1、Sqoop 简介

Apache Sqoop(TM)是一种旨在有效地在Apache Hadoop和诸如关系数据库等结构化数据存储之间传输大量数据的工具。
Sqoop于2012年3月孵化出来,现在是一个顶级的Apache项目。最新的稳定版本是1.4.6。Sqoop2的最新版本是1.99.7。
Sqoop(SQL-to-Hadoop)是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是Mysql、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
如果要用Sqoop,必须正确安装并配置Hadoop,因依赖于本地的hadoop环境启动MR程序;mysql、oracle等数据库的JDBC驱动也要放到Sqoop的lib目录下。
2、Sqoop 原理
将导入或导出命令翻译成 mapreduce 程序来实现。
在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。
3、Sqoop 安装
安装 Sqoop 的前提是已经具备 Java 和 Hadoop 的环境。
3.1、下载并解压
1) 最新版下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
2) 上传安装包 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 到虚拟机中,如我的上传目录是: /opt/software
3) 解压 sqoop 安装包到指定目录,如:
![]()
3.2、修改配置文件
Sqoop 的配置文件与大多数大数据框架类似,在 sqoop 根目录下的 conf 目录中。
1) 重命名配置文件
![]()
2) 修改配置文件 sqoop-env.sh
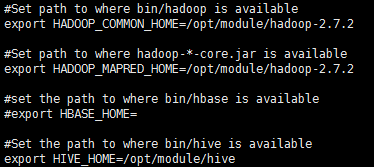
3)修改/etc/profile
![]()
注:sqoop-1.4.6.bin__此处2个下划线.
source /etc/profile使生效.
3.3、拷贝JDBC驱动
拷贝 jdbc 驱动到 sqoop 的 lib 目录下,如:
![]()
3.4、验证Sqoop
我们可以通过某一个 command 来验证 sqoop 配置是否正确:bin/sqoop help
问题:在命令行运行sqoop,提示:
Error: Could not find or load main class org.apache.sqoop.Sqoop
解决办法:
将sqoop解压后根目录下的sqoop-1.4.6.jar拷贝到~/hadoop-2.7.2/share/hadoop/hdfs/lib下即可。
出现一些 Warning 警告(警告信息已省略),并伴随着帮助命令的输出:

3.5、测试 Sqoop 是否能够成功连接数据库
同样需要将mysql驱动包拷贝到~/hadoop-2.7.2/share/hadoop/hdfs/lib下。

4、Sqoop 的简单使用案例
4.1、导入数据
在 Sqoop 中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE, HBASE)中传输数据,叫做:导入,即使用 import 关键字。
4.1.1、RDBMS 到 HDFS
1)、在 Mysql 中新建一张表并插入一些数据

2)导入数据
(1)全部导入:
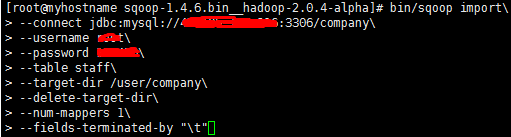
注:--前面都有空格, \为换行。
(2)查询导入:

注:must contain '$CONDITIONS' in WHERE clause。
如果 query 后使用的是双引号,则$CONDITIONS 前必须加转移符,防止 shell 识别为自己的变量。
--query 选项,不能同时与--table 选项使用。
(3)导入指定列:

注:columns 中如果涉及到多列,用逗号分隔,分隔时不要添加空格
(4)使用 sqoop 关键字筛选查询导入数据:

注:在 Sqoop 中可以使用 sqoop import -D property.name=property.value 这样的方式加 入执行任务的参数,多个参数用空格隔开。
4.1.2、RDBMS 到 Hive

注:该过程分为两步,第一步将数据导入到 HDFS,第二步将导入到 HDFS 的数据迁移到 Hive 仓库。
第一步默认的临时目录是/user/root/表名。
执行过程可以看到如下:第二步是迁移到hive仓库。

4.2、导出数据
在 Sqoop 中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群 (RDBMS)中传输数据,叫做:导出,即使用 export 关键字。
4.2.1、HIVE/HDFS 到 RDBMS

4.3、脚本打包
使用 opt 格式的文件打包 sqoop 命令,然后执行
1) 创建一个.opt 文件:
$ mkdir opt
$ touch opt/job_HDFS2RDBMS.opt
2) 编写 sqoop 脚本:
$ vi opt/job_HDFS2RDBMS.opt

3) 执行该脚本:
$ bin/sqoop --options-file opt/job_HDFS2RDBMS.opt