均值漂移聚类是基于滑动窗口的算法,它试图找到数据点的密集区域。这是一个基于质心的算法,这意味着它的目标是定位每个组/类的中心点,通过将中心点的候选点更新为滑动窗口内点的均值来完成。然后,在后处理阶段对这些候选窗口进行过滤以消除近似重复,形成最终的中心点集及其相应的组。请看下面的图例。
均值漂移聚类用于单个滑动窗口
为了解释均值漂移,我们将考虑二维空间中的一组点,如上图所示。
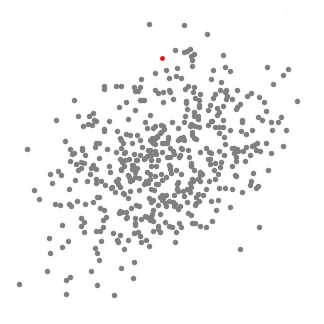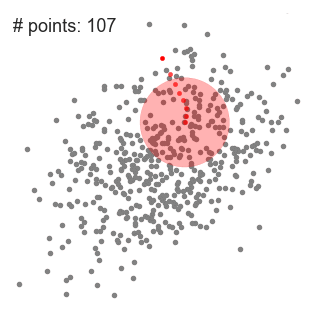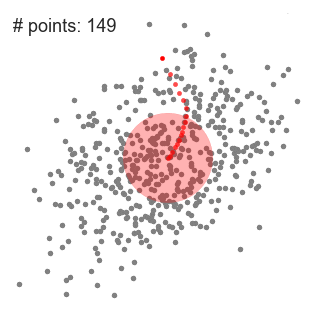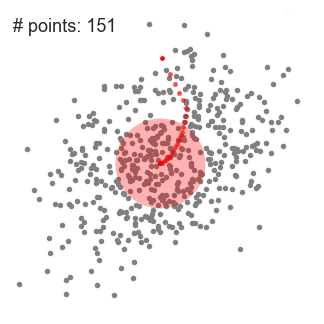
1.我们从一个以 C 点(随机选择)为中心,以半径 r 为核心的圆形滑动窗口开始。均值漂移是一种爬山算法,它包括在每一步中迭代地向更高密度区域移动,直到收敛。
2.在每次迭代中,滑动窗口通过将中心点移向窗口内点的均值(因此而得名)来移向更高密度区域。滑动窗口内的密度与其内部点的数量成正比。自然地,通过向窗口内点的均值移动,它会逐渐移向点密度更高的区域。
3.我们继续按照均值移动滑动窗口直到没有方向在核内可以容纳更多的点。请看上面的图;我们一直移动这个圆直到密度不再增加(即窗口中的点数)。
4.步骤 1 到 3 的过程是通过许多滑动窗口完成的,直到所有的点位于一个窗口内。当多个滑动窗口重叠时,保留包含最多点的窗口。然后根据数据点所在的滑动窗口进行聚类。
下面显示了所有滑动窗口从头到尾的整个过程。每个黑点代表滑动窗口的质心,每个灰点代表一个数据点。

均值漂移聚类的整个过程
与 K-means 聚类相比,这种方法不需要选择簇数量,因为均值漂移自动发现这一点。这是一个巨大的优势。聚类中心朝最大点密度聚集的事实也是非常令人满意的,因为理解和适应自然数据驱动的意义是非常直观的。它的缺点是窗口大小/半径「r」的选择很重要。
其中起始点的个数可以为所有样本、随机抽样也可以通过一定方法(粗粒度分区抽样)选择;距离的度量可以直接使用欧式距离等也可以引入核函数;找到中心后可以使用k-means或者依据之前的映射关系分配到相关的聚类中心。
思考:
1.找中心的过程可以使用faiss库进行加速,并且不适用平均值而是使用中位数可能更符合朝向密度最大方向去得过程。