-
决策树简述
决策树,它的精髓就是决策,可以认为它是 if-then 规则的集合构建成树形结构的模型。(另,也可认为是定义在特征空间与类空间上的条件概率分布。)
-
if-then 规则
由决策树的根节点到叶节点的每一条路径构建一条规则则;路径上内部节点的特征对应着规则的条件,而叶节点的类对应着规则的结论。
其中,对于数据集中的每一个实例都被一条且只有一条路径或规则覆盖。
-
条件概率分布
此条件概率分布定义在特征空间的一个划分上。将特征空间划分为互不相交的单元或区域,并在每个单元定义一个类的概率分布,就构成了一个条件概率分布。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。具体的,
对于包含 N 个样本的数据集,假设每个样本具有的特征为: ,从 n 个特征 合理 选择一个 ,而后根据 的取值进行分类,如果 取值是离散的,则按值分类;如果 取值是连续的,则可以按区间划分;接着再根据不同的 对已经在上一轮划分好的样本基础上继续划分。
那么上文中提到的“合理”是怎样的,对于 , 又是依据什么进行选取的呢?接着看下文。
-
-
决策树过程
对于决策树的生成,主要运用熵的计算。熵的基础概念在上文《机器学习 - 决策树(上)- 信息论基础》已经做了介绍,不再赘述。对于合理的选择特征,关键在于生成一棵熵不断下降,且下降速度最快的树。
直接上实例:
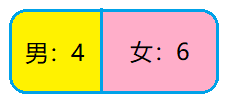
假设有数量为 10 的数据集 ,其中女生 6 人, 男生 4 人,每个样本都具有特征 (具体数据见下表)。
以此数据建立决策树,并预测新样本为男生还是女生。
样本ID 喜爱节目类型 学历 性别 1 偶像剧 小学 女 2 偶像剧 初中 女 3 偶像剧 小学 男 4 战争剧 初中 女 5 偶像剧 初中 女 6 战争剧 小学 男 7 偶像剧 小学 女 8 战争剧 初中 男 9 战争剧 初中 男 10 偶像剧 小学 女 对于数据集 ,目标为预测性别。
在未分类的时候(即根节点)的熵为香农熵:
假设以学历作为划分依据 ,取值有 2 种,则分为 2 个分支:

此时对于整个数据集 所包含的信息用条件熵来计算:
假设以喜爱节目类型作为划分依据 ,取值 2 中,则分为 2 支:

同理可以计算出:以上,具有两种划分方式(学历,喜爱节目类型),那么该以哪个特征作为划分呢?(以下用 “类型” 代替 “喜爱节目类型”)
-
ID3
ID3 是通过 信息增益(互信息) 来衡量特征选取优劣的,即在划分后,计算信息量的改变量,改变量大的意味着带给我们更多的信息,那么它就是更优的特征。
计算公式为: ,具体的,
对于学历,其信息增益为:
对于喜爱的节目类型,其信息增益为:
因为 所以选用“喜爱的节目类型”作为划分特征。
-
C4.5
C4.5 是通过 信息增益比 来衡量优劣。
以信息增益作为划分标准,存在偏向于选择取值较多的特征的问题,因为信息增益反映的给定一个条件以后不确定性减少的程度,必然是分得越细数据集整体的确定性越高,也就是条件熵越小,信息增益越大。使用信息增益比可以对这一问题进行校正。
信息增益比的计算公式为:
其中 为数据集 关于特征 A 的值的熵(对特征 A 的取值个数进行衡量)。具体的,
对于学历,其
其信息增益比为:
对于喜爱的节目类型,其
其信息增益比为:
因为 所以选用 “喜爱的节目类型” 作为划分特征。
-
过拟合
对于树的过拟合现象,有两种解决办法,第一种采用“随机森林+Bagging” 的策略(有关 Bagging 的详情可参阅 《机器学习 - 集成方法(Bagging VS. Boosting)》)
另一种方法为剪枝。而剪枝又分为预剪枝与后剪枝。对于预剪枝,其含义为在完全拟合整个数据集之前停止增长,但是停止的标准难以确定。下面主要介绍后剪枝。
后剪枝的策略是先让树以最大规模生长,而后自底向上修建。不过缺点是之前生成完全树的计算被浪费。
剪枝定义
此算法考虑树的复杂度,通过极小化决策树整体损失来实现。
设树为 ,叶节点个数为 , 是树 的叶节点,每个叶节点有 个样本点。其中属于 类的样本点有 , 为叶节点 上的经验熵, 为参数。
那么损失函数为:
令 ,
则 ,
表示模型对训练数据的预测误差, 表示模型复杂度;
参数 控制对复杂度的要求:
剪枝过程
在生成完全树之后:
(1) 计算每个结点的经验熵;
(2) 递归地从树的叶节点向上回缩,若修剪前的树为 ,修剪后的树为 ,对应的损失函数值为 。
若 ,则进行剪枝,将父节点变为新的叶节点,而此叶节点的类别通过投票决定;
(3) 返回 (2) ,直至无法继续。
-
机器学习 - 决策树(中)- ID3、C4.5 以及剪枝
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37352167/article/details/84894733
猜你喜欢
转载自blog.csdn.net/weixin_37352167/article/details/84894733
今日推荐
周排行