算法工程师修仙之路:吴恩达机器学习(四)
其他
2018-12-08 16:57:32
阅读次数: 0
吴恩达机器学习笔记及作业代码实现中文版
第四章 Logistic回归
分类
-
在分类问题中,要预测的变量y是离散的值,逻辑回归 (Logistic Regression) 算法是目前最流行使用最广泛的一种学习算法。
-
在分类问题中,我们尝试预测的是结果是否属于某一个类
- 正确或错误。
- 判断一封电子邮件是否是垃圾邮件。
- 判断一次金融交易是否是欺诈。
- 区别一个肿瘤是恶性的还是良性的。
-
我们将因变量(dependent variable)可能属于的两个类分别称为负向类(negative class)和正向类( positive class),则因变量 y只取0或1,其中 0 表示负向类,1 表示正向类。
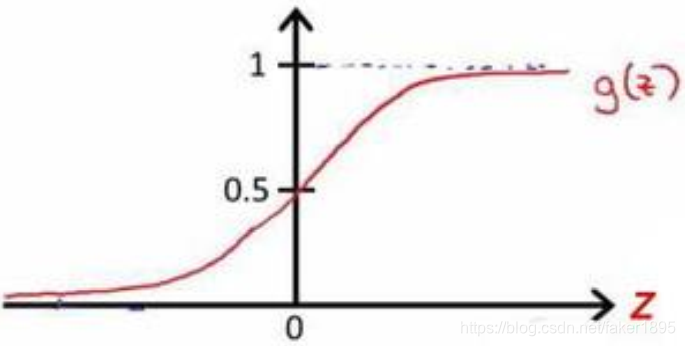
假设陈述
决策界限
代价函数
-
对于线性回归模型,我们定义的代价函数是所有模型误差的平方和。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们将
hθ(x)=1+e−θT(x)1带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数( non-convexfunction)。这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
-
我们重新定义逻辑回归的代价函数为:
-
J(θ0,θ1,...,θn)=m1∑i=1mCost(hθ(x(i)),y(i))
-
Cost(hθ(x(i)),y(i))=−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))。
-
这样构建的函数的特点是:
-
当实际的y=1且
hθ(x)也为1时误差为 0。
-
当y=1但
hθ(x)不为 1 时误差随着
hθ(x)变小而变大。
-
当实际的y=0且
hθ(x)也为 0 时代价为 0。
-
当y=0但
hθ(x)不为 0 时误差随着
hθ(x)的变大而变大。
-
代价函数
J(θ)会是一个凸函数,并且没有局部最优值。
import numpy as np
def cost(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X* theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X* theta.T)))
return np.sum(first - second) / (len(X))
-
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使代价函数最小的参数了。
-
逻辑回归的梯度下降算法推导:
-
J(θ0,θ1,...,θn)=−m1∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))] 。
- 考虑:
hθ(x(i))=1+e−θTx(i)1。
- 则:
y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))=y(i)log(1+e−θTx(i)1)+(1−y(i))log(1−1+e−θTx(i)1)=−y(i)log(1+e−θTx(i))−(1−y(i))log(1+eθTx(i))。
- 所以:
∂θj∂J(θ)=∂θj∂[−m1∑i=1m[−y(i)log(1+e−θTx(i))−(1−y(i))log(1+eθTx(i))]]=−m1∑i=1m[−y(i)(1+e−θTx(i)−xj(i)e−θTx(i))−(1−y(i))1+eθTx(i)xj(i)eθTx(i)]=−m1∑i=1m[y(i)(1+eθTx(i)xj(i))−(1−y(i))1+eθTx(i)xj(i)eθTx(i)]=−m1∑i=1m[1+eθTx(i)y(i)xj(i)−xj(i)eθTx(i)+y(i)xj(i)eθTx(i)]=−m1∑i=1m[1+eθTx(i)xj(i)[y(i)(1+eθTx(i))−eθTx(i)]]=−m1∑i=1m(y(i)−1+eθTx(i)eθTx(i))xj(i)=−m1∑i=1m(y(i)−1+e−θTx(i)1)xj(i)=−m1∑i=1m[y(i)−hθ(x(i))]xj(i)=m1∑i=1m[hθ(x(i))−y(i)]xj(i)。
-
虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的
hθ(x)=g(θTX)与线性回归中不同,所以实际上是不一样的。另外,在运行梯度下降算法之前,进行特征缩放依旧是非常必要的。
转载自blog.csdn.net/faker1895/article/details/84677916