版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/m0_37490039/article/details/79474946
本文主要介绍如何实现一个简单的语音识别系统,识别的是英文0-9十个英文单词
首先介绍下实现的思路:
1.对语音wav文件进行mfcc特征提取(这一步由librosa完成,细节可以不care)
2.对得到的数据进行归一化
3.使用CNN神经网络对归一化的数据进行分类
源代码cnn-asr
特征提取
实现代码
def read_files(files):
labels = []
features = []
for ans, files in files.items():
for file in files:
wave, sr = librosa.load(file, mono=True)
label = dense_to_one_hot(ans, 10)
# label = [float(value) for value in label]
labels.append(label)
mfcc = librosa.feature.mfcc(wave, sr)
l = len(mfcc)
# print(np.array(mfcc).shape)
mfcc = np.pad(mfcc, ((0, 0), (0, 80 - len(mfcc[0]))), mode='constant', constant_values=0)
features.append(np.array(mfcc))
# print('reading '+file)
return np.array(features), np.array(labels)函数输入的是包含wav文件名的list,每个文件是一个单词的发音,每个单词发音特征提取后是一个20*80的数据矩阵。可以理解乘每个单词发音包含20个mfcc,每个mfcc是一个长度为80的向量。
数据归一化
实现代码
def mean_normalize(features):
std_value = features.std()
mean_value = features.mean()
return (features - mean_value) / std_valueCNN分类
cnn原理可参考 CNN(卷积神经网络)详解
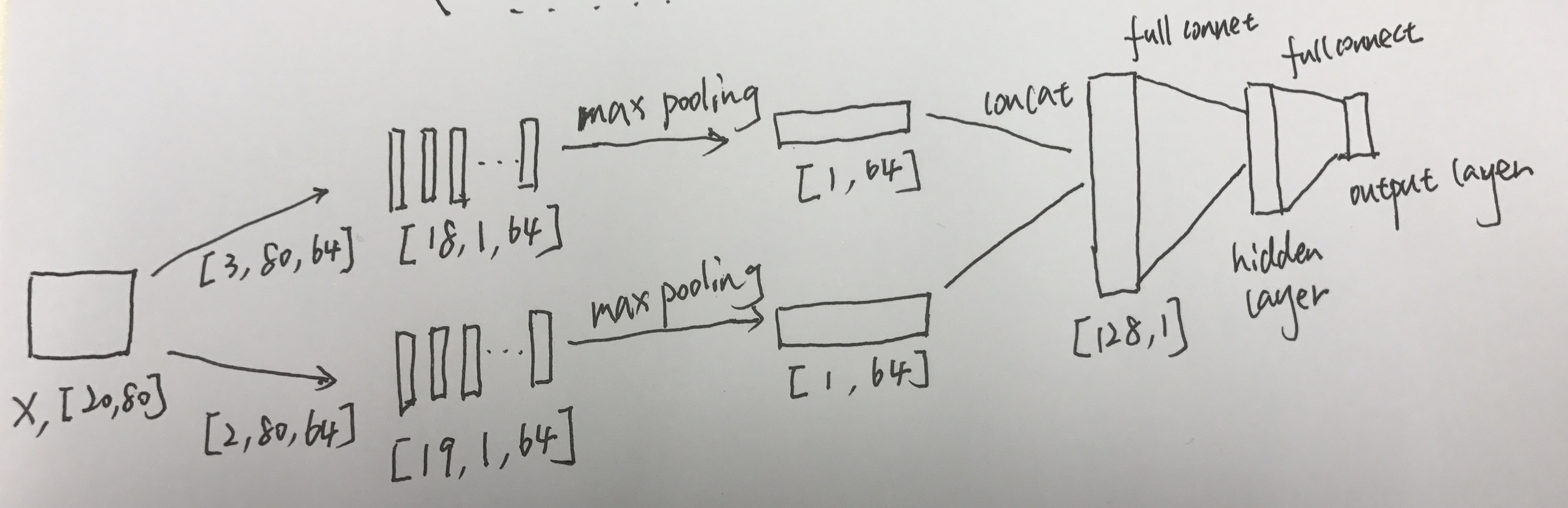
参照上图,我们CNN的输入是shape为[20,80]数据矩阵,分别经过两种size的卷积核(filter):[2,80]和[3,80]。两种卷积核的个数都是是64个,分别得到64个长度为18的向量和64个长度为19的向量。然后取每个向量的最大值,取最大值的原因是保留每个卷积核捕获到的最大特征。把这些最大特征拼凑在一块作为x经过卷积后的特征向量(size=128),后面接全连接层以及输出层。
实现代码
class ASRCNN(object):
def __init__(self, config, width, height, num_classes): # 20,80
self.config = config
self.input_x = tf.placeholder(tf.float32, [None, width, height], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
# input_x = tf.reshape(self.input_x, [-1, height, width])
input_x = tf.transpose(self.input_x, [0, 2, 1])
pooled_outputs = []
for i, filter_size in enumerate(self.config.filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
print("conv-maxpool-%s" % filter_size)
conv = tf.layers.conv1d(input_x, self.config.num_filters, filter_size, activation=tf.nn.relu)
pooled = tf.reduce_max(conv, reduction_indices=[1])
pooled_outputs.append(pooled)
num_filters_total = self.config.num_filters * len(self.config.filter_sizes) # 32*3
pooled_reshape = tf.reshape(tf.concat(pooled_outputs, 1), [-1, num_filters_total])
#pooled_flat = tf.nn.dropout(pooled_reshape, self.keep_prob)
fc = tf.layers.dense(pooled_reshape, self.config.hidden_dim, activation=tf.nn.relu, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
#fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, num_classes, name='fc2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))我们也可以引入更多size的卷积核如[5,20],事实上,更多种类的卷积核可以捕获更多的特征,我们卷积得到的特征向量维度就等于所有卷积核的个数。