目录
1. 前景提要
在NLP的各种任务中,最关键的一个部分是如何获得完美的词向量(word representation)。因为一个词不仅有自己的语法信息,还包含了整个句子的语法语义信息。我们在分析一个单词的含义及作用时,是必须要将其放在具体语境中考虑的。因此最初的one-hot词表示完全不能体现词语的内层含义。因此我们要引入不同的词表示方法。
我理解的词表示方法(感觉和word embedding,以及word vector都是一个东西)是词语的低维高信息量表示,既能加速计算,又能获得更好的效果,何乐而不为呢^ ^。其实已经有很多成熟的生成词向量的方法,比如word2vec,它利用了skip-gram/CBOW, 考虑词以及其周围规定窗口内的单词之间的关系,构建了词向量,既降低了词的维度,又在向量内部蕴含和当前词与context中其他词之间的关系;又比如Glove也是一种构建词向量的方法,只不过其既考虑了单词的共现矩阵又考虑了context,可以说是传统词表示和神经网络词表示的结合。上述的词向量生成方法都是在训练LM的同时得到的,因此我们可以将词向量理解为LM或其他NLP任务的附属品。
然而以word2vec为例,它的主LM模型只是一个简单的单层神经网络(其实称不上是NN,只是简单的“线性+激活”),简单的模型根本无法很好的捕获语言句子的内部特性,比如长期依赖,词序的影响,等等。由此我们想到可以将LSTM,biRNN等技术加持到以LM为目的的词向量生成中,使得词向量蕴含更多有用的信息。同时由于不同的任务有着不同的语料库,我们很难保证所有人物都可以公用一套词向量表示,因此还需要根据不同的任务来对原词向量进行微调(也就是迁移学习)。下面我们就来了解一种利用biLSTM LM任务生成词向量并迁移到子任务的方法:Embedding from Language Models。
2. ELMo
ELMo先使用一个深层双向LSTM,在一个大的语料库上构建语言模型,同时生成词向量(注意这里是character-based,即tokenize时将单词拆分成字符,解决了unseen word 和morphology的问题);然后将上述词向量结合到当前任务已有的词向量中,进行微调(迁移学习);最终获得的词向量再进行进一步的supervised 学习。
2.1 Stack BiLSTMs LM
在大corpus上训练LM。使用的网络结构是:多层双向LSTM。如下图所示:

首先需要强调的一点是:模型是character-based而不是word-based,这在一定程度上解决了unseen word的出现。也体现了语言的morphology的特性。
在训练网络的过程中,对于每个token,,每一层都对应了一个前向隐藏层输出
,一个后向隐藏层输出
,若有L层,则时间t时的token就会有2L+1个表示(
本身,每一层都有前后向两个h,总共2L+1个)。
接着,对于每个token ,我们将2L+1个token表示做一个线性组合平均,得到了一个总的token向量。计算方法如下。(注意ELMo是使用了所有层的输出h来表征一个token,也有一些研究是利用了最后一层
来作为最终的表示(TagLM, GoVe)。)

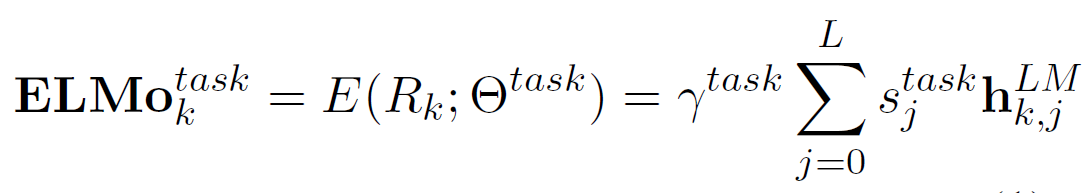
:表示2L+1个token向量的合集;
:表示这个LM生成的token向量,k表示第k个token,l表示第l层,其中l=0时即为
。
:用于task任务时所得到的平均token向量。
:是一个超参数,可以理解为一种标准化,作用和BN相似。
:使用softmax生成一个类似于概率的系数。
2.2 Transfer Learning
现在我们需要将上述的LM中得到的token向量迁移到特定的supervised NLP任务中。假设我们称这个任务为T,则T本身的输入可能用到了一些已有的word embedding 的方法(word2vec,glove,fasttext...)获得了初步的token向量,我们称这个最初的token向量为(注意区别于2.1中LM中的
)。那么我们要做的就是:将2.1中LM得到的token向量
和
连接在一起,形成一个新的token向量[
;
],然后进行supervised NLP任务。需要注意的一点是:2.1中的BiLSTM LM 的参数是固定不变的(freezed),微调只是微调新任务中的参数。
原论文中描述如下:
To add ELMo to the supervised model, we first freeze the weights of the biLM and then concatenate the ELMo vector
with
and pass the ELMo enhanced representation [
2.3 论文使用的其他trick
- dropout
- L2 正则
- residual connection between LSTM layers
论文中详细列出了整个模型的结构:

2.4 论文实验结果
也是截取了论文的部分。可以看出在6个不同的NLP task中, ELMo都有着不错的表现。

3. 小结
ELMo使用一种迁移学习的方法,将在大语料库复杂LM模型上训练得到的token向量加入到其他supervised任务中,新的token向量确实帮助提升了性能。原因显而易见,复杂模型大语料库(stack biLSTMs)应该会强于简单的模型(word2vec)。然而,还是有两个小疑问:
- 虽然是stack的所谓深层次LSTM,其实原论文也只是使用了2层。RNN似乎很少会使用深层网络,原因可能归结于RNN本身展开后就是一个深度前向网络了,尤其是输入的序列很长的时候,如果再累积多层,那么整个模型的训练会很缓慢(保持怀疑,虽然展开后很深,但同时参数是共享的,参数量级不会变很大,可能是因为更新的次数太多也是会消耗很多时间的吧。。。)。
- 在CNN中,浅层可以捕捉图像概略的信息(edge,shape),深层可以捕捉图像详细的信息(眼睛?鼻子?猫?狗?)。那么对应到RNN中,如果使用深层的话,是不是浅层可以捕捉词的‘语法信息’比如POS,深层可以捕捉词的“语义语境”等深层次信息比如word sense。
AllenNLP提供了ELMo的工具包,在这个网站的首页也列出了ELMo的优点:
ELMo representations are:
- Contextual: The representation for each word depends on the entire context in which it is used.
- Deep: The word representations combine all layers of a deep pre-trained neural network.
- Character based: ELMo representations are purely character based, allowing the network to use morphological clues to form robust representations for out-of-vocabulary tokens unseen in training.