1、区分throws和throw
(1)throws
- 定义一个方法时,可以用throws关键字声明,使用throws关键字声明的方法表示此方法不处理异常,而交给方法调用处进行处理。
-
throws关键字格式:public 返回值类型 方法名称(参数列表,,,)throws 异常类{}。
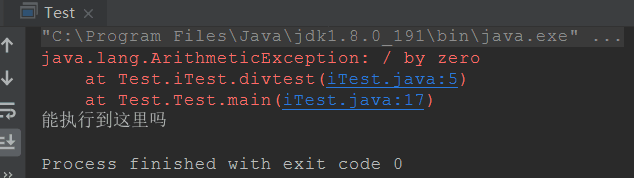
请看下面一段代码:
package Test;
public class iTest {
public static int divtest(int m, int n) throws Exception {
return m / n;
}
}
/**
* 因为divtest()方法中可能抛出异常,所以在Test中必须要用try-catch把调用了divtest()方法的代码包起来,
* 要么就向上交给主方法处理,那么能不能向上交给main()方法处理呢?
*/
class Test {
public static void main(String[] args){
try {
System.out.println(iTest.divtest(1, 0));
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("能执行到这里吗");
}
}
执行结果如下:
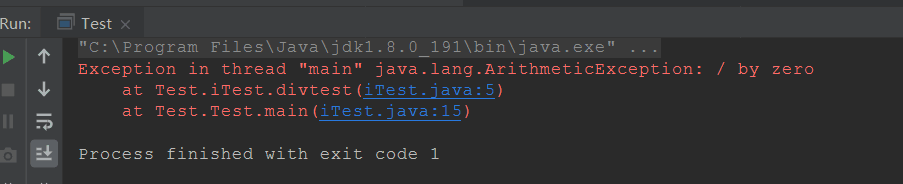
那么我们把异常交给main()方法处理呢?请看下面这段代码:
package Test;
public class iTest {
public static int divtest(int m, int n) throws Exception {
return m / n;
}
}
/**
* 如果把异常交给main()方法处理,main()方法本身不能处理任何一场,它会向上交给JVM处理
* 所以说如果在main()方法中使用了throws关键字的话,表示一切异常由JVM处理
*/
class Test {
public static void main(String[] args) throws Exception {
System.out.println(iTest.divtest(1, 0));
System.out.println("能执行到这里吗");
}
}
执行结果如下图所示:
(2)throw
throw关键字作用是抛出一个异常,抛出的时候是抛出的是一个异常类的实例化对象。示例代码如下所示:
package Test;
public class iTest {
public static int divtest(int m, int n) throws Exception {
try{
return m / n;
}catch(Exception e){
//抛出的异常对象中应该包含局部变量,参数等关键信息,以便排查问题
throw new Exception("除数为:"+n,e);
}
}
}
class Test {
public static void main(String[] args){
try {
System.out.println(iTest.divtest(1, 0));
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("能执行到这里吗");
}
}
执行结果如下图所示:

码出高效书中提出的建议:
- 无论使用哪种方式来处理异常,都严禁捕获异常后什么都不做或打印一行日志了事。
- 如果在方法内部处理异常,需要根据不同的业务场景进行定制处理,如重试、回滚等操作。
- 如果向上抛出异常,需要在异常对象中添加上下文参数、局部变量、运行环境等信息,这样有利于排查问题。
2、异常分类
JDK中定义了一套完整的异常机制,所有异常都是Throwable的子类,分为Error(致命异常)和Exception(非致命异常)。Error是一种非常特殊的异常类型,它的出现标识这系统发生了不可控的错误,例如StackOverflowError、OutOfMemoryError。针对此类错误,程序无法处理,只能人工介入。Exception又分为checked异常(受检异常)和unchecked异常(非受检异常)。
checked异常可以进一步细分为两类:
- 无能为力、引起注意型。针对此类异常,程序往往无法处理,如字段超长等导致的SQLException,即使做再多的重试对解决异常也没有任何帮助,一般处理此类异常做法是完整保存异常线长,供开发工程师介入解决。
- 利索能力、坦然处置型。如发生未授权异常(UnAuthorizedException),程序可跳转至权限申请页面。
unchecked异常是运行时异常,继承自RuntimeException,不需要程序进行显式地捕捉和处理,它可以分为3类:
- 可预测异常:常见的可预测异常包括NullPointException、IndexOutOfBoundException等,此类异常不应该被产生或抛出,而应该提前做好边界检查、空指针判断等处理。显式地声明或者捕获此类异常会对程序的可读性和运行效率产生很大影响。
- 需捕捉异常。
- 可透出异常。

在码出高效中,写了一个的事例来比喻各种异常类型:
我们为了保准准时乘坐某一航班,早早的赶到机场,却因为忘带身份证而导致无法登机,或者由于突降大雨而使航班延误等都会使我们的活动受阻。
- 机场地震,属于不可抗力,对应异常分类中的Error。在制定出行计划时,根本不需要把这部分的异常考虑进去(属于天灾人祸,我们无能为力,不需要考虑)。
- 堵车属于checked异常,应对这种异常,我们可以提前出发,或者改签机票。而飞机延误异常,虽然也需要check,但我们无能为力,只能持续关注航班动态(checked异常在写代码前我们需要考虑,但是也没有办法去处理可能出现的异常)。
- 没有带护照,明显属于可提前预测的异常,只要出发前检查即可避免(可预测异常,在写代码前就要考虑周到,避免出现这样的异常);去机场路上车子抛锚,这个异常是突发的,虽然难以预料,但是必须处理,属于需要捕捉的异常,可以通过更换交通工具应对(需捕捉异常是突发情况,虽然没法预测,但是也必须处理);检票机器故障则属于可透出异常,交由航空公司处理,我们无需关心(可透出异常是系统或框架自己产生的异常,跟我们的代码无关,由系统或框架自行处理)。
3、try代码块
try-catch-finally是处理程序异常的三部曲。当存在try时,可以只有catch代码块,也可以只有finally代码块,就是不能单独只有try这个光杆司令。下面说一下各个代码块的作用:
- try代码块:监视代码执行过程,一旦发现异常则直接跳转至catch,如果没有catch,则直接跳转至finally。
- catch代码块:可选执行的代码块,如果没有任何异常发生则不会执行;如果发现异常则进行处理或向上抛出。这一切都是在catch代码块中执行。
- finally代码块:必选执行的代码块,不管是否有异常产生,即使发生OutOfMemoryError也会执行,通常用于处理善后清理工作。如果finally代码块没有执行,那么有三种可能:(1)没有进入try代码块;(2)进入try代码块,但是代码运行中出现了死循环或死锁状态;(3)进入try代码块,但是执行了System.exit()操作。
注意!finally是在return表达式运行后执行的,此时将要return的结果已经被暂存起来,待finally代码块执行结束后再讲之前暂存的结果返回,如下代码所示:
package Test;
public class iTest {
public static int finallyNotWork(){
int temp = 10000;
try{
throw new Exception();
}catch(Exception e){
return ++temp;
}finally{
temp = 99999;
}
}
public static void main(String[] args){
System.out.println(iTest.finallyNotWork());
}
}
运行结果
10001
参照字节码:
//对变量temp进行+1操作
IINC 0 1
ILOAD 0
//return表达式的计算结果存储在slot_2上
ISTORE 2
//finally存储99999到slot_0上
LDC 99999
ISTORE 0
//方法返回的时候,直接提取的是slot_2的值,即10001
ILOAD 2
IRETURN码出高效作者建议:不要在finally代码块中使用return语句!!!这样会使得代码的返回值变得非常不可控!!!
如下段代码所示:
package Test;
public class TryCatchFinally {
static int x = 1;
static int y = 10;
static int z = 100;
public static void main(String[] args){
int value = finallyReturn();
System.out.println("value="+value);
System.out.println("x="+x);
System.out.println("y="+y);
System.out.println("z="+z);
}
//此段代码中没有出现异常,所以++x执行了,x=2,finally代码块中的++z也执行了,z=101
public static int finallyReturn(){
try{
return ++x;
}catch(Exception e){
return ++y;
}finally {
return ++z;
}
}
}
//执行结果如下:
//value=101
//x=2
//y=10
//z=101
上面这是没有出现异常的情形,再看下面出现了异常的代码:
package Test;
public class TryCatchFinally {
static int x = 1;
static int y = 10;
static int z = 100;
public static void main(String[] args){
int value = finallyReturn();
System.out.println("value="+value);
System.out.println("x="+x);
System.out.println("y="+y);
System.out.println("z="+z);
}
public static int finallyReturn(){
try{
//此处设定一个异常
int i = 1 / 0;
return ++x;
}catch(Exception e){
return ++y;
}finally {
return ++z;
}
}
}
//执行结果如下:
//value=101
//x=1
//y=11
//z=101
4、日志
4.1、什么是日志?
日志这个词最高见于航海领域,是记录航行主要情况的载体文件,内容包括操作指令、气象、潮流、航向、航速、旅客、货物等,是处理还是纠纷或者海难的原始依据之一。
同理,记录应用系统日志主要有三个原因:
- 记录操作轨迹:记录操作行为及操作轨迹数据,可以数据化地分析用户偏好,有助于优化业务逻辑,为用户提供个性化的服务。例如通过access.log记录用户的操作频度和跳转链接,有助于分析用户的后续行为。
- 监控系统运行状况:全面有效的日志系统有助于建立完善的应用监控体系,由此工程师可以实时监控系统运行状况,及时预警,避免故障发生。
- 回溯系统故障:当系统发生线上问题的时候,完整的现场日志有助于工程师快速定位问题。例如当系统内存溢出时,如果日志系统记录了问题发生现场的堆信息,就可以通过这个日志分析是什么对象在大量产生并且没有释放内存,回溯系统故障,从而定位问题。
4.2、日志的级别
日志是由级别的。针对不同的场景,日志被分为五种不同的级别,按照重要程度由低到高排序:
- DEBUG级别日志记录对调试程序有帮助的信息。
- INFO级别日志用来记录程序运行现场,虽然此处并未发生错误,但是对排查其他错误具有指导意义。
- WARN级别日志也可以用来记录程序运行现场,但是更偏向于表明此处有出现潜在错误的可能。
- ERROR级别日志表明当前程序运行发生了错误,需要被关注。但是当前发生的错误,没有影响系统的继续运行。
- FATAL级别日志表明当前程序运行出现了严重的错误事件,并且将会导致应用程序中断。
4.3、日志框架
日志框架分为散发部分,包括日志门面、日志适配器、日志库。利用门面设计模式,即Facade来进行解耦,使日志使用变得更加简单。日志结构框架如下图所示:

- 日志门面:门面设计模式是面向对象设计模式中的一种,日志框架采用的就是这种模式,类似JDBC的设计理念。它只提供一套接口规范,自身不负责日志功能的实现,目的是让使用者不需要关注底层具体是哪个日志库来负责日志打印及具体的使用细节等。目前使用最广泛的日志门面有两种:slf4j和commons-logging。
- 日志库:具体实现了日志的相关功能,主流日志库有三个,分别是log4j、log-jdk、logback。
- 日志适配器:日志适配器分两种应用场景,(1)日志门面适配器,因为slf4j规范是后来提出的,在此前的日志库是没有实现slf4j的接口的,例如log4j;所以在工程里要想使用slf4j+log4j的模式,就额外需要一个适配器(slf4j-log4j12)来解决接口不兼容的问题。(2)日志库适配器,在一些老的工程里,一开始为了开发简单而直接使用了日志库的API来完成日志打印,随着时间的推移想要将原来直接调用日志库的模式改为业界标准的门面模式(例如slf4j+logback组合),但老工程到吗里打印日志的地方太多,难以改动,所以需要一个适配器来完成从旧日志库的API到slf4j的路由,这样在不改动原有代码的情况下也能使用slf4j来统一管理日志,而且后续自由替换具体日志库也不成问题。
4.4、在Maven中进行日志集成
如果是新工程,推荐使用slf4j+logback模式。因为logback自身实现了slf4j的接口,无需额外引入适配器,另外logback是log4j的升级版,具备比log4j更多的有点,可通过如下代码配置:
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-api</artifactid>
<version>${slf4j-api.version}</version>
</dependency>
<dependency>
<groupid>ch.qos.logback</groupid>
<artifactid>logback-classic</artifactid>
<version>${logback-classic.verison}</version>
</dependency>
<dependency>
<groupid>ch.qos.logback</groupid>
<artifactid>logback-core</artifactid>
<version>${logback-core.version}</version>
</dependency>至此工程就完成了日志框架的集成,再加上一个日志配置文件(如logback.xml、log4j.xml等),并在工程启动时加载,然后就可以进行日志打印了,实例代码如下:
private static final Logger logger = LoggerFactory.getLogger(Abc.class);注意,logger被定义为static变量,是因为这个logger与当前类绑定,避免每次都new一个新对象,造成资源浪费,甚至引发OutOfMemeryError问题。