文章目录
kafka是啥
分布式流式平台
消息中间件
由scala开发

功能:
1.可读写流式数据
2.编写可扩展的流式程序实时处理数据
3.将流式数据安全存储在分布式的,有副本的容错集群
flume:1个进程 包括了source,channel,sink
kafka:3个进程 producer(生产者)broker(数据缓存)consumer(消费者)
flume–> kafka(存储) --> spark streaming/flink/结构化流
缓存数据存储在log,是liunx系统文件。
主题 topic
可以理解为就是数据的分类
假如有两个生产业务:
oms订单系统–mysql–>flume–>kafka( omstopic ) -->streaming1
wms仓库系统–mysql–>flume–>kafka( wmstopic ) -->streaming2
kafka创建主题 一般根据业务系统数据处理来划分
最终落在磁盘上就是创建文件夹(liunx系统文件夹)
mkdir omstopic
mkdir wmstopic
一个主题有n个分区,方便并行
1亿行
omstopic_0 100W/s log append追加(得有序) 自身的分区有序的
omstopic_1 200W/s log append追加 自身的分区有序的
omstopic_2 300W/s log append追加 自身的分区有序的


部署kafka之前要部署zookeeper
zookeeper伪分布式部署
修改conf下的zoo.cfg文件
zookeeper1
tickTime=2000
dataDir=/home/hadoop/app/zookeeper-1/data
clientPort=2181
server.1=192.168.137.190:2881:3881
server.2=192.168.137.190:2882:3882
server.3=192.168.137.190:2883:3883
zookeeper2
tickTime=2000
dataDir=/home/hadoop/app/zookeeper-2/data
clientPort=2182
server.1=192.168.137.190:2881:3881
server.2=192.168.137.190:2882:3882
server.3=192.168.137.190:2883:3883
zookeeper3
tickTime=2000
dataDir=/home/hadoop/app/zookeeper-3/data
clientPort=2183
server.1=192.168.137.190:2881:3881
server.2=192.168.137.190:2882:3882
server.3=192.168.137.190:2883:3883
分别在zookeeper-1,zookeeper-2和zookeeper-3三个目录下新建data文件夹
分别在zookeeper-1,zookeeper-2和zookeeper-3三个目录的data下新建myid文件,内容分别为server.1,server.2,server.3后面的数字
[hadoop@hadoop000 data]$ vi myid
[hadoop@hadoop000 data]$ cat myid
1
启动zookeeper三台

kafka版本
kafka cdh5.7.0 版本没有,在CDH当中kafka是独立分支,本次要安装的是kafka_2.11 - 0.10.2.2.tgz
scala2.11 版本
0.10.2.2 kafka版本
之所以用这个版本

在这里下载
百度http://mirror.bit.edu.cn/apache/kafka/
给kafka个软连接
软连接
具体用法是:ln -s 源文件 目标文件。
当 我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在其它的 目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。例如:ln -s /bin/less /usr/local/bin/less
-s 是代号(symbolic)的意思。
这 里有两点要注意:第一,ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;
ln -s kafka_2.11-0.10.2.2 kafka
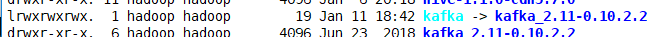

看看之前的zookeeper有没有kafka残留信息
进入一个zookeeper的bin,然后
[hadoop@hadoop000 bin]$ ./zkCli.sh

发现没有
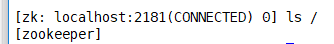
如果有,这样删除
[zk: localhost:2181(CONNECTED) 3] rmr /kafka
退出
[zk: localhost:2181(CONNECTED) 1] quit
kafka配置
三台伪分布式,修改server.properties等3个配置文件

server.properties
broker.id=0
log.dirs=/home/hadoop/app/kafka/logs/kafka0
zookeeper.connect=localhost:2181/kafka
host.name=192.168.137.190
port=9092
log.dirs是broker路径。
connect后面之所以加个/kafka,是为了所有kafka的文件都会被存在zookeeper的一个kafka文件夹下,方便以后管理
server-1.properties
broker.id=1
log.dirs=/home/hadoop/app/kafka/logs/kafka1
port=9093
host.name=192.168.137.190
zookeeper.connect=localhost:2181/kafka
server-2.properties
broker.id=2
log.dirs=/home/hadoop/app/kafka/logs/kafka2
port=9094
host.name=192.168.137.190
zookeeper.connect=localhost:2181/kafka
启动zookeeper后
启动kafka
用nohup不挂断
nohup 是 no hang up 的缩写,就是不挂断的意思。退出账号进程也能继续运行。
&是指在后台运行,但当用户推出(挂起)的时候,命令自动也跟着退出
装nohup
yum install coreutils
启动kafka
nohup bin/kafka-server-start.sh config/server.properties &
#看下情况
tail -F nohup.out
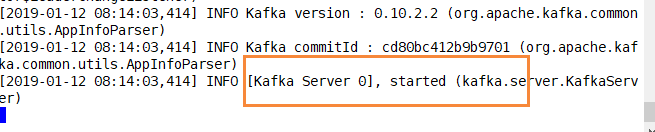
nohup bin/kafka-server-start.sh config/server-1.properties &
nohup bin/kafka-server-start.sh config/server-2.properties &

kafka常用命令
topic相关的操作
创建topic与查看
#clientport
#副本3,分区3
bin/kafka-topics.sh \
--create \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
--replication-factor 3 \
--partitions 3 \
--topic test
#查看kafka文件夹下
bin/kafka-topics.sh \
--list \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka
#查看我们创建的topic
bin/kafka-topics.sh \
--describe \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka
--topic test
有哪些topic

topic情况
第一行列出了这个topic的总体情况,如topic名称,分区数量,副本数量等。
第二行开始,每一行列出了一个分区的信息,如它是第几个分区,这个分区的leader是哪个broker(之前设的broker id)(先读写到这),副本位于哪些broker(replicas),有哪些副本处于同步状态(Isr)(活跃的副本列表,有可能成为leader,比如2挂了1顶上)。

文件夹里看下
3台机,3个分区,3个副本。kafka的分区数和spark的分区数应当设置成一样。

kafka落到磁盘就是log文件
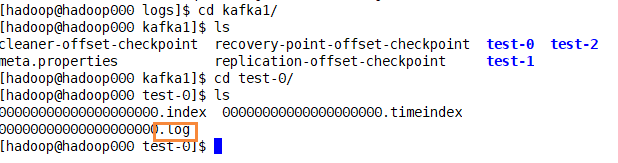
修改topic
先创建
bin/kafka-topics.sh \
--create \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
--replication-factor 1 \
--partitions 1 \
--topic g5
使用—-alert原则上可以修改任何配置,以下列出了一些常用的修改选项:
(1)改变分区数量
bin/kafka-topics.sh \
--alter \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
--topic g5 --partitions 3
bin/kafka-topics.sh --describe \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
--topic g5
删除topic
bin/kafka-topics.sh --delete \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
--topic test
删除的参数要设置为True才能删除,此时只是打了个删除的标识。

要在server.properties里都加上这个设置
delete.topic.enable=true
然后重启
[hadoop@hadoop000 kafka]$ kill -9 $(pgrep -f kafka)
nohup bin/kafka-server-start.sh config/server.properties &
nohup bin/kafka-server-start.sh config/server-1.properties &
nohup bin/kafka-server-start.sh config/server-2.properties &

bin/kafka-topics.sh \
--list \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka
重启后发现打了删除标识的主题被删除了

看看启用参数后能不能直接删除,而不需重启
bin/kafka-topics.sh --delete \
--zookeeper 192.168.137.190:2181,192.168.137.190:2182,192.168.137.190:2183/kafka \
--topic g5
list看发现被删除了
看下磁盘,也被删了

假如删除不干净
1.删除linux磁盘文件夹
2.删除zk的
删除brokers里的相关topics

删除config的
