b000: 0x00000000 0x00000029 0x00000000 0x00000000 0x804b010: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b020: 0x00000000 0x00000000 0x00000000 0x00000029 0x804b030: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b040: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b050: 0x00000000 0x00000029 0x00000000 0x00000000 0x804b060: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b070: 0x00000000 0x00000000 0x00000000 0x00020f89 0x804b080: 0x00000000 0x00000000 |
【3个free后面下断】
(gdb) b *0x080485b6 Breakpoint 5 at 0x80485b6 (gdb) b *0x080485c4 Breakpoint 6 at 0x80485c4 (gdb) b *0x080485e2 Breakpoint 7 at 0x80485e2 |
【free之前】
4个chunk,前面3个有数据
(gdb) x/34wx 0x804b000 0x804b000: 0x00000000 0x00000029 0x41414141 0x00000000 0x804b010: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b020: 0x00000000 0x00000000 0x00000000 0x00000029 0x804b030: 0x42424242 0x00000000 0x00000000 0x00000000 0x804b040: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b050: 0x00000000 0x00000029 0x43434343 0x00000000 0x804b060: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b070: 0x00000000 0x00000000 0x00000000 0x00020f89 0x804b080: 0x00000000 0x00000000 |
【free(c);】
Chunk 3的数据被擦除了
(gdb) x/34wx 0x804b000 0x804b000: 0x00000000 0x00000029 0x41414141 0x00000000 0x804b010: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b020: 0x00000000 0x00000000 0x00000000 0x00000029 0x804b030: 0x42424242 0x00000000 0x00000000 0x00000000 0x804b040: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b050: 0x00000000 0x00000029 0x00000000 0x00000000 0x804b060: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b070: 0x00000000 0x00000000 0x00000000 0x00020f89 0x804b080: 0x00000000 0x00000000 |
【free(b);】
Chunk 2的fd指向chunk 3
Chunk 2的数据被擦除了
(gdb) x/34wx 0x804b000 0x804b000: 0x00000000 0x00000029 0x41414141 0x00000000 0x804b010: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b020: 0x00000000 0x00000000 0x00000000 0x00000029 0x804b030: 0x0804b050 0x00000000 0x00000000 0x00000000 0x804b040: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b050: 0x00000000 0x00000029 0x00000000 0x00000000 0x804b060: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b070: 0x00000000 0x00000000 0x00000000 0x00020f89 0x804b080: 0x00000000 0x00000000 |
【free(a);】
Chunk 1的fd指向chunk 2
Chunk 2的fd指向chunk 3
(gdb) x/34wx 0x804b000 0x804b000: 0x00000000 0x00000029 0x0804b028 0x00000000 0x804b010: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b020: 0x00000000 0x00000000 0x00000000 0x00000029 0x804b030: 0x0804b050 0x00000000 0x00000000 0x00000000 0x804b040: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b050: 0x00000000 0x00000029 0x00000000 0x00000000 0x804b060: 0x00000000 0x00000000 0x00000000 0x00000000 0x804b070: 0x00000000 0x00000000 0x00000000 0x00020f89 0x804b080: 0x00000000 0x00000000 |
4 附件
5 结论
理解ptmalloc堆chunk结构
6 参考文档
1. https://ctf-wiki.github.io/ctf-wiki/pwn/heap/heap_overview/。
2. Exploiting the heap。http://www.win.tue.nl/~aeb/linux/hh/hh-11.html。
3. https://raw.githubusercontent.com/iromise/glibc/master/malloc/malloc.c。
4. https://exploit-exercises.com/protostar/heap3/。
5. https://sploitfun.wordpress.com/2015/02/10/understanding-glibc-malloc/comment-page-1/