前提:本文主要功能是
1.用python代刷王者荣耀金币
2.爬取英雄信息
3.爬取王者荣耀图片之类的。
(全部免费附加源代码)
思路:第一个功能是在基于去年自动刷跳一跳python代码上面弄的,思路来源陈想大佬,主要是图片识别像素,然后本机运行模拟器即可,第二、三功能是python基本爬虫功能。3个功能整合了一下。
实现效果如下:
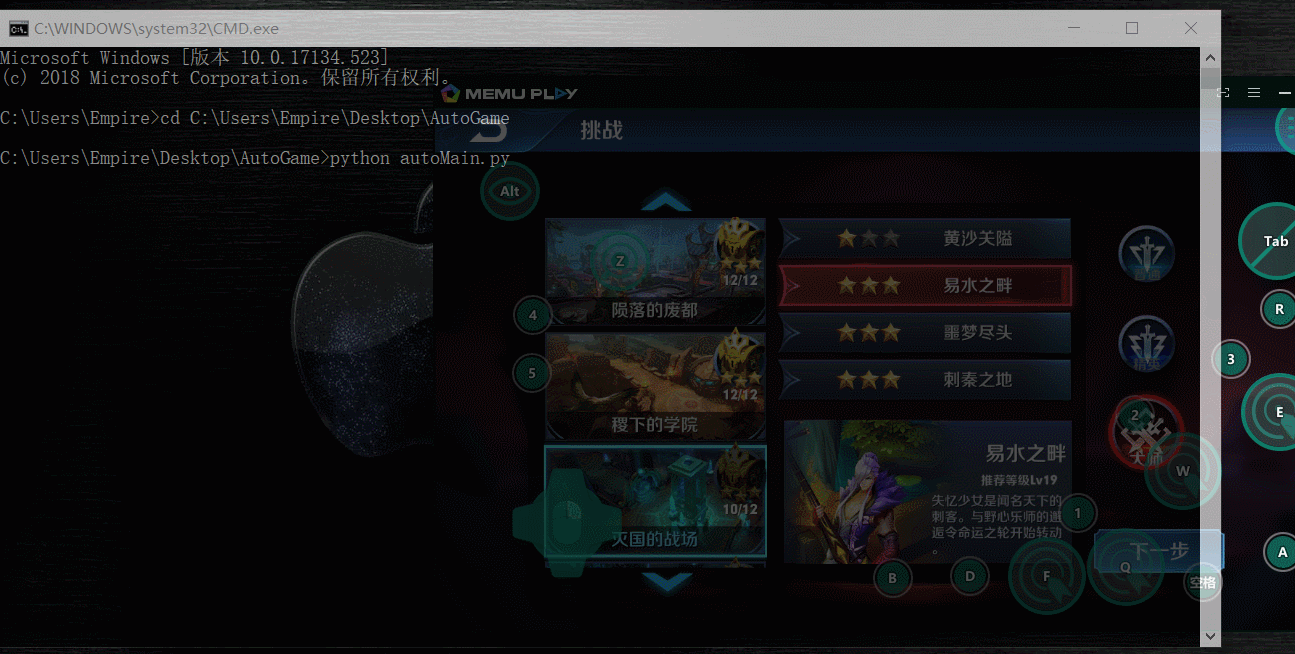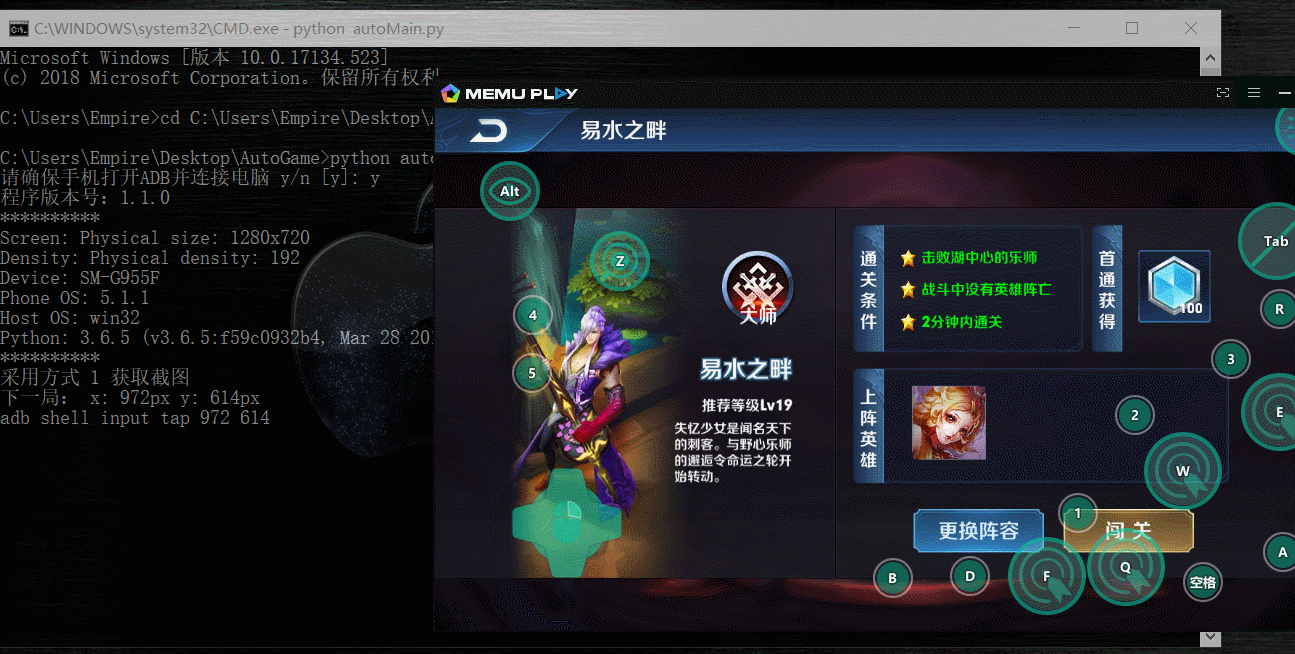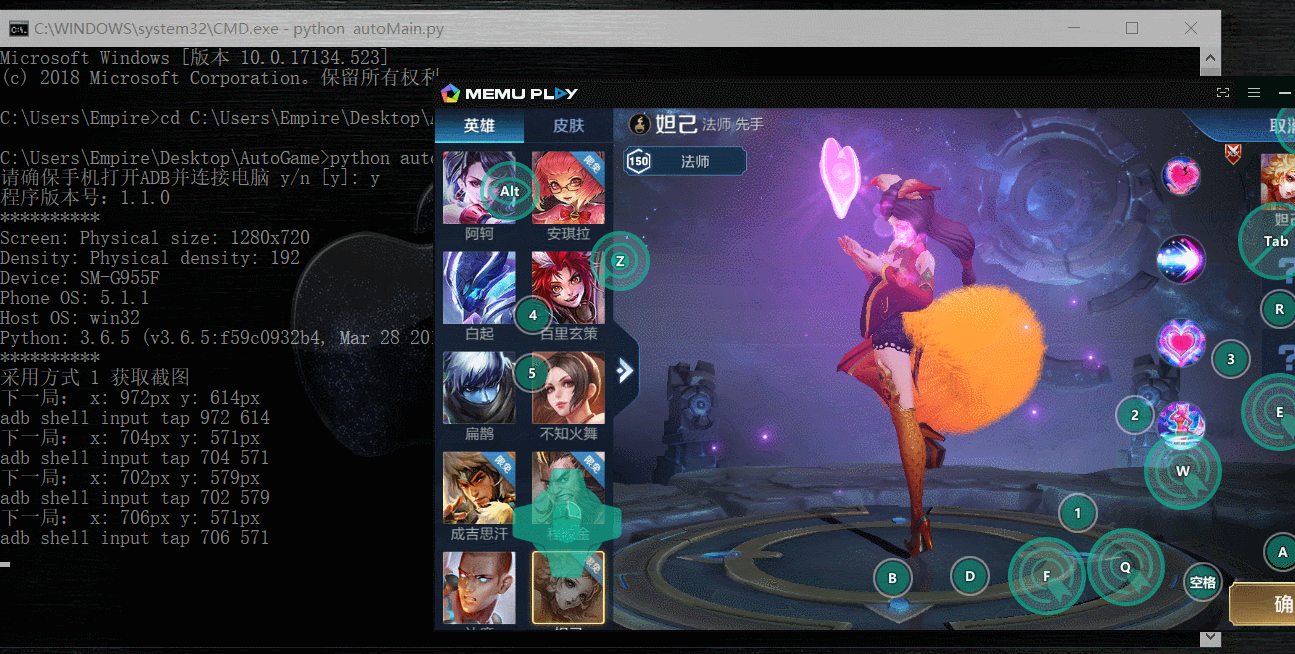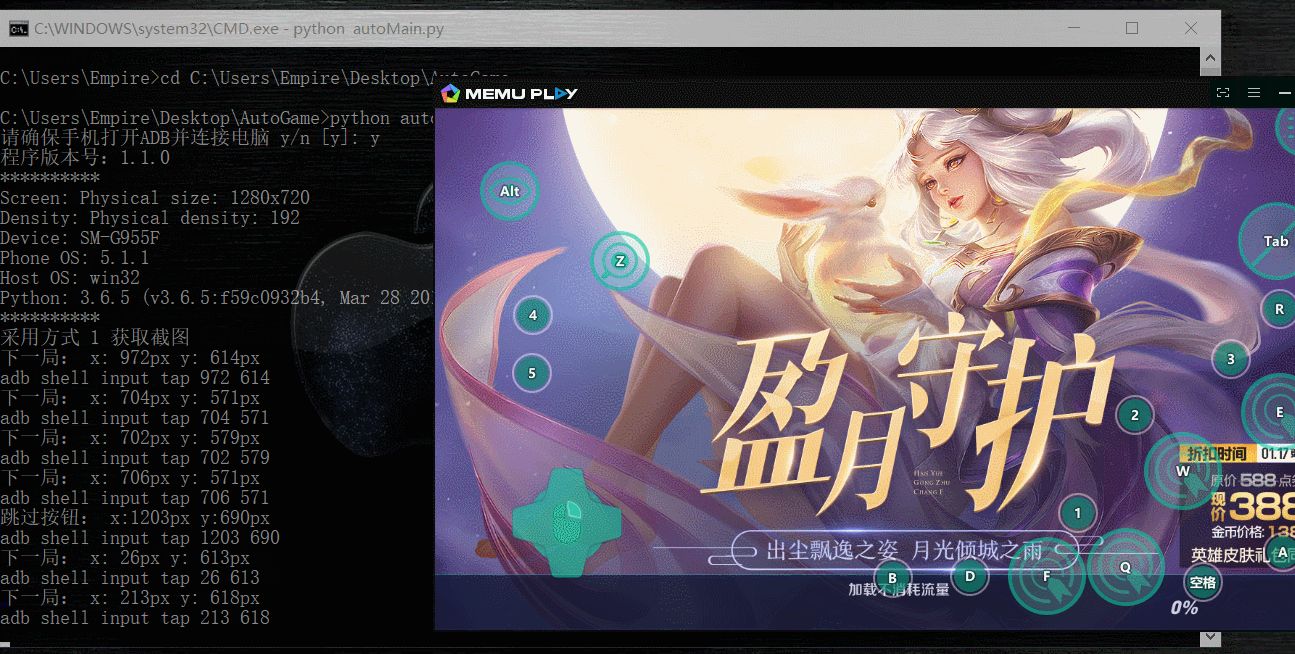

/***************************************************************************************************************************************************************************************************/
1.自动刷王者荣耀金币(主要):
配置环境
adb环境配置: https://www.cnblogs.com/yc8930143/p/8259486.html
i. pip 安装PIL模块
ii. pip安装six模块
iii. pip安装shutil模块
iv. pip安装subprocess模块
v. pip安装numpy模块
vi. pip安装matplotlib模块
模拟器或者手机什么的只要adb device 能识别就行,端口什么的不影响,然后命令行在文件根目录下运行即可。
过程:
基本环境弄好后,代码就是search_jump的像素识别(大小为模拟器或手机界面大小),在一定范围内进行点击,然后循环点击即可,感觉可以用到其他APP上面(比如全名K歌签到领取鲜花等等)或者服务器上装一个windows系统,这样就可以一直跑了.
注意:并不是只有一个automain.py代码,其中涉及到其他文件夹下的函数调用,主要就是模拟点击功能的实现吧。
代码解析:
screent_shot(屏幕截图):screen_way是截图方式,通过pull_screenshot和check_screenshot进行屏幕截图,便于后面图片像素分析(读者也可自己加入选择部分截图功能)
yes_or_no:基本连接手机或模拟器函数,判断电脑是否连接上外设
然后就是search_jump,game_next等基本函数了,感觉还是蛮容易理解的,给出源代码吧
链接: https://pan.baidu.com/s/1PXDPduSEUbAw-pOvrypM4A 提取码: am7s
2.爬取图片和验证码(次要)
识别官网API接口即可,然后简单处理信息,对于爬虫还算一个比较好的入门,给出完整代码
picture.py代码:
核心API接口就是:http://gamehelper.gm825.com/wzry/hero/list?game_id=7622 ,然后用户简单分析一下json数据即可
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/24 17:11
# @Author : Empirefree
# @File : 爬取照片.py
# @Software: PyCharm
import requests
import os
from urllib.request import urlretrieve
def download(url):
headers = {
'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'Keep-Alive'
}
res = requests.get(url, headers=headers).json()
hero_num = len(res['list'])
print('[Hero Num]:%d' % hero_num)
for hero in res['list']:
pic_url = hero['cover']
hero_name = hero['name'] + '.jpg'
filename = './images/' + hero_name
if 'images' not in os.listdir():
os.makedirs('images')
urlretrieve(url=pic_url, filename=filename)
print('[INFO]:Get %s picture...' % hero['name'])
if __name__ == '__main__':
print('**************************************************************************')
print('*****************!!!欢迎使用王者荣耀小助手!!!*************************')
print('*****************作者:Empirefree *********************')
print('*****************工具: Pycharm *********************')
print('*****************时间: 2018/9/24 17:11 *********************')
print('**************************************************************************')
download("http://gamehelper.gm825.com/wzry/hero/list?game_id=7622")
print('**************************************************************************')
print('照片已下载到您images目录下,请保证有网条件下执行本程序')
print('**************************************************************************')
n = input('回车结束........')
info.py代码
分析:和上述代码差不多,也是接口分析问题: http://gamehelper.gm825.com/wzry/equip/list?game_id=7622 ,个人感觉比较好用的就是网络图片下载的语句
下载图片:urlretrieve()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/24 17:49
# @Author : Empirefree
# @File : info.py
# @Software: PyCharm
import requests
import time
class Spider():
def __init__(self):
self.headers = {
'Accept-Charset': 'UTF-8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'Keep-Alive'
}
self.weapon_url = "http://gamehelper.gm825.com/wzry/equip/list?game_id=7622"
self.heros_url = "http://gamehelper.gm825.com/wzry/hero/list?game_id=7622"
self.hero_url = "http://gamehelper.gm825.com/wzry/hero/detail?hero_id={}"
print('*' * 60)
print('[INFO]:王者荣耀助手...')
print('[Usage]:请输入英雄ID获取英雄信息...')
print('[Author]:Empirefree')
print('*' * 60)
# 外部调用函数
def run(self):
heroId_exist = self._Get_HeroId()
heroId = input('\nEnter the Hero ID:')
if heroId not in heroId_exist:
print('[Error]:HeroId inexistence...')
return
weapon_info = self._Get_WeaponInfo()
self._Get_HeroInfo(weapon_info, heroId)
# 获得英雄ID
def _Get_HeroId(self):
res = requests.get(url=self.heros_url, headers=self.headers)
heros = res.json()['list']
num = 0
heroId_list = []
for hero in heros:
num += 1
print('%sID: %s' % (hero['name'], hero['hero_id']), end='\t\t\t')
heroId_list.append(hero['hero_id'])
if num == 3:
num = 0
print('')
return heroId_list
# 获取武器信息
def _Get_WeaponInfo(self):
res = requests.get(url=self.weapon_url, headers=self.headers)
weapon_info = res.json()['list']
return weapon_info
# 获得出装信息
def _Get_HeroInfo(self, weapon_info, heroId):
def seek_weapon(equip_id, weapon_info):
for weapon in weapon_info:
if weapon['equip_id'] == str(equip_id):
return weapon['name'], weapon['price']
return None
res = requests.get(url=self.hero_url.format(heroId), headers=self.headers).json()
print('[%s History]: %s' % (res['info']['name'], res['info']['history_intro']))
num = 0
for choice in res['info']['equip_choice']:
num += 1
print('\n[%s]:\n %s' % (choice['title'], choice['description']))
total_price = 0
for weapon in choice['list']:
weapon_name, weapon_price = seek_weapon(weapon['equip_id'], weapon_info)
print('[%s Price]: %s' % (weapon_name, weapon_price))
if num == 3:
print('')
num = 0
total_price += int(weapon_price)
print('[Ultimate equipment price]: %d' % total_price)
if __name__ == '__main__':
while True:
Spider().run()
time.sleep(5)
到此算是整理完王者荣耀写过的代码了,QAQ。