大家都知道索引的重要性,基本用法在上章《最全面的mysql索引知识大盘点》已分享过,本章主要是探索索引的底层实现原理。当然了,我们还是以mysql为基准进行探讨。
首先了解索引之前,我们先要了解个事情,innodb和myisam的区别?当然也是浅谈下,
|
|
InnoDB |
MyISAM |
| 简介 |
由Innobase Oy公司开发。 支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB,特别是针对多个并发和QPS较高的情况。 |
默认表类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法。不是事务安全的,而且不支持外键,如果执行大量的select,insert MyISAM比较适合。 |
| 使用场景 |
在线事务处理(OLTP)型应用 |
在线分析处理(OLAP) 型应用 |
| 锁差异 |
Innodb支持事务和行级锁,是innodb的最大特色。 事务的ACID属性,并发事务带来的几个问题:更新丢失,脏读,不可重复读,幻读。 事务隔离级别:未提交读(Read uncommitted),已提交读(Read committed),可重复读(Repeatable read),可序列化(Serializable) |
myisam只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。也可以通过lock table命令来锁表,这样操作主要是可以模仿事务,但是消耗非常大,一般只在实验演示中使用。 |
| 数据库文件差异 |
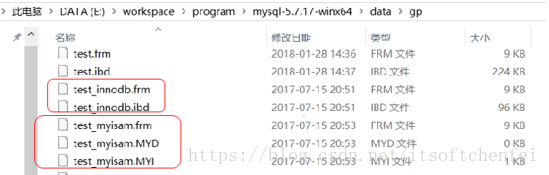
innodb属于索引组织表 innodb有两种存储方式,共享表空间存储和多表空间存储 两种存储方式的表结构和myisam一样,以表名开头,扩展名是.frm。 如果使用共享表空间,那么所有表的数据文件和索引文件都保存在一个表空间里,一个表空间可以有多个文件,通过innodb_data_file_path和innodb_data_home_dir参数设置共享表空间的位置和名字,一般共享表空间的名字叫ibdata1-n。 如果使用多表空间,那么每个表都有一个表空间文件用于存储每个表的数据和索引,文件名以表名开头,以.ibd为扩展名。 |
myisam属于堆表 myisam在磁盘存储上有三个文件,每个文件名以表名开头,扩展名指出文件类型。 .frm 用于存储表的定义 .MYD 用于存放数据 .MYI 用于存放表索引 myisam表还支持三种不同的存储格式: 静态表(默认,但是注意数据末尾不能有空格,会被去掉) 动态表 压缩表 |
| 索引差异 |
1、关于自动增长 myisam引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。 innodb引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。 2、关于主键 myisam允许没有任何索引和主键的表存在, myisam的索引都是保存行的地址。 innodb引擎如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见) innodb的数据是主索引的一部分,附加索引保存的是主索引的值。 3、关于count()函数 myisam保存有表的总行数,如果select count(*) from table;会直接取出出该值 innodb没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre 条件后,myisam和innodb处理的方式都一样。 4、全文索引 myisam支持 FULLTEXT类型的全文索引 innodb不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。(sphinx 是一个开源软件,提供多种语言的API接口,可以优化mysql的各种查询) 5、delete from table 使用这条命令时,innodb不会从新建立表,而是一条一条的删除数据,在innodb上如果要清空保存有大量数据的表,最 好不要使用这个命令。(推荐使用truncate table,不过需要用户有drop此表的权限) 6、索引保存位置 myisam的索引以表名+.MYI文件分别保存。 innodb的索引和数据一起保存在表空间里 |
|
1.物理磁盘知识
首先dbms本身就是一个文件管理系统,只是它的实现方式确实比较复杂,但本质上是要通过访问磁盘才能完成数据的存储与检索。本着刨根问底的精神,就要分析文件是存储及检索的。
1.1基本概念
| 盘片 |
|
| 盘面 |
|
| 磁头 |
|
| 磁道 |
|
| 柱面 |
|
| 扇区 |
标识符就是扇区头标,包括组成扇区三维地址的三个数字:盘面号,柱面号,扇区号(块号)。 数据段可分为数据和保护数据的纠错码(ECC)。 |
| 磁盘块/簇 |
|
| Page |
|

磁盘容量计算
存储容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
某磁盘是一个 3个圆盘6个磁头,7个柱面(每个盘片7个磁道) 的磁盘,每条磁道有12个扇区,所以此磁盘的容量为:6 * 7 * 12 * 512 = 258048
1.2硬盘中的数据
信息存储在硬盘里,硬盘是由很多的盘片组成,通过盘片表面的磁性物质来存储数据。
把盘片放在显微镜下放大,可以看到盘片表面是凹凸不平的,凸起的地方被磁化,代表数字 1,凹的地方没有被磁化,代表数字 0,因此硬盘可以通过二进制的形式来存储表示文字、图片等的信息。
所有的盘片都固定在一个旋转轴上,这个轴即盘片主轴,所有的盘片之间是绝对平行的,在每个盘片的盘面上都有一个磁头,磁头与盘片之间的距离比头发丝的直径还小。
所有的磁头连在一个磁头控制器上,由磁头控制器负责各个磁头的运动,磁头可沿盘片的半径方向移动,实际上是斜切运动,每个磁头同一时刻必须是同轴的,即从正上方往下看,所有磁头任何时候都是重叠的。
由于技术的发展,目前已经有多磁头独立技术了,在此不考虑此种情况。
盘片以每分钟数千转到上万转的速度在高速运转,这样磁头就能对盘片上的指定位置进行数据的读写操作。
由于硬盘是高精密设备,尘埃是其大敌,所以必须完全密封。
1.3磁盘的读写原理
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下的所有扇区,然后是同一柱面的下一个磁头……
一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
系统也以相同的顺序读出数据,读出数据时通过告诉磁盘控制器要读出扇区所在柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。
注:操作系统读取同理,只是颗粒的更大的块操作
1.5磁盘的读取响应时间
当需要从磁盘读取数据的时候,系统会将数据的逻辑地址传递个磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫做寻道。
然后目标扇区旋转到磁头下,即磁盘旋转将目标扇区旋转到磁头下。
寻道(时间):磁头移动定位到指定磁道所需要的时间,寻道时间越短,I/O操作越快,目前磁盘的平均寻道时间一般在3-15ms,一般都在10ms左右。
旋转延迟(时间):盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间,旋转延迟取决于磁盘转速。普通硬盘一般都是7200rpm,慢的5400rpm。
数据传输(时间):数据在磁盘与内存之间的实际传输所需要的时间。
- 确定磁盘地址(柱面号,磁头号,扇区号),内存地址(源/目):
- 为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点:
- 即一次访盘请求(读 / 写)完成过程由三个动作组成:
注:读写一次磁盘信息所需的时间中软件应着重考虑减少寻道时间和延迟时间。
1.6 I/O 的预读原理
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费的时间,磁盘的存取速度往往是主存的几百分之一。
因此,计算机科学中著名的局部性原理:
-
当一个数据被用到时,其附近的数据一般来说也会被马上使用。
-
程序运行期间所需要的数据通常比较集中。
-
由于磁盘顺序读取的效率很高(不需要寻道时间,只需要很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高 I/O 效率。
预读的长度一般为页(在许多操作系统中,页的大小通常为 4k)的整数倍。操作系统以内存页为单位管理内存,内存页的大小对系统性能有影响。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信息,磁盘会找到数据的起始位置并向后连续读取一页或几页的数据载入内存中,然后异常返回,程序继续运行。
2.推理并拆解普通查询语句
select * from talbe_name where id=1
step1:找到数据文件
step2:读取数据文件
step3:读取id=1的数据
理论上是这样的,
索引是一种用来实现高效获取数据的数据结构,建索引的目的是为了查找的优化,特别是当数据很庞大的时候,非常重要。一般的查找算法有顺序查找、折半查找、快速查找等,但是每种查找算法只能应用于特定的数据结构,例如顺序查找依赖于顺序结构,折半查找通过二叉查找树或红黑树实现二分搜索。因此在数据之外,数据库系统还维护着满足特定查找算法的数据结构,它以某种方式引用数据。
3.为什么要用B+Tree实现
4.Mysql索引是如何实现的
5.待续