第五篇仍然介绍隐层,这一篇其实是我最初要学习的主要内容——LSTM,LSTM的效果比rnn好,rnn存在的一个问题就是误差梯度会随着往前时刻深度的增加而逐渐减少消失,这样rnn的学习算法BPTT的深度就有了限制。LSTM解决了这样的问题,关于LSTM的结构的扩展也有几个阶段,这篇不会再去详细介绍LSTM了,关于LSTM更详细的介绍可以看看我写的另外一篇博客。仍然和前面一样,自己的认知与理解有限,哪里写的不对的还请看到的朋友指出,再次谢过~
LSTM的实现在lstm.cc里面,在rwthlm工具包里面,这是最核心的实现,也是代码量最大的部分,大概超过1000行代码的实现。首先把lstm.cc的构造函数放上来,其实通过构造函数的初始化分配,就能够把LSTM的网络结构给画出来,代码如下:
LSTM::LSTM(const int input_dimension,
const int output_dimension,
const int max_batch_size,
const int max_sequence_length,
const bool use_bias)
: Function(input_dimension,
output_dimension,
max_batch_size,
max_sequence_length),
sigmoid_(),
tanh_() {
//这里的一维数组仍然是前面那种类似的结构
int size = output_dimension * max_batch_size * max_sequence_length;
//lstm层的cell的输出
b_ = FastMalloc(size);
//保存cec的输入输出
cec_b_ = FastMalloc(size);
//cell的输入
cec_input_b_ = FastMalloc(size);
//保存输入控制门的输入输出
input_gate_b_ = FastMalloc(size);
//保存遗忘控制门的输入输出
forget_gate_b_ = FastMalloc(size);
//保存输出控制门的输入输出
output_gate_b_ = FastMalloc(size);
//_t_命名类指针都是会变动的,用于表示时间的变化
b_t_ = b_;
cec_input_b_t_ = cec_input_b_;
cec_b_t_ = cec_b_;
input_gate_b_t_ = input_gate_b_;
forget_gate_b_t_ = forget_gate_b_;
output_gate_b_t_ = output_gate_b_;
//这里不明白为啥要重新赋值,上面定义size时不就初始化为这个了嘛
size = output_dimension * max_batch_size * max_sequence_length;
//output gate的误差信号
cec_epsilon_ = FastMalloc(size);
delta_ = FastMalloc(size);
//输入控制门的误差
input_gate_delta_ = FastMalloc(size);
//遗忘控制门的误差
forget_gate_delta_ = FastMalloc(size);
//输出控制门的误差
output_gate_delta_ = FastMalloc(size);
//这里同上
cec_epsilon_t_ = cec_epsilon_;
delta_t_ = delta_;
input_gate_delta_t_ = input_gate_delta_;
forget_gate_delta_t_ = forget_gate_delta_;
output_gate_delta_t_ = output_gate_delta_;
//std::cout << "input_dimension: " << input_dimension << "\toutput_dimension: " << output_dimension << std::endl;
//假设命令是myExample-i10-M12
//这里的input_dimension就是10,output_dimension就是12
size = input_dimension * output_dimension;
//这里的权值仅仅是输入层到该lstm层的
weights_ = FastMalloc(size);
//下面控制门的权重仅仅是输入层到控制门的
input_gate_weights_ = FastMalloc(size);
forget_gate_weights_ = FastMalloc(size);
output_gate_weights_ = FastMalloc(size);
momentum_weights_ = FastMalloc(size);
momentum_input_gate_weights_ = FastMalloc(size);
momentum_forget_gate_weights_ = FastMalloc(size);
momentum_output_gate_weights_ = FastMalloc(size);
//这部分权重是循环结构的,即前一时刻lstm层到当前时刻lstm层的连接
size = output_dimension * output_dimension;
recurrent_weights_ = FastMalloc(size);
input_gate_recurrent_weights_ = FastMalloc(size);
forget_gate_recurrent_weights_ = FastMalloc(size);
output_gate_recurrent_weights_ = FastMalloc(size);
momentum_recurrent_weights_ = FastMalloc(size);
momentum_input_gate_recurrent_weights_ = FastMalloc(size);
momentum_forget_gate_recurrent_weights_ = FastMalloc(size);
momentum_output_gate_recurrent_weights_ = FastMalloc(size);
//从上面的分配来看,容易知道控制门的输入来自于3部分: 1.输入层的输出 2.本层的前一时刻输出 3.来自cec状态的前一时刻输出
//lstm层的输入自于这两部分:1.输入层的输出 2.本层的前一时刻输出
//peephole connection,这是从cec到gate的连接
input_gate_peephole_weights_ = FastMalloc(output_dimension);
forget_gate_peephole_weights_ = FastMalloc(output_dimension);
output_gate_peephole_weights_ = FastMalloc(output_dimension);
momentum_input_gate_peephole_weights_ = FastMalloc(output_dimension);
momentum_forget_gate_peephole_weights_ = FastMalloc(output_dimension);
momentum_output_gate_peephole_weights_ = FastMalloc(output_dimension);
//从这里的分配来看,能够知道lstm层内部的结构:
//output_dimension的大小即是block的大小,每个block大小包含一个cell,一个cell里面包含一个cec
//即output_dimension的大小就是cec个数,每个cec与三个gate连接
//bias的设置
bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
input_gate_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
forget_gate_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
output_gate_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
momentum_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
momentum_input_gate_bias_ = use_bias ?
FastMalloc(output_dimension) : nullptr;
momentum_forget_gate_bias_ = use_bias ?
FastMalloc(output_dimension) : nullptr;
momentum_output_gate_bias_ = use_bias ?
FastMalloc(output_dimension) : nullptr;
}从代码来看,能够得到LSTM网络的结构如下图:
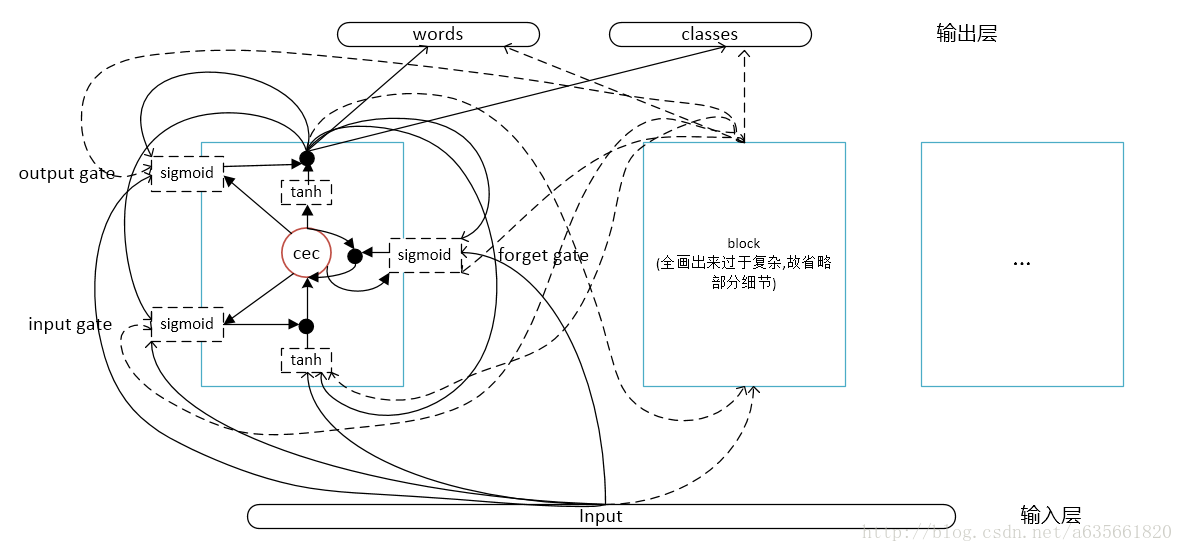
整个LSTM的结构是每个block(图中方框)包含一个cell(从tanh到tanh部分), 每个cell包含一个cec(图中红色圆圈) (PS: 这个图没画全,画了第一个block就已经觉的很复杂了,加上第二个估计会被连接线绕昏头了,而且比较费时,如果觉的不错,就点个赞吧,哈哈,开玩笑:D)
从代码的执行来看,容易知道每个block的输入来自于两部分:
- 输入层的输出
- 本层前一时刻block的输出
gate的输入来自于3部分:
- 输入层的输出
- 本层的前一时刻block输出
- 来自cec状态的前一时刻输出(对于input,forget gate而言, 对于output gate,来自于当前时刻cec输出)
cec的输入来自于两部分:
- block的输入,以及input gate的输出
- cec前一时刻的输出,以及forget的输出
另外LSTM结构的前向计算的顺序很重要,必须按照下面的来:
- input gate, forget gate的输入输出
- cell的输入
- output gate的输入输出
- cell的输出(这里也是block的输出)
误差的流向情况就把箭头反过来即可,这里另外提一点,在Felix提出peephole connection时,他的论文里面写到没有误差从cec通过peephole connection流向gate,但是在rwthlm里有点不一样,这里误差是流过去了的,而且peephole weight也会用BPTT学习算法来更新其权值。最后这里的学习算法是FULL BPTT,在之前Felix,Hochreiter所做实验用的LSTM网络学习算法是截断的BPTT + RTRL来进行更新的,我认为FULL BPTT反而还简单些,至少在公式看起来更容易懂吧,看前者的推导时,脑子里面一片茫然,大版大版的数学公式让我眼神恍惚诶。好啦,结合着前面写的,然后下面的lstm.cc的核心实现代码理解起来就比较容易了,带着注释贴上来,本篇完毕。
const Real *LSTM::Evaluate(const Slice &slice, const Real x[]) {
//形参x仍然表示前层的输入
//start为真表示起始时刻
const bool start = b_t_ == b_;
//OpenMP提供的并行功能
//下面两个section同时并行
#pragma omp parallel sections
{
//在带有peephole connection的lstm结构中,前向计算的顺序有要求
//1.先必须计算input gate和forget gate的输出
//2.计算cell输入和cec的状态
//3.计算output gate的输出
//4.计算cell的输出
#pragma omp section
//注意这里start的作用,起始时刻时,gate输入本来是包含peephole前一时刻cec的输出,和前一时刻层的输入两部分的
//但由于起始时刻,它们-1时刻的输出状态相当于0,这里不做计算
//只有t>0,即非起始时刻后,才会有前一时刻的输出
//计算input gate的输出
EvaluateSubUnit(slice.size(),
input_gate_weights_,
input_gate_bias_,
start ? nullptr : input_gate_recurrent_weights_,
start ? nullptr : input_gate_peephole_weights_,
x,
b_t_ - GetOffset(),
cec_b_t_ - GetOffset(),
input_gate_b_t_,
&sigmoid_);
#pragma omp section
//计算forget的输出
EvaluateSubUnit(slice.size(),
forget_gate_weights_,
forget_gate_bias_,
start ? nullptr : forget_gate_recurrent_weights_,
start ? nullptr : forget_gate_peephole_weights_,
x,
b_t_ - GetOffset(),
cec_b_t_ - GetOffset(),
forget_gate_b_t_,
&sigmoid_);
}
//计算cell的输入,它的输入来自于两部分,一部分是输入层,一部分是前一时刻本层的输出
EvaluateSubUnit(slice.size(),
weights_,
bias_,
start ? nullptr : recurrent_weights_,
nullptr,
x,
b_t_ - GetOffset(),
nullptr,
cec_input_b_t_,
&tanh_);
const int size = slice.size() * output_dimension();
//cec_b_t_ <= cec_input_b_t_ * input_gate_b_t_
//计算cec的输入
FastMultiply(input_gate_b_t_, size, cec_input_b_t_, cec_b_t_);
//非起始时刻执行,这里这样限制的原因是cec的输入来自于cell输入的一部分,还有cec前一状态的输出
//如果并非起始时刻,是不存在cec前一状态的输出的
//另外要注意,cec的结构是线性的,即为了保证误差的常数流,激活函数用的是f(x) = x
//所以计算cec的输入后,自然也是它的输出
if (!start) {
//cec_b_t_ <= cec_b_t_ + forget_gate_b_t_*cec_b_(t-1)_
FastMultiplyAdd(forget_gate_b_t_,
size,
cec_b_t_ - GetOffset(),
cec_b_t_);
}
//计算output gate的输出
EvaluateSubUnit(slice.size(),
output_gate_weights_,
output_gate_bias_,
start ? nullptr : output_gate_recurrent_weights_,
output_gate_peephole_weights_,
x,
b_t_ - GetOffset(),
cec_b_t_,
output_gate_b_t_,
&sigmoid_);
//这里将cec的输出拷贝到b_t_上了
FastCopy(cec_b_t_, size, b_t_);
//cec的输出经过tanh函数的压缩
tanh_.Evaluate(output_dimension(), slice.size(), b_t_);
//现在b_t_是整个cell的输出
FastMultiply(b_t_, size, output_gate_b_t_, b_t_);
const Real *result = b_t_;
b_t_ += GetOffset();
cec_input_b_t_ += GetOffset();
cec_b_t_ += GetOffset();
input_gate_b_t_ += GetOffset();
forget_gate_b_t_ += GetOffset();
output_gate_b_t_ += GetOffset();
return result;
}
//该函数是计算lstm层的输出
void LSTM::EvaluateSubUnit(const int batch_size,
const Real weights[],
const Real bias[],
const Real recurrent_weights[],
const Real peephole_weights[],
const Real x[],
const Real recurrent_b_t[],
const Real cec_b_t[],
Real b_t[],
ActivationFunction *activation_function) {
//存在偏置,复制过去,在下次计算时就相当于把偏置加上去了
if (bias) {
for (int i = 0; i < batch_size; ++i)
FastCopy(bias, output_dimension(), b_t + i * output_dimension());
}
//b_t <= b_t + weights * x
//这里计算层的输入
FastMatrixMatrixMultiply(1.0,
weights,
false,
output_dimension(),
input_dimension(),
x,
false,
batch_size,
b_t);
//非起始时刻
//b_t <= b_t + recurrent_weights * recurrent_b_t
//这部分层的输入来自上一时刻层的输出乘以recurrent_weights
if (recurrent_weights) {
FastMatrixMatrixMultiply(1.0,
recurrent_weights,
false,
output_dimension(),
output_dimension(),
recurrent_b_t,
false,
batch_size,
b_t);
}
//非起始时刻
if (peephole_weights) {
#pragma omp parallel for
for (int i = 0; i < batch_size; ++i) {
//b_t <= b_t + peephole_weights * cec_b_t
//这里gate的输入来自于cec的部分
FastMultiplyAdd(peephole_weights,
output_dimension(),
cec_b_t + i * output_dimension(),
b_t + i * output_dimension());
}
}
//上面计算的b_t_都是输入,下面这步后经过了相应激活函数,变成了输出
activation_function->Evaluate(output_dimension(), batch_size, b_t);
}
void LSTM::ComputeDelta(const Slice &slice, FunctionPointer f) {
//从时刻t到0
b_t_ -= GetOffset();
cec_input_b_t_ -= GetOffset();
cec_b_t_ -= GetOffset();
input_gate_b_t_ -= GetOffset();
forget_gate_b_t_ -= GetOffset();
output_gate_b_t_ -= GetOffset();
// cell outputs
//计算输出层传到lstm层的误差delta_t_
f->AddDelta(slice, delta_t_);
//并非句子末尾,如果当前时刻为t,要存在t+1时刻的相关计算
if (delta_t_ != delta_) {
//delta_t_ <= delta_t_ + recurrent_weights_ * delta_(t+1)_
//即计算t+1时刻lstm层的误差传到t时刻该层的误差
FastMatrixMatrixMultiply(1.0,
recurrent_weights_,
true,
output_dimension(),
output_dimension(),
delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
//delta_t_ <= delta_t_ + input_gate_recurrent_weights_ * input_gate_delta_(t-1)_
//input gate在t+1时刻的误差传到t时刻该层
FastMatrixMatrixMultiply(1.0,
input_gate_recurrent_weights_,
true,
output_dimension(),
output_dimension(),
input_gate_delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
//delta_t_ <= delta_t_ + forget_gate_recurrent_weights_ * forget_gate_delta_(t-1)_
//forget gate在t+1时刻的误差传到t时刻该层
FastMatrixMatrixMultiply(1.0,
forget_gate_recurrent_weights_,
true,
output_dimension(),
output_dimension(),
forget_gate_delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
//delta_t_ <= delta_t_ + output_gate_recurrent_weights_ * output_gate_delta_(t-1)_
//output gate在t+1时刻的误差传到t时刻该层
FastMatrixMatrixMultiply(1.0,
output_gate_recurrent_weights_,
true,
output_dimension(),
output_dimension(),
output_gate_delta_t_ - GetOffset(),
false,
slice.size(),
delta_t_);
}
//到这里delta_t_表示到达lstm层的误差,如果记L为目标函数,b为lstm层cell的输出
//现在delta_t_存放的是∂L/∂b
// output gates, part I
const int size = slice.size() * output_dimension();
//将cec的输出复制到output_gate_delta_t_
FastCopy(cec_b_t_, size, output_gate_delta_t_);
//cec的输出经过tanh函数,仍然存放到output_gate_delta_t_
tanh_.Evaluate(output_dimension(), slice.size(), output_gate_delta_t_);
// states, part I
//cec_epsilon_t_ <= output_gate_b_t_ * delta_t_
//这行语句是计算到达输出控制门那儿的激活函数前的误差
FastMultiply(output_gate_b_t_, size, delta_t_, cec_epsilon_t_);
//下面计算的是到达cec的误差,存放在cec_epsilon_t_,这只是流向cec误差的其中一部分
tanh_.MultiplyDerivative(output_dimension(),
slice.size(),
output_gate_delta_t_,
cec_epsilon_t_);
// output gates, part II
//output_gate_delta_t_ <= output_gate_delta_t_ * delta_t_
//这行语句是计算到达output gate的误差
FastMultiply(output_gate_delta_t_,
size,
delta_t_,
output_gate_delta_t_);
//下面计算的是output gate的误差信号,存放在output_gate_delta_t_
sigmoid_.MultiplyDerivative(output_dimension(),
slice.size(),
output_gate_b_t_,
output_gate_delta_t_);
// states, part II
#pragma omp parallel for
for (int i = 0; i < (int) slice.size(); ++i) {
//cec_epsilon_t_ <= cec_epsilon_t_ + output_gate_peephole_weights_ * output_gate_delta_t_
//这部分是output gate的误差信号流过来的
FastMultiplyAdd(output_gate_peephole_weights_,
output_dimension(),
output_gate_delta_t_ + i * output_dimension(),
cec_epsilon_t_ + i * output_dimension());
}
//即非最末时刻
if (delta_t_ != delta_) {
//cec_epsilon_t_ <= cec_epsilon_t_ + forget_gate_b_(t+1)_ * cec_epsilon_(t+1)_
//这部分是从cec的t+1时刻那儿流过来的误差
FastMultiplyAdd(forget_gate_b_t_ + GetOffset(),
size,
cec_epsilon_t_ - GetOffset(),
cec_epsilon_t_);
#pragma omp parallel for
for (int i = 0; i < (int) slice.size(); ++i) {
//cec_epsilon_t_ <= cec_epsilon_t_ + input_gate_peephole_weights_ * input_gate_delta_(t+1)_
//从input gate那儿流过来的误差
FastMultiplyAdd(input_gate_peephole_weights_,
output_dimension(),
input_gate_delta_t_ - GetOffset() + i * output_dimension(),
cec_epsilon_t_ + i * output_dimension());
//从forget gate那儿流过来的误差
FastMultiplyAdd(
forget_gate_peephole_weights_,
output_dimension(),
forget_gate_delta_t_ - GetOffset() + i * output_dimension(),
cec_epsilon_t_ + i * output_dimension());
}
}
// cells
//delta_t_ <= input_gate_b_t_ * cec_epsilon_t_
//下面两句计算cell输入处的误差信号
FastMultiply(input_gate_b_t_, size, cec_epsilon_t_, delta_t_);
tanh_.MultiplyDerivative(output_dimension(),
slice.size(),
cec_input_b_t_,
delta_t_);
//到现在delta_t_表示cell输入处的误差信号
#pragma omp parallel sections
{
#pragma omp section
{
// forget gates
if (b_t_ != b_) {
//forget_gate_delta_t_ <= cec_epsilon_t_ * cec_b_(t-1)_
//流向forget gate的误差
FastMultiply(cec_b_t_ - GetOffset(),
size,
cec_epsilon_t_,
forget_gate_delta_t_);
//计算forget gate的误差信号
sigmoid_.MultiplyDerivative(output_dimension(),
slice.size(),
forget_gate_b_t_,
forget_gate_delta_t_);
}
}
#pragma omp section
{
// input gates
//input_gate_delta_t_ <= cec_epsilon_t_ * cec_input_b_t_
//流向input gate的误差
FastMultiply(cec_epsilon_t_,
size,
cec_input_b_t_,
input_gate_delta_t_);
//计算input gate的误差信号
sigmoid_.MultiplyDerivative(output_dimension(),
slice.size(),
input_gate_b_t_,
input_gate_delta_t_);
}
}
}
//计算流向输入层的误差
void LSTM::AddDelta(const Slice &slice, Real delta_t[]) {
//delta_t <= delta_t + weights_ * delta_t_
//这里cell输入处的误差信号,流向输入层
FastMatrixMatrixMultiply(1.0,
weights_,
true,
input_dimension(),
output_dimension(),
delta_t_,
false,
slice.size(),
delta_t);
//delta_t <= input_gate_delta_t_ * input_gate_weights_ + delta_t
//input gate的误差信号流向输入层部分
FastMatrixMatrixMultiply(1.0,
input_gate_weights_,
true,
input_dimension(),
output_dimension(),
input_gate_delta_t_,
false,
slice.size(),
delta_t);
//delta_t <= forget_gate_delta_t_ * forget_gate_weights_ + delta_t
//forget gate的误差信号流向输入层部分
FastMatrixMatrixMultiply(1.0,
forget_gate_weights_,
true,
input_dimension(),
output_dimension(),
forget_gate_delta_t_,
false,
slice.size(),
delta_t);
//delta_t <= output_gate_delta_t_ * output_gate_weights_ + delta_t
//output gate的误差信号流向输入层部分
FastMatrixMatrixMultiply(1.0,
output_gate_weights_,
true,
input_dimension(),
output_dimension(),
output_gate_delta_t_,
false,
slice.size(),
delta_t);
//t+1时刻 -> t时刻
cec_epsilon_t_ += GetOffset();
delta_t_ += GetOffset();
input_gate_delta_t_ += GetOffset();
forget_gate_delta_t_ += GetOffset();
output_gate_delta_t_ += GetOffset();
}
const Real *LSTM::UpdateWeights(const Slice &slice,
const Real learning_rate,
const Real x[]) {
const int size = slice.size() * output_dimension();
//0到末尾时刻
cec_epsilon_t_ -= GetOffset();
delta_t_ -= GetOffset();
input_gate_delta_t_ -= GetOffset();
forget_gate_delta_t_ -= GetOffset();
output_gate_delta_t_ -= GetOffset();
#pragma omp parallel sections
{
#pragma omp section
{
if (bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
//momentum_bias_ <= -learning_rate*delta_t_ + momentum_bias_
//这是对cell的bias的改变量累加
FastMultiplyByConstantAdd(-learning_rate,
delta_t_ + i * output_dimension(),
output_dimension(),
momentum_bias_);
}
}
}
#pragma omp section
{
if (input_gate_bias_) {
//momentum_input_gate_bias_ <= -learning_rate*input_gate_delta_t_ + momentum_input_gate_bias_
//这是对input gate的bias改变量累加
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyByConstantAdd(-learning_rate,
input_gate_delta_t_ + i * output_dimension(),
output_dimension(),
momentum_input_gate_bias_);
}
}
}
#pragma omp section
{
//momentum_forget_gate_bias_ <= -learning_rate*forget_gate_delta_t_ + momentum_forget_gate_bias_
//这是对 forget gate的bias改变量累加
if (forget_gate_bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyByConstantAdd(-learning_rate,
forget_gate_delta_t_ + i * output_dimension(),
output_dimension(),
momentum_forget_gate_bias_);
}
}
}
#pragma omp section
{
//momentum_output_gate_bias_ <= -learning_rate*output_gate_delta_t_ + momentum_output_gate_bias_
//这是对 output gate的bias改变量累加
if (output_gate_bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyByConstantAdd(-learning_rate,
output_gate_delta_t_ + i * output_dimension(),
output_dimension(),
momentum_output_gate_bias_);
}
}
}
//以上部分是计算各个bias的改变量,但并未真正改变bias
#pragma omp section
{
//momentum_weights_ <= -learning_rate * delta_t_ * x + momentum_weights_
//这是计算输入层到lstm层权重的改变量
FastMatrixMatrixMultiply(-learning_rate,
delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_weights_);
}
#pragma omp section
{
//momentum_input_gate_weights_<= -learning_rate * input_gate_delta_t_ * x + momentum_input_gate_weights_
//这是计算输入层到 input gate 权重的改变量
FastMatrixMatrixMultiply(-learning_rate,
input_gate_delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_input_gate_weights_);
}
#pragma omp section
{
//momentum_forget_gate_weights_<= -learning_rate * forget_gate_delta_t_ * x + momentum_forget_gate_weights_
//这是计算输入层到 forget gate 权重的改变量
FastMatrixMatrixMultiply(-learning_rate,
forget_gate_delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_forget_gate_weights_);
}
#pragma omp section
{
//momentum_output_gate_weights_<= -learning_rate * output_gate_delta_t_ * x + momentum_output_gate_weights_
//这是计算输入层到 output gate 权重的改变量
FastMatrixMatrixMultiply(-learning_rate,
output_gate_delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_output_gate_weights_);
}
#pragma omp section
{
//momentum_recurrent_weights_<= -learning_rate * delta_t_ * b_(t-1)_ + momentum_recurrent_weights_
//这是计算t-1时刻lstm层到 t时刻自身权重的改变量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_recurrent_weights_);
}
}
#pragma omp section
{
//momentum_input_gate_recurrent_weights_<= -learning_rate * input_gate_delta_t_ * b_(t-1)_ + momentum_input_gate_recurrent_weights_
//这是计算t-1时刻lstm层到 t时刻 input gate权重的改变量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
input_gate_delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_input_gate_recurrent_weights_);
}
}
#pragma omp section
{
//momentum_forget_gate_recurrent_weights_<= -learning_rate * forget_gate_delta_t_ * b_(t-1)_ + momentum_forget_gate_recurrent_weights_
//这是计算t-1时刻lstm层到 t时刻 forget gate权重的改变量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
forget_gate_delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_forget_gate_recurrent_weights_);
}
}
#pragma omp section
{
//momentum_output_gate_recurrent_weights_<= -learning_rate * output_gate_delta_t_ * b_(t-1)_ + momentum_output_gate_recurrent_weights_
//这是计算t-1时刻lstm层到 t时刻 output gate权重的改变量
if (b_t_ != b_) {
FastMatrixMatrixMultiply(-learning_rate,
output_gate_delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_output_gate_recurrent_weights_);
}
}
//注意上面改变分为三部分:1.计算bias的改变量 2.计算输入层到cell各部分的权值改变量 3.计算t-1时刻cell到t时刻cell各部分权重改变量
}
#pragma omp parallel sections
{
#pragma omp section
{
if (b_t_ != b_) {
// destroys ..._gate_delta_t_, but this will not be used later anyway
//input_gate_delta_t_ <= -learning_rate*input_gate_delta_t_
//下面计算后,就破坏了input gate的误差信号值了,不过后面也不会再使用了。
FastMultiplyByConstant(input_gate_delta_t_,
size,
-learning_rate,
input_gate_delta_t_);
for (size_t i = 0; i < slice.size(); ++i) {
//momentum_input_gate_peephole_weights_ <= momentum_input_gate_peephole_weights_ + input_gate_delta_t_ * cec_b_(t-1)_
//计算 input gate到cec的权值改变量
FastMultiplyAdd(input_gate_delta_t_ + i * output_dimension(),
output_dimension(),
cec_b_t_ - GetOffset() + i * output_dimension(),
momentum_input_gate_peephole_weights_);
}
}
}
#pragma omp section
{
if (b_t_ != b_) {
//forget_gate_delta_t_ <= -learning_rate*forget_gate_delta_t_
FastMultiplyByConstant(forget_gate_delta_t_,
size,
-learning_rate,
forget_gate_delta_t_);
//momentum_forget_gate_peephole_weights_ <= momentum_forget_gate_peephole_weights_ + forget_gate_delta_t_ * cec_b_(t-1)_
//计算 forget gate到cec的权值改变量
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyAdd(forget_gate_delta_t_ + i * output_dimension(),
output_dimension(),
cec_b_t_ - GetOffset() + i * output_dimension(),
momentum_forget_gate_peephole_weights_);
}
}
}
#pragma omp section
{
//output_gate_delta_t_ <= -learning_rate*output_gate_delta_t_
FastMultiplyByConstant(output_gate_delta_t_,
size,
-learning_rate,
output_gate_delta_t_);
//momentum_output_gate_peephole_weights_ <= momentum_output_gate_peephole_weights_ + output_gate_delta_t_ * cec_b_(t-1)_
//计算 forget gate到cec的权值改变量
for (size_t i = 0; i < slice.size(); ++i) {
FastMultiplyAdd(output_gate_delta_t_ + i * output_dimension(),
output_dimension(),
cec_b_t_ + i * output_dimension(),
momentum_output_gate_peephole_weights_);
}
}
}
const Real *result = b_t_;
// let b_t_ point to next time step
//朝下一个时刻走
b_t_ += GetOffset();
cec_input_b_t_ += GetOffset();
cec_b_t_ += GetOffset();
input_gate_b_t_ += GetOffset();
forget_gate_b_t_ += GetOffset();
output_gate_b_t_ += GetOffset();
return result;
}