这是由UC Berkerley和Stanford研究人员一起完成的Squeezenet网络结构和设计思想。SqueezeNet设计目标是在保持精度(Alexnet)的情况下简化网络的复杂度。
1、设计原则:
- 尽量选择1*1卷积核来代替3*3卷积核,因为1*1的卷积核比3*3的卷积核参数少了9倍。
- 减少3*3卷积核的输入通道(input channels),因为卷积核参数为:(number of input channels)*(number of filters)*3*3
- 延迟下采样(downsample),前面的layers可以有更大的特征图,有利于提升模型的准确度。目前下采样一般采用strides>1的卷积或者pool layer。【下采样即缩小图像,目的是使图像符合现实区域的大小,生成对应图像的缩略图。】在AlexNet中,第一层的卷积是stride=4,直接下采样了4倍。在一般的CNN中,一般卷积层、池化层都会有下采样(stride>1),甚至在前面基层网络的下采样比例会比较大,这样会导致最后几层的神经元的激活映射区域减少。为了提高精度设计下采样延迟慢一点
【前两个策略是为了减少参数,而第三个策略是为了最大化精度】
2、SqueezeNet的网络结构
SqueezeNet网络基本但愿是采用了模块化的卷积,其称为Fire module。Fire模块主要包含两层卷积操作:一是采用了1x1卷积核的squeeze层;二是混合使用1x1和3x3卷积核的expand层。Fire模块的基本结构如下图。在squeeze层卷数记为,在expand层卷积数记为
和
,分别代表了1x1和3x3卷积核的数量。为了尽量减少3x3的输入通道,这里让
。

整个SqueezeNet网络就是由File module堆积起来的,SqueezeNet的整体结构如下图,左边是标准的SqueezeNet,其最开始是一个卷积层,后面是Fire module的堆积,值得注意的是其中穿插了stride=2的maxpool层,其主要作用的是下采样(downsample),并采用延迟的策略,尽量使前面层拥有较大的feature map。中间和右边的图分别是引入了不同“短路”机制的SqueezeNet,借鉴了resNet的结构:

3、具体的实现细节
- 在Fire模块中,expand层采用了混合卷积核1x1和3x3,stride=1,对于1x1,其输出的feature map与原始一样大, 3x3则padding=1,也会得到和原始一样大小的图。
- Fire模块中所有卷积层的激活函数采用ReLU
- Fire9层厚采用了dropout=0.5
- SqueezeNet没有全连接层,而是采用了全局的avgpool(global average pool),即pool size和输入的feature map大小一致。
- 训练采用线性递减的学习速率,初始学习速率为0.04
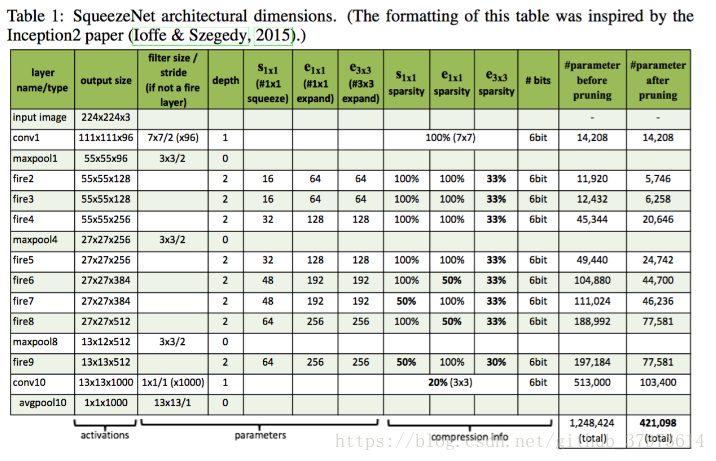
结果的对比:
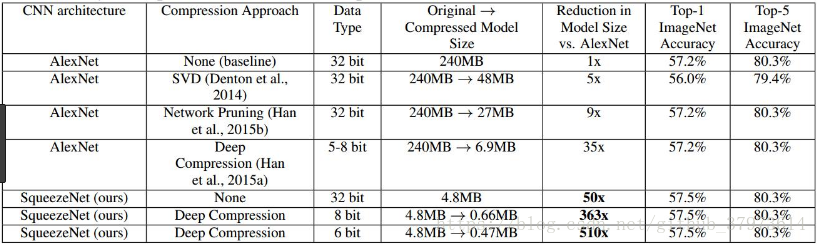
除了上面的工作,作者还探索了网络的设计空间,包括微观结构和宏观结构,微观结构包括各个卷积层的维度等设置,宏观结构比如引入ResNet的短路连接机制。
参考:https://zhuanlan.zhihu.com/p/31558773