今天早上突然接收到数据人员说mongodb节点挂了,正式服APP不能访问,我登录到主节点查看集群状态 mongodb01这台机器是我们mongo副本集的主节点
root@mongodb01:~ # mongo 172.18.30.181:37017
MongoDB shell version v3.6.7
connecting to: mongodb://172.18.30.181:37017/test
MongoDB server version: 3.6.7
rset:PRIMARY> use admin
switched to db admin
rset:PRIMARY> db.auth(“用户名”,“密码”)
1
#上面的步骤只是登录到节点并且切换成超级用户模式
rset:PRIMARY> rs.status();
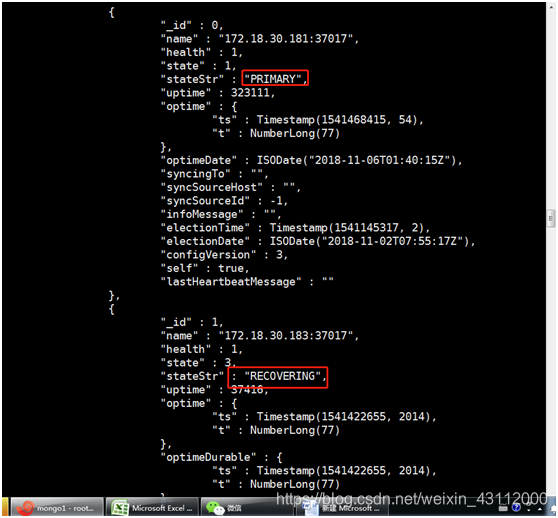
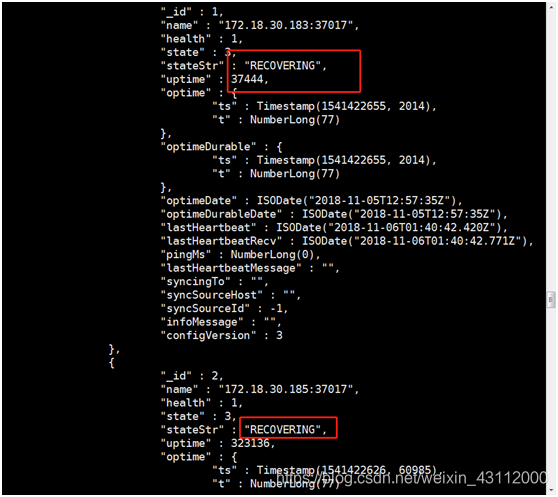
这里发现一个问题,除了主节点以为所有的状态都是RECOVERING ,我去看了一下mongodb的日志.(这个可以在vim /etc/mongod.conf配置文件找日志路径)
信息如下:
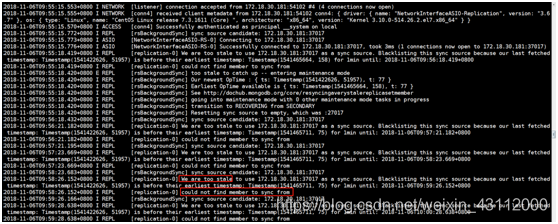
一直在报同步延迟错误,登上去一台从节点看一下复制集信息
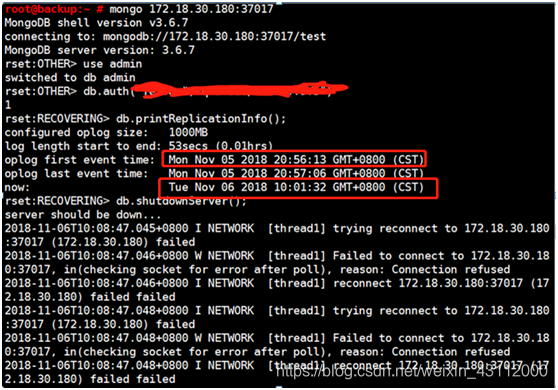
可以看到这里的mongodb的复制时间是在昨天的20:56:13左右,现在的时间已经是第二天的10:01:32了, 表示这台备库已经断档很久很久了,导致sync失败。
经过排查初步分析是由于数据量写入过大导致的,因为数据人员使用爬虫服务器往主节点写数据,从节点去同步数据的时候同步不过来,而主节点的oplog大小实在是太小,从节点还没有同步完主节点就已经更新了oplog进行下一步操作了,导致从节点跟不上主节点的速度直接断档了(主节点的硬件配置比从节点也要高出许多)所以我们需要再次人工同步,并调整一下oplog的大小
上网搜了一下资料,需要手动同步数据,mongo官网给了两种办法
1、 自动同步,最简单也是操作最少的一种办法,先把mongodb停止服务,然后把mongodb的数据目录移走,新建一个mongo的数据目录,再起服务,这样他就会自动去追赶主库的数据,缺点是恢复时间比较久,根据数据量来决定
2、 从另外一个成员拷贝数据文件, 停止备库,从primary库copy数据文件,在copy的时候,注意要把local库也复制过来,复制不能采用mongodump,仅仅只允许使用快照备份数据文件
分析了上面的2种方式,第一种方式,清空数据目录重启mongodb实例让mongodb初始化同步数据,操作简单,但是恢复时间比较长,需要花费更多时间替换数据,第二种方式从副本集合的另外一个成员拷贝数据目录后重启mongodb实例,这个恢复过程速度快但是需要比较多的手工操作步骤,为了方便和简单,我这里用第一种方式
一、把数据重新同步
1、再此之前先把mongodb的服务给停了,进去mongo里use admin库再输入db.shutdownServer()
2、然后进去mongodb的数据存放目录
root@backup:~ # cd /data

我的mongo的数据放在这个文件夹里,现在把原来的数据改个名字 新建一个mongo的数据文件夹,要知道自己的数据文件夹放哪里可以看/etc/mongod.conf文件
root@backup:/data # mv mongo mongo.bak #给旧的mongo数据文件进行改名
root@backup:/data # mkdir mongo #创建新的mongo文件夹
root@backup:~ # mongod -f /etc/mongod.conf #启动mongodb

启动成功 没有报错
查看一下新文件夹, mongodb副本集已经在向主节点同步数据了

登陆一下mongodb,切换超级用户(没有设置的不用做这个操作,我的mongodb做了设置不切换超级用户无法执行命令)
rset:STARTUP2> rs.status(); #查看一下集群信息
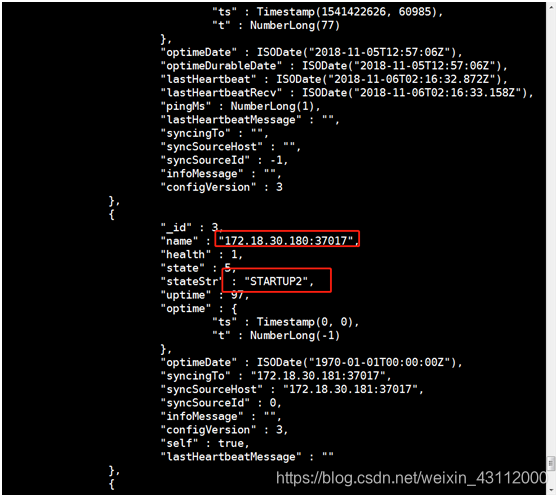
发现刚才重启的这台状态已经变成startup2了,接下来的就是等待了
等了大概一天同步数据,登上去看看
rset:PRIMARY> rs.status()
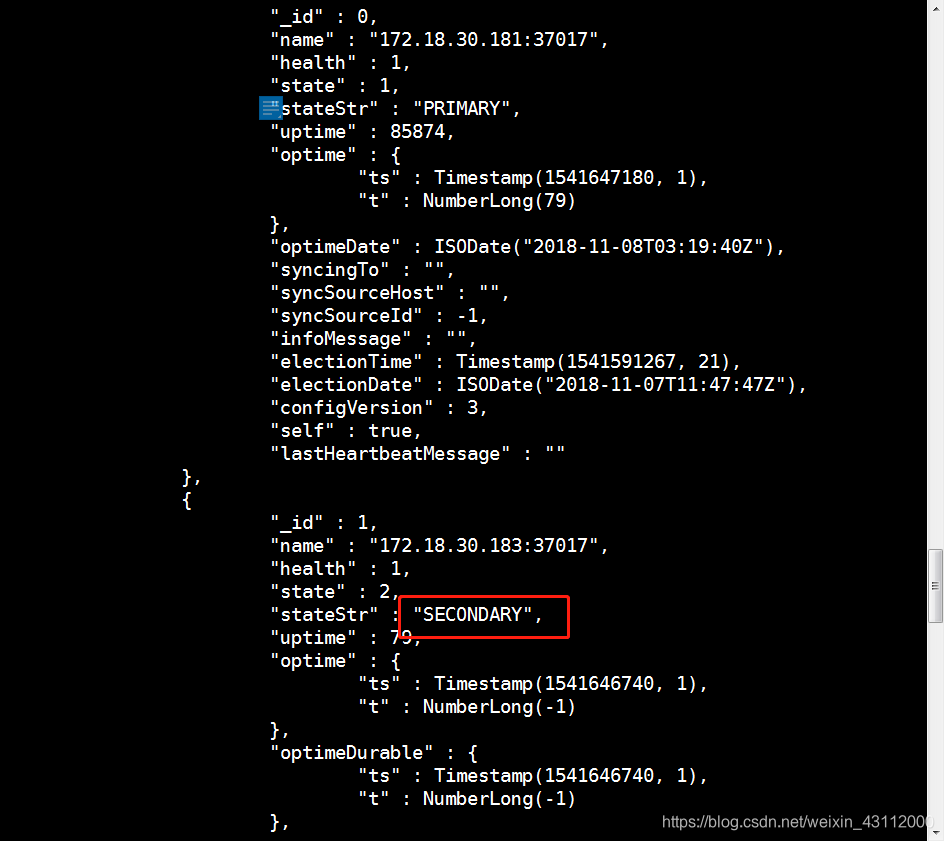
发现这个节点的数据已经恢复了,并加入了集群里,其他的副本集如果也是RECOVERING也要做相同的操作,总的来说就是停止服务,然后移走老的数据文件夹,新建新的文件夹,再起服务等他自己同步
二、把oplog调整大一点,防止以后又出现这种情况
参考至mongodb官方文档
https://docs.mongodb.com/manual/tutorial/change-oplog-size/
1、进入mongodb
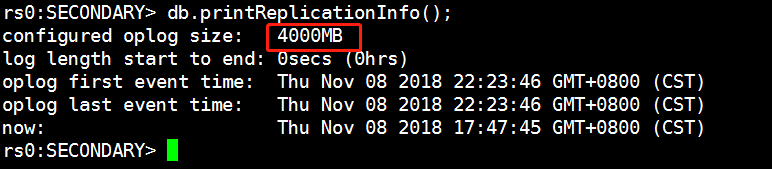
rs0:SECONDARY> db.printReplicationInfo(); #查看当前副本集oplog状态,可以看到现在是2000MB的
configured oplog size: 2000MB
log length start to end: 0secs (0hrs)
oplog first event time: Thu Nov 08 2018 22:23:46 GMT+0800 (CST)
oplog last event time: Thu Nov 08 2018 22:23:46 GMT+0800 (CST)
now: Thu Nov 08 2018 17:45:42 GMT+0800 (CST)
rs0:SECONDARY> db.adminCommand({replSetResizeOplog: 1, size: 4000}) #调整oplog大小为4000MB
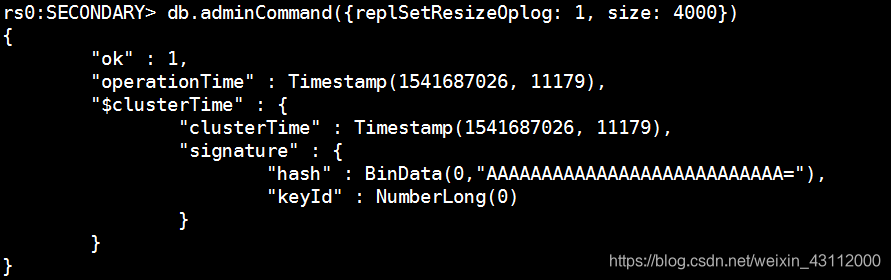
rs0:SECONDARY> db.printReplicationInfo(); #再查看一下,变成4000MB了
2、测试一下同步情况正不正常
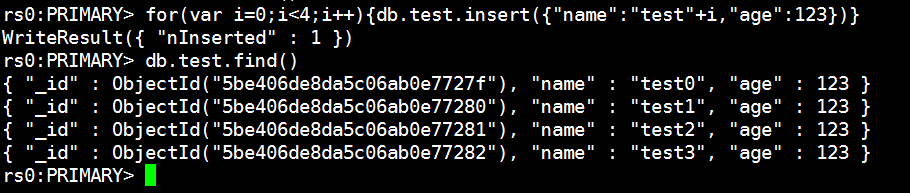
rs0:PRIMARY> for(var i=0;i<4;i++){db.test.insert({“name”:“test”+i,“age”:123})} #在主节点插入4条数据测试一下
WriteResult({ “nInserted” : 1 })
rs0:PRIMARY> db.test.find() #查看数据是否插入
{ “_id” : ObjectId(“5be406de8da5c06ab0e7727f”), “name” : “test0”, “age” : 123 }
{ “_id” : ObjectId(“5be406de8da5c06ab0e77280”), “name” : “test1”, “age” : 123 }
{ “_id” : ObjectId(“5be406de8da5c06ab0e77281”), “name” : “test2”, “age” : 123 }
{ “_id” : ObjectId(“5be406de8da5c06ab0e77282”), “name” : “test3”, “age” : 123 }
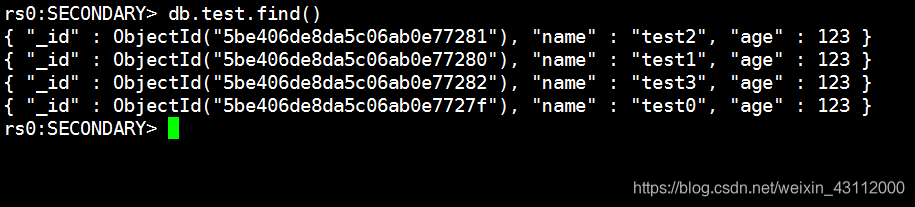
去从节点看一下,数据确实插入了
rs0:SECONDARY> db.test.find()
{ “_id” : ObjectId(“5be406de8da5c06ab0e77281”), “name” : “test2”, “age” : 123 }
{ “_id” : ObjectId(“5be406de8da5c06ab0e77280”), “name” : “test1”, “age” : 123 }
{ “_id” : ObjectId(“5be406de8da5c06ab0e77282”), “name” : “test3”, “age” : 123 }
{ “_id” : ObjectId(“5be406de8da5c06ab0e7727f”), “name” : “test0”, “age” : 123 }