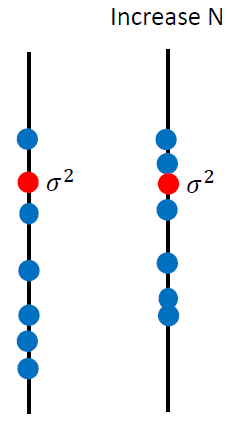
| //李宏毅视频官网:http://speech.ee.ntu.edu.tw/~tlkagk/courses.html 点击此处返回总目录 //邱锡鹏《神经网络与深度学习》官网:https://nndl.github.io 我们上一次讲到,使用不同的model,在testing data上会得到不同的error。而且越复杂的model不一定会得到越低的error。 今天我们要讨论的问题是,error来自什么地方。 其实error有两个来源,一个是"bias",一个是“variance”。了解error的来源是重要的,因为你常常做一下machine learning,做完就得到一个error,接下来你要怎么improve你的model呢。如果没有什么方向,毫无头绪的乱做,你就没有效率。如果你可以诊断你的error的来源,你就可以挑选适当的方法来improve你的model。 ------------------------------------------------------------------------------------------------------------------------------- 上一节的时候,我们要预测宝可梦进化后的CP值,也就说要找一个function,这个function input一只宝可梦,output就是进化后的CP值。这个function理论上有一个最佳的function,我们写成f^。但是这个理论上最佳的function我们是不知道的,只有Niantic是知道的,Niantic就是做宝可梦的公司。f^是我们不知道的,我们能做的事情就是,实际去抓一些宝可梦,根据training data,去学到的最好的function,f*。f*并不会真的等于f^,因为并不知道f^是什么样子,f*可能不等于f^。f*就好像是f^的估测值一样。 就想成,是在打靶。f^是靶的中心,收集到一些data,做training以后,你找到一个你觉得最好的function f*,这个f*不等于f^,它是在靶纸上的另外一个位置。这个f*与f^中间有一段距离,这个距离呢,来自于两件事:它可能来自于bias,也可能来自于variance。 ------------------------------------------------------------------------------------------------------------------------------- bias和variance是什么呢?我们先举一个概率里面的例子,概率与统计学过。 假设有一个变量x,想要估计它的mean,怎么做呢?假设x的mean是 要估测 N个点算平均值m会跟 假设红点为 但是,如果今天把m的期望值算出来的话: 得到的值就是 那散步在周围会散的多开呢?取决于m的variance。 variance的值呢depends on samples的个数。如果N比较多的话,就会比较集中。如果N比较少,就会分散地比较开。 要估测variance,即
即, |
Where does the error come from
版权声明:未经同意,严禁转载 https://blog.csdn.net/pengchengliu/article/details/85223751




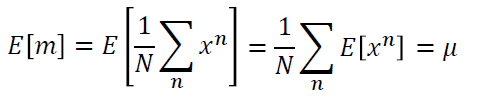
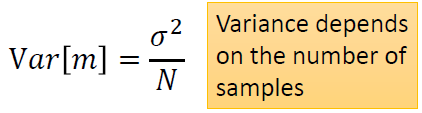

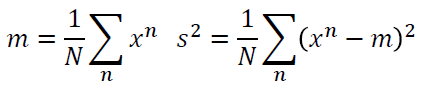
猜你喜欢
转载自blog.csdn.net/pengchengliu/article/details/85223751
今日推荐
周排行