前言:
GC发展阶段:Serial => Parallel(并行)=> CMS(并发)=>G1=>ZGC
GC回收过程:
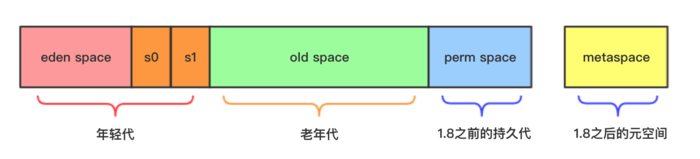
堆被分解为较小的三个部分:新生代、老年代、持久代。
1、绝大部分新生成的对象都放在Eden区,当Eden区将满JVM会因申请不到内存,而触发Young GC ,进行Eden区+有对象的Survivor区(设为S0区)的垃圾回收,把存活的对象用复制算法拷贝到一个空的Survivor(S1)中,此时Eden区被清空,另外一个Survivor S0也为空,下次触发Young GC回收Eden+S0,将存活对象拷贝到S1中。新生代垃圾回收简单、粗暴、高效。
2、若发现Survivor区满了,则将这些对象拷贝到old区或者Survivor没满但某些对象足够Old,也拷贝到Old区(每次Young GC都会使Survivor区存活对象值+1,直到阈值)。
3、JVM在Old区申请不到内存,进行垃圾收集(Major GC,一般采用CMS,一般比Young GC慢十倍以上)。
4、如果对象内存分配速度过快来不及回收导致老年代被填满,会触发CMS的担保机制(serial old gc)。
一、G1回收器
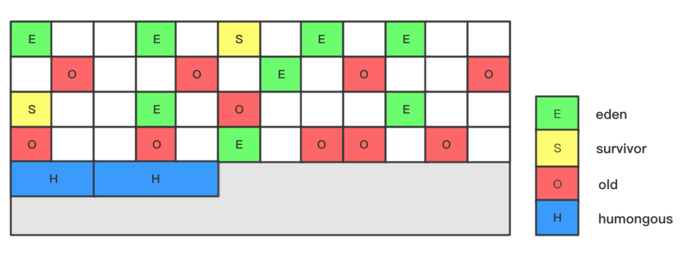
1、引入分区的思路,弱化了分代的概念(本质上来G1垃圾回收器依然是一个分代垃圾回收器):
在G1中没有物理上的Yong(Eden/Survivor)/Old Generation,它们是逻辑的使用一些非连续的区域(Region)组成的,每个Region是动态变化的但只会属于一种角色。
2、软实时(soft real-time):
实时垃圾回收是指在要求的时间内完成。“软实时”则是指用户可以指定垃圾回收时间,G1会努力在这个时间内完成垃圾回收,但并不担保每次都能在这个时限内完成垃圾回收。通过设定一个合理的目标,可以让达到90%以上的垃圾回收时间都在这个时限内。
二、G1的概念
1、Region
G1垃圾回收器把堆划分成一个个大小相同的Region。在HotSpot的实现中,整个堆被划分成2048左右个Region。每个Region的大小在1-32MB之间,推算G1能支持的最大内存为2048*32M=64G。
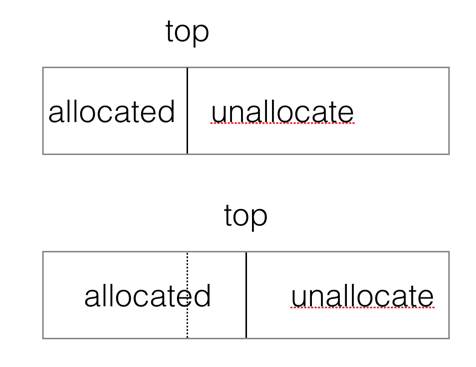
每一个分配的Region都可以分成两个部分,已分配的和未被分配的。它们之间的界限被称为top。总体上来说把一个对象分配到Region内,只需要简单增加top的值。这个做法实际上就是bump-the-pointer。过程如下:
Region是回收的最小单元,即每一次都是回收N个Region。N取决于G1回收的效率和用户设置的软实时目标。每一次回收G1选择最多垃圾的Region进行回收(Garbage First名字的起源,根据RSet排序选择外部引用最小即垃圾最多)。与此同时G1回收器会维护一个空闲Region的链表。每次回收之后的Region都会被加入到这个链表中。
每一次都只有一个Region处于被分配的状态中,被称为current region。在多线程的情况下,这会带来并发的问题。G1回收器采用和CMS一样的TLABs(Thread-Local Allocation Buffers)来加快内存回收。即为每一个线程分配一个Buffer,线程分配内存就在这个Buffer内分配。但是当线程耗尽了自己的Buffer之后,需要申请新的Buffer。这个时候依然会带来并发的问题。G1回收器采用的是CAS(Compare And Swap)操作。
1、记录top值;
2、准备分配;
3、比较记录的top值和现在的top值,如果一样,则执行分配,并且更新top的值;否则,重复1;
显然采用TLABs的技术,就会带来碎片。举例来说,当一个线程在自己的Buffer里面分配的时候,虽然Buffer里面还有剩余的空间,但是却因为分配的对象过大以至于这些空闲空间无法容纳,此时线程只能去申请新的Buffer,而原来的Buffer中的空闲空间就被浪费了。Buffer的大小和线程数量都会影响这些碎片的多寡。
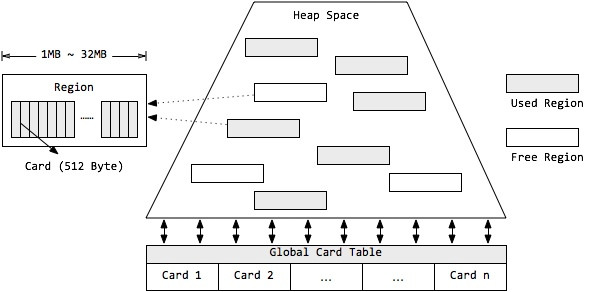
2、G1的Remember Set和Card Table
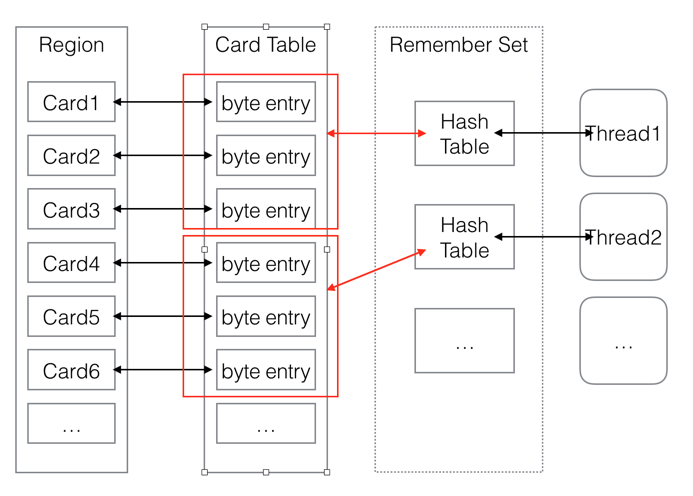
G1的heap和其它GC一样有个覆盖整个heap的card table。
Rset:G1每个Region都有一个“points-into” Remember Set,记录的是从其它region指向该region的card。
Card Table:是一个“points-out” Remember Set,记录的是从它覆盖的范围出发指向别的范围的指针。
虚拟机发现程序对Reference类型数据进行写操作时,会产生一个Write Barrier暂时中断写操作,检查Reference引用的对象是否处于不同的Region之间(在分代中例子中就是检查是否老年代中的对象引用了新生代的对象),如果是便通过CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set中。
在RS的修改上会遇到并发的问题。因为一个Region可能有多个线程在并发修改,因此它们也会并发修改RS。为了避免这样一种冲突,G1垃圾回收器进一步把RS划分成了多个哈希表(key是其它region的起始地址,value是一个集合存的是card table的index)。每一个线程都在各自的哈希表里面修改。从逻辑上来说,RS就是这些哈希表的集合。
3、Collect Set
由G1垃圾回收器选择的待回收的Region集合。G1垃圾回收器的软实时的特性就是通过CSet的选择来实现的。
young gc:CSet将只包含young的Region
mixed gc :Cset选择所有的young region和一部分的old region
full gc(担保机制):如果对象内存分配速度过快,mixed gc来不及回收导致老年代被填满,就会触发一次full gc,G1的full gc算法就是单线程执行的serial old gc,会导致异常长时间的STW,需要不断的调优尽可能的避免full gc。
4、SATB(snapshot-at-the-beginning)
SATB是最开始用于实时垃圾回收器的一种技术。G1垃圾回收器使用该技术在标记阶段记录一个存活对象的快照,然而在并发标记阶段,应用可能修改了原本的引用,比如删除了一个原本的引用。这就会导致并发标记结束之后的存活对象的快照和SATB不一致。G1是通过在并发标记阶段引入一个写屏障来解决这个问题的:每当存在引用更新的情况,G1会将修改之前的值写入一个log buffer(这个记录会过滤掉原本是空引用的情况),在最终标记(final marking phase)阶段扫描SATB,修正SATB的误差。
5、Write Barrier(写屏障)
写屏障是指在改变特定内存的值(实际上也就是写入内存)的时候额外执行的一些动作。在大多数的垃圾回收算法中,都利用到了写屏障。写屏障通常用于在运行时探测并记录回收相关指针(interesting pointer)。
G1的垃圾回收器的写屏障使用一种两级的log buffer结构:
global set of filled buffer:所有线程共享的一个全局的,存放填满了的log buffer的集合;
thread log buffer:每个线程自己的log buffer。所有的线程都会把写屏障的记录先放进去自己的log buffer中,装满了之后,就会把log buffer放到 global set of filled buffer中,而后再申请一个log buffer;
6、G1执行过程
1、initial mark: 初始标记过程,整个过程STW,标记了从GC Root可达的对象;
2、concurrent marking: 并发标记过程,整个过程gc collector线程与应用线程可以并行执行,标记出GC Root可达对象衍生出去的存活对象,并收集各个Region的存活对象信息;
3、remark: 最终标记过程,整个过程STW,标记出那些在并发标记过程中遗漏的,或者内部引用发生变化的对象;
4、clean up: 垃圾清除过程,如果发现一个Region中没有存活对象,则把该Region加入到空闲列表中;
三、G1适用场景
G1适合堆大小差不多是6GB或者更大(在普通大小的堆里表现并不惊喜),暂停时间要求在0.5秒以下的场景(G1通过每次只清理一部分而不是全部的Region的增量式清理来保证每次GC停顿时间不会过长)。
Ref:
https://www.jianshu.com/p/aef0f4765098
http://www.360doc.com/content/14/1212/21/1073512_432486652.shtml
https://blog.csdn.net/coderlius/article/details/79272773