版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/chishuideyu/article/details/80748506
作者在这篇文章中总共做了三件事情:
1. 首先,作者介绍了一种从图像中自动标注轨迹的方法,用其生成了一个大型训练数据集。
2. 接着,作者使用CNN估计深度和平面法向量,生成了一个粗糙的3D模型。
3. 最后,在另一个CNN模型中,利用生成的3D模型估计避障路径。
1. 建立训练集
作者使用包含室内场景以及深度图的NYUv2数据集,如果直接从如此大的数据中获取3D轨迹是一个高难度的高维度回归问题,这非常困难。所以作者考虑将轨迹简化为5类,左方,左前方,前方,右前方,右方。对于每张图片,label就是五个轨迹中的最佳轨迹。这里的轨迹使用最大色散理论方法生成,每条路径长2.5m。
那么作者是如何从深度图中计算前进方向的呢?
首先作者将深度图构建成3维空间,然后定义路径的cost function(引用自其他文章。)
其中, 是障碍物cost function,用于惩罚距离障碍物太近。 用于测量路径的平滑度并惩罚高偏差。其中 , 是障碍物cost函数可以达到的最大距离,在NYU数据集中设为3.5m。 是从距离图上得到的距离障碍物的距离。
这两个公式都由《Chomp: Covariant hamiltonian optimization for motion planning》定义,这部分作者提供了代码,接下来两部分,作者都未提供代码。
2. 估计深度和平面法向量
作者使用Eigen的CNN模型来估计深度和平面法向量。该CNN模型基于全图估计出一个粗略的全局输出,接着用精细尺度的局部网络来进行细化。
Depth Loss 和 Normal Loss 如下:
其中 是估计深度和真实深度之间的log差距, 是 的梯度值, 和 分别是真实的和估计的法向量。
这两个Loss function 由《Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture》定义。
3. 估计轨迹
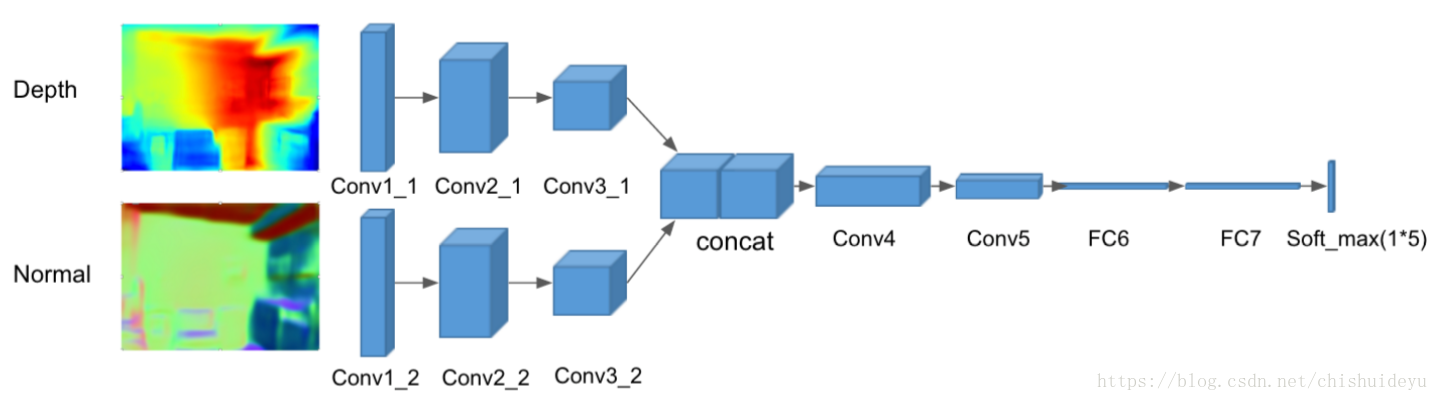
作者自己设计了一个CNN网络,该CNN网络从AlexNet改版而来,有两个输入,一个是估计的平面法向量,一个是估计的深度。为了保持对称性,作者将深度图变成3通道的,每个通道一样。然后深度和法向量图像分别学习卷积核,并在第四层汇总,所以最终的预测结果将会融合两种信息。在训练时,最小化标准分类交叉熵损失:
其中, 是softmax类别概率, 是CNN的卷积输出。这一步和《Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture》所做的也很像