编译器:前端和后端
- 前端负责词法分析,语法分析,生成中间代码;
- 后端以中间代码作为输入,进行行架构无关的代码优化,接着针对不同架构生成不同的机器码.
前后端依赖统一格式的中间代码(IR),使得前后端可以独立的变化,新增一门语言只需要修改前端,而新增一个CPU架构只需修改后端即可。
Objective-C/C/C++使用的编译器前端是clang,swift是swift,后端都是LLVM
 

clang
clang是C语言家族的编译器前端,诞生之初是为了替代GCC,提供更快的编译速度。
 

#include <stdio.h>
#define DEBUG 1
int test() {
#ifdef DEBUG
printf("hello debug\n");
#else
printf("hello world\n");
#endif
return 0;
}
预处理(perprocessor)
预处理会替换行头引入,宏替换,注释处理,条件编译(#ifdef)等操作
预处理后
int test() {
printf("hello debug\n");
return 0;
}
词法分析(lexical anaysis)
词法分析器读入源文件的字符流,将他们组织成有意义的词素(lexeme)序列,对于每个词素,词法分析器产生的词法单元(token)作为输出。
xcrun clang -fmodules -fsyntax-only -Xclang -dump-tokens main.c
annot_module_include '#include <stdio.h>
#define DEBUG 1
int test() {
#ifdef DEBUG
printf("hello debug\n");
#else
printf("hello world\n");
#endif
' Loc=<test.m:9:1>
int 'int' [StartOfLine] Loc=<test.m:13:1>
identifier 'test' [LeadingSpace] Loc=<test.m:13:5>
l_paren '(' Loc=<test.m:13:9>
r_paren ')' Loc=<test.m:13:10>
l_brace '{' [LeadingSpace] Loc=<test.m:13:12>
identifier 'printf' [StartOfLine] [LeadingSpace] Loc=<test.m:15:5>
l_paren '(' Loc=<test.m:15:11>
string_literal '"hello debug\n"' Loc=<test.m:15:12>
r_paren ')' Loc=<test.m:15:27>
semi ';' Loc=<test.m:15:28>
return 'return' [StartOfLine] [LeadingSpace] Loc=<test.m:19:5>
numeric_constant '0' [LeadingSpace] Loc=<test.m:19:12>
semi ';' Loc=<test.m:19:13>
r_brace '}' [StartOfLine] Loc=<test.m:20:1>
eof '' Loc=<test.m:20:2>
语法分析(semantic analysis)
词法分析的token会被解析成一颗抽象语法树(abstract syntax tree - AST)
xcrun clang -fsyntax-only -Xclang -ast-dump main.c | open -f
有了抽象语法树,clang就可以对这个树进行分析,找出代码中的错误。比如类型不匹配,objective-C中向target发送一个未实现的消息。

CodeGen
CodeGen遍历语法树,生成LLVM IR代码。LLVM IR是前端的输出,后端的输入。
xcrun clang -S -emit-llvm main.c -o main.ll
Objective-C 代码在这一步会进行runtime的桥接:property合成,ARC处理等。
LLVM会对生成的IR进行优化,优化会调用相应的Pass进行处理。Pass由多个节点组成,都是 Pass 类的子类,每个节点负责做特定的优化。Writing an LLVM Pass
生成汇编代码
LLVM对IR进行优化后,会针对不同架构生成不同的目标代码,最后以汇编代码的格式输出:
xcrun clang -S main.c -o main.s
符号(Symbols):指向一段代码或者数据的名称。
WeakSymols:并不一定存在的符号,需要在运行时决定,比如iOS12特有API,在iOS11上就没有。
链接
连接器把编译产生的.o文件和(dylib,a,tbd)文件,生成一个mach-o文件。
from libSystem表示这个符号来自于libSystem,会在运行时动态绑定。
XCode编译
XCode开发的项目不仅仅包含了代码文件,还包括了图片,plist等。
- 创建Product.app文件夹
- 把Entitlements.plist写入到DerivedData里,处理打包的时候需要的信息(比如application-identifier)
- 创建一些辅助文件,比如.hmap。。。。
- 执行Cocoapods的编译前脚本:检查Manifest.lock文件。
- 编译.m文件,生成.o文件
- 链接动态库,.o文件,生成一个mach-o格式的可执行文件
- 编译assets,编译storyboard,链接storyboard。
- 拷贝动态库Logger.framework,并且对其签名
- 执行CococaPods编译后脚本:拷贝CoacoaPods Target生成的framework
- 对Demo.App签名,并验证(validate)
- 生成Product.app > Entitlements.plist保存了App需要使用的特殊权限,比如iCloud,远程通知,Siri等等
编译顺序
编译的时候有很多的Task要去执行,XCode如何决定Task的执行顺序?---> 依赖关系
 

XCode确定依赖关系:
- Target Dependencies - 显示声明的依赖关系
- Linked Frameworks and Libraries - 隐式声明的依赖关系
- Build Phase - 定义了编译一个Target的每一步
增量编译
XCode会对每一个Task生成一个哈希值,只有哈希值改变的时候才会重新编译。
比如,修改了ViewController.m,只有图中灰色三个Task会重新执行(不考虑build phase脚本)
 

头文件
C语言家族中,头文件用来引入函数/类/宏定义等声明,让开发者更灵活的组织代码,而不必把所有的代码写到一个文件里。
头文件对编译器来说就是一个promise。头文件里的声明,编译会人为有对应实现,在链接的时候再结晶具体实现的位置。
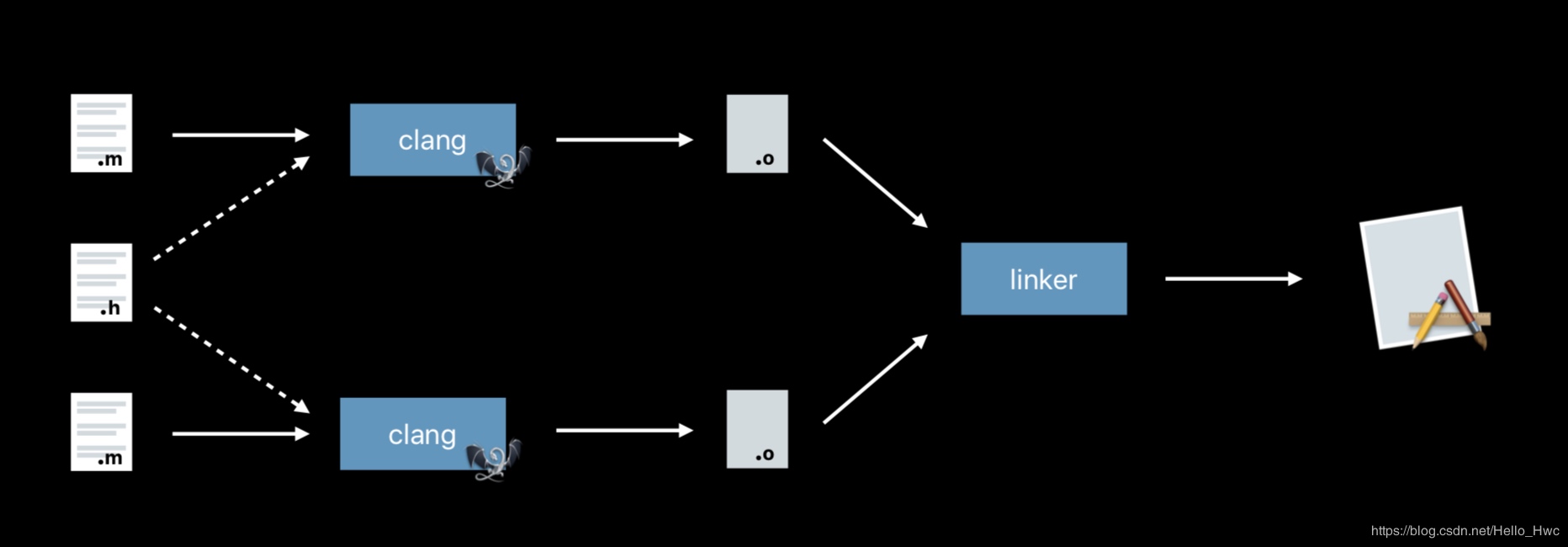 

当只有声明,没有实现的时候,链接器就会报错。
Objective C的方法要到运行时才会报错,因为Objective C是一门动态语言,编译器无法确定对应的方法名(SEL)在运行时到底有没有实现(IMP)。
#include "CustomClass.h" //自定义
#include <Foundation/Foundation.h> //系统或者内部framework
编译器是如何找到这些头文件的?
heademap是帮助编译器找到头文件的辅助文件:存储这头文件到其物理路径的映射关系。
Clang Module
传统的#include/#import都是文本语义:预处理在处理的时候会把这一行替换成对应的头文件的文本,这种简单粗暴替换是有很多问题的:
- 大量的预处理消化。假如有N个头文件,每个头文件又
#include了M个头文件,那么正规预处理的消耗是n*m。 - 文件导入后,宏的定义容易问题。因为文本导入,并且按照include依次替换,当一个头文件定义了
#define 实体店hello_world,而另一个头文件刚好又是C++标准库,那么include顺序不同,可能会导致所有的std都会被替换。 - 边界不明显。拿到一组.a和.h文件,很难确定.h是属于哪个.a的,需要以什么样的顺序导入才能正确编译。
clang module不再使用文本模型,二手采用更高效的语义模型。clang module提供了一种新的导入方式:@import,module会被作为一个独立的模块编译,并且产生独立的缓存,从而大幅提高预处理效率,这样时间消耗从m*n变成m+n。
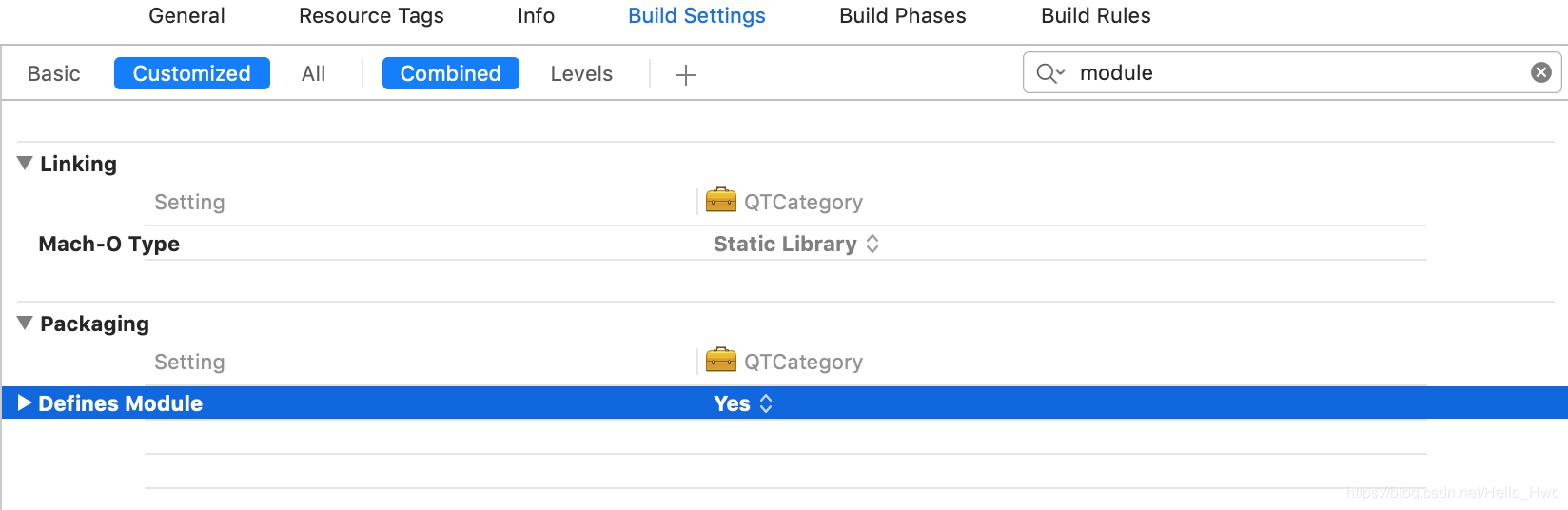
Xcode创建的Target是framework的时候,默认define module会设置为yes,从而支持module,当然像foundation等系统framework同样支持module。
#import<Foundation/NSString.h>的时候,编译器会检查NSString.h是否会在一个module里,如果是的话,这一行会被替换成@import Foundation

如何定义一个module呢?---> modulemap文件,这个文件描述了一组头文件如何转换为一个module,
framework module Foundation [extern_c] [system] {
umbrella header "Foundation.h" // 所有要暴露的头文件
export *
module * {
export *
}
explicit module NSDebug { //submodule
header "NSDebug.h"
export *
}
}
swift是可以直接import一个clang module,比如你有一些C库,需要在swift中使用,就可以用modulemap的方式。
Swift编译
现代化的语言几乎都抛弃了头文件。swift没有头文件又是如何找到声明的?
编译器干了这些脏活累活。编译一个swift头文件,需要解析module中的所有swift文件,找到对应的声明。

Objective C和Swift混用,两种语言在编译的时候查找符号的方式不同,如何一起工作的?
Swift引用Objective C
Swift编译器 内部使用了clang,所以swift可以直接使用clang module,从而支持直接import Objective C编写的framework。
 

swift编译器会从Objective C头文件里查找符号,头文件的来源分为两大类:
bridging-Header.h中暴露给swift的头文件- framework中公开的头文件,根据编写的语言不同,可能从modulemap或者umbrella header查找
xcode提供了宏定义NS_SWIFT_NAME来让开发者定义Objective C => Swift的符号映射,可以通过Related Items->Generate Interface来查看转换后的结果:
 

Objective引用Swift
xcode会以module为单位,为swift自动生成头文件,供Objective C引用,通常这个文件命名为ProductName-Swift.h
swift 提供了关键词 @objc来把类型暴露给Objective C和 Objective C Runtime
深入理解Linker
链接器会把编译器编译生成的多个文件,链接成一个可执行文件。链接并不会产生新的代码,只是在现有代码的基础上做移动和补丁。
链接器的输入可能是以下几种文件:
- object file(.o),单个源文件的编辑结果,包含了由符号表示的代码和数据
- 动态库(.dylib),mach o类型的可执行文件,链接的时候只会绑定符号,动态库会被拷贝到APP里,运行时加载
- 静态库(.a),由ar命令打包的一组.o文件,链接的时候会把具体的代码拷贝到最后的mach-o
- tbd:只包含符号的库文件
符号(Symbols):一段代码或者数据的名称,一个符号内部也有可能引用另一个符号
Mach-O有一个区域叫做LINKEDIT,这个区域用来存储启动时dyld需要动态修复的一些数据。