目录
“ 今晚我应该看什么电影?”
当你下班回家时,你是否曾经至少回答过一次这个问题?至于我 - 是的,不止一次。从Netflix到Hulu,鉴于对现代消费者个性化内容的巨大需求,构建强大的电影推荐系统的需求极为重要。
推荐系统的一个例子如下:
- 用户A观看权力的游戏和破坏。
- 用户B上进行的搜寻权力的游戏,然后系统提示绝命毒从收集的有关用户的数据A.
推荐系统不仅用于电影,还用于亚马逊(书籍,项目),潘多拉/ Spotify(音乐),谷歌(新闻,搜索),YouTube(视频)等多种其他产品和服务。
Netflix建议
在这篇文章中,我将向您展示如何实现4种不同的电影推荐方法,并评估它们以确定哪种方法具有最佳性能。
MovieLens数据集
我正在使用的数据集是MovieLens,它是互联网上用于构建推荐系统的最常见数据集之一。我正在使用的数据集版本(1M)包含1,000,209个匿名评级,大约3,900部电影是由2000年加入MovieLens的6,040名MovieLens用户制作的。
在处理数据并进行一些探索性分析之后,以下是此数据集最有趣的功能:
这是电影片名的文字云可视化:
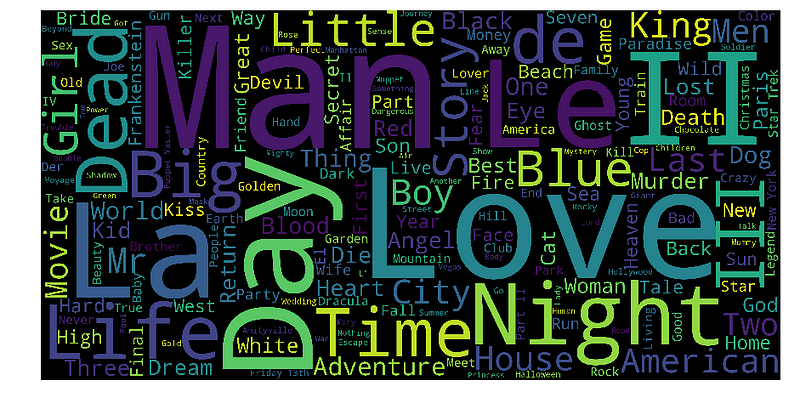
美丽,不是吗?我可以认识到,在这个数据集中有很多电影特许经营,正如II和III这样的词语所证明......除此之外,日,爱,生命,时间,夜晚,人,死,美国都是最常发生的话。
以下是用户评分的分布:
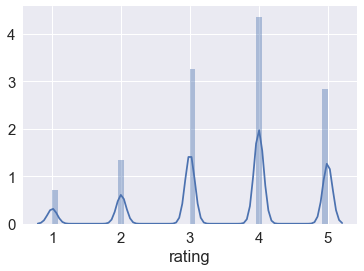
MovieLens评级
看起来用户的收视率非常慷慨。平均评分为3.58,评分为5.一半的电影评分为4和5.我个人认为5级评级技能不是一个好的指标,因为人们可能有不同的评级风格(即A人可以对于普通电影,总是使用4,而对于他们最喜欢的电影,人B只给出4。每位用户至少评了20部电影,所以我怀疑这部电影的质量可能只是因为电影质量的差异造成的。
这是电影类型的另一个词云:
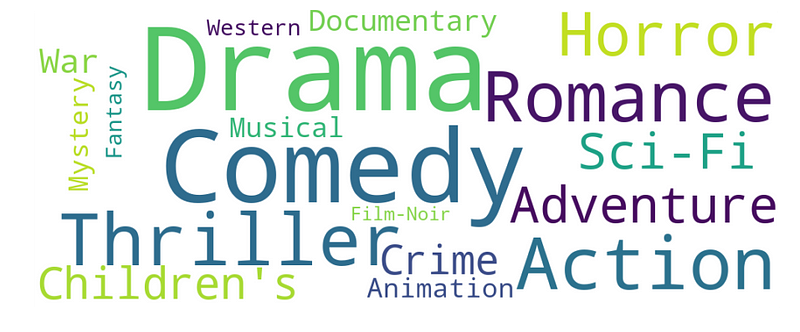
在这方面排名前五的类型是:戏剧,喜剧,动作,惊悚和浪漫。
现在让我们继续探讨可以使用的4种推荐系统。在这里,他们按照各自的呈现顺序:
- 基于内容的过滤
- 基于记忆的协同过滤
- 基于模型的协同过滤
- 深度学习/神经网络
1 - 基于内容
基于内容的推荐器依赖于推荐项目的相似性。基本的想法是,如果你喜欢一个项目,那么你也会喜欢一个“相似”的项目。当通常很容易确定每个项目的上下文/属性时,它通常很有效。
基于内容的推荐器与用户提供的数据一起工作,或者对MovieLens数据集进行明确的电影评级。基于该数据,生成用户简档,然后将其用于向用户提出建议。当用户提供更多输入或对建议采取行动时,引擎变得越来越准确。
数学
的概念术语频率(TF)和逆文档频率(IDF)在信息检索系统中使用,并且还基于内容过滤机制(诸如基于内容的推荐)。它们用于确定文档/文章/新闻项目/电影等的相对重要性。
TF只是文档中单词的频率。IDF是整个文档集中文档频率的倒数。使用TF-IDF主要是因为两个原因:假设我们在Google上搜索“ 最新欧洲Socccer游戏的结果 ”。可以肯定的是“ 中 ”会更频繁地出现比“ 足球比赛 ”,但相对重要性足球比赛比的视图搜索查询点高。在这种情况下,TF-IDF加权否定了高频词在确定项目(文档)的重要性方面的影响。
以下是计算TF-IDF得分的公式:
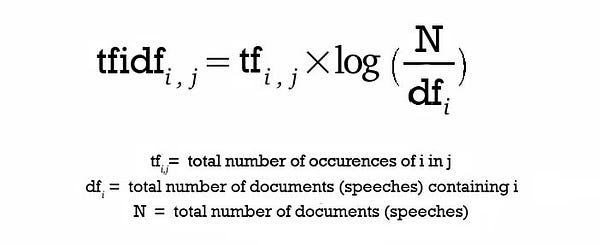
TF-IDF方程
在计算TF-IDF分数后,我们如何确定哪些项目彼此更接近,更接近用户档案?这是使用矢量空间模型完成的,该模型根据矢量之间的角度计算接近度。在该模型中,每个项目作为其属性(也是向量)的向量存储在n维空间中,并且计算向量之间的角度以确定向量之间的相似性。接下来,还基于他对项目的先前属性的动作来创建用户简档向量,并且还以类似的方式确定项目与用户之间的相似性。
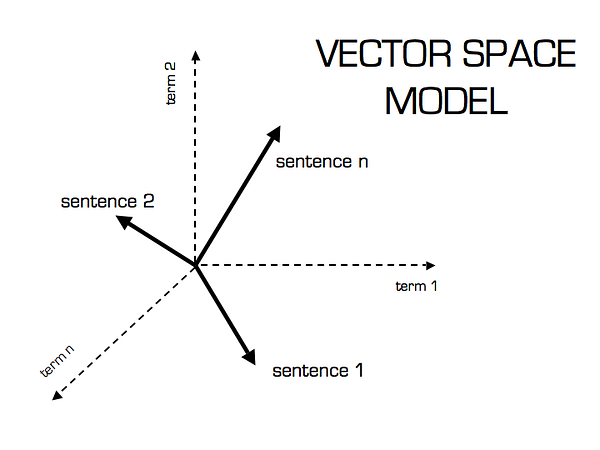
矢量空间模型
句子2更有可能使用术语2而不是使用术语1.反之亦然。句子1.计算此相对度量的方法是通过取句子和术语之间的角度的余弦来计算的。使用余弦的最终原因是余弦的值将随着角度值的减小而增加,其中角度值表示更多的相似性。向量进行长度归一化,之后它们变为长度为1的向量,然后余弦计算就是向量的和积。
代码
考虑到所有这些数学,我将构建一个基于内容的推荐引擎,根据电影类型计算电影之间的相似性。它将根据其类型推荐与特定电影最相似的电影。
我没有定量指标来判断机器的性能,因此必须定性地进行。为了做到这一点,我将使用scikit-learn中的TfidfVectorizer函数,它将文本转换为可用作估算器输入的特征向量。
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer(analyzer='word',ngram_range=(1, 2),min_df=0, stop_words='english')
tfidf_matrix = tf.fit_transform(movies['genres'])我将使用余弦相似度来计算表示两部电影之间相似性的数字量。由于我使用过TF-IDF矢量图,计算点积将直接给出余弦相似度得分。因此,我将使用sklearn的linear_kernel而不是cosine_similarities,因为它更快。
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)我现在有一个成对余弦相似度矩阵,用于数据集中的所有电影。下一步是编写一个函数,根据余弦相似度得分返回20个最相似的电影。
# Build a 1-dimensional array with movie titles
titles = movies['title']
indices = pd.Series(movies.index, index=movies['title'])
# Function that get movie recommendations based on the cosine similarity score of movie genres
def genre_recommendations(title):
idx = indices[title]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:21]
movie_indices = [i[0] for i in sim_scores]
return titles.iloc[movie_indices]建议
让我们尝试获得几部电影的最佳推荐,看看这些推荐有多好。
genre_recommendations('Good Will Hunting (1997)').head(20)

genre_recommendations('Toy Story (1995)').head(20)
genre_recommendations('Saving Private Ryan (1998)').head(20)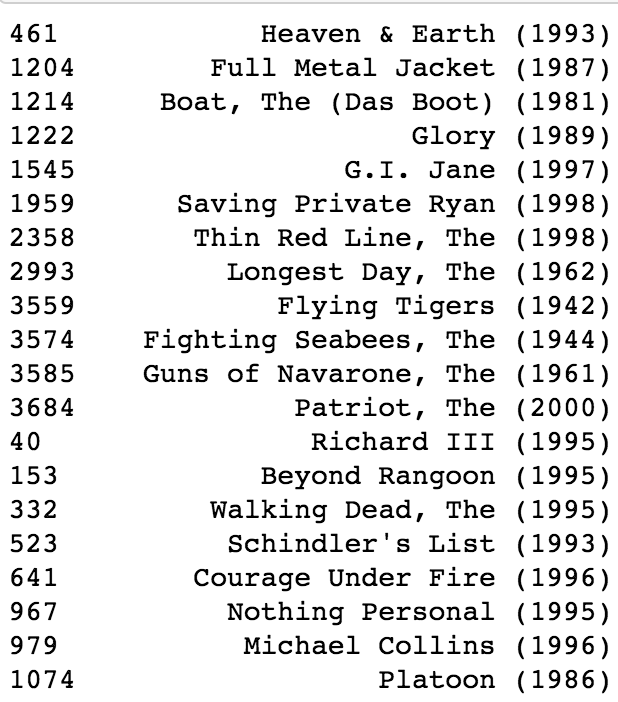
正如你所看到的,我对Good Will Hunting(戏剧),玩具总动员(动画,儿童,喜剧)和拯救私人瑞恩(动作,惊悚,战争)的推荐列表相当不错。
总的来说,以下是使用基于内容的推荐的优点:
- 不需要其他用户的数据,因此没有冷启动或稀疏性问题。
- 可以向具有独特品味的用户推荐。
- 可以推荐新的和不受欢迎的项目。
- 可以通过列出导致推荐项目的内容功能(在本例中为电影类型)来提供对推荐项目的说明
但是,使用这种方法有一些缺点:
- 找到合适的功能很难。
- 不推荐用户内容配置文件之外的项目。
- 无法利用其他用户的质量判断。
2 - 协同过滤
Collaborative Filtering Recommender完全基于过去的行为,而不是基于上下文。更具体地,它基于两个用户的偏好,品味和选择的相似性。它分析了一个用户的口味与另一个用户的口味有多相似,并在此基础上提出建议。
例如,如果用户A喜欢电影1,2,3,而用户B喜欢电影2,3,4,则他们有相似的兴趣,A应该喜欢电影4而B应该喜欢电影1.这使得它成为最常见的电影之一。使用算法,因为它不依赖于任何其他信息。
通常,协同过滤是推荐引擎的主力。该算法具有非常有趣的特性,能够自己进行特征学习,这意味着它可以开始自己学习使用哪些特征。
数学
有两种主要类型的基于内存的协同过滤算法:
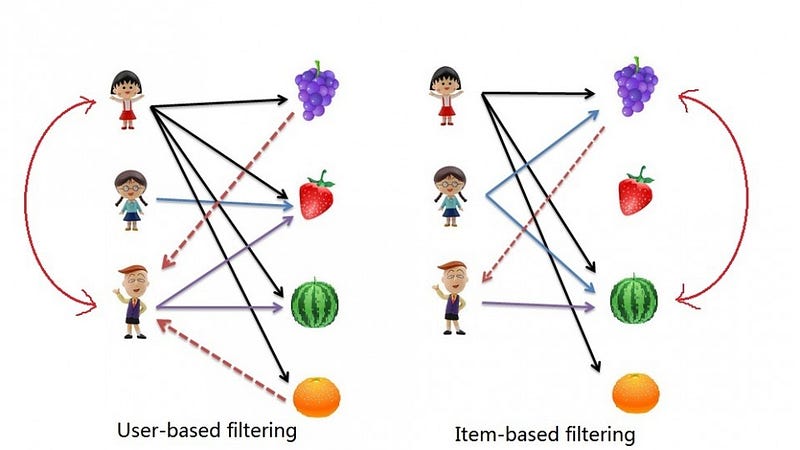
- 用户 - 用户协作过滤:在这里,我们找到基于相似性的相似用户,并推荐过去第一个用户看起来相似的电影。该算法非常有效,但需要大量的时间和资源。它需要计算每个需要时间的用户对信息。因此,对于大型基础平台,如果没有非常强大的并行化系统,这种算法很难实现。
- Item-Item Collaborative Filtering:它与之前的算法非常相似,但我们尝试找到类似电影的外观,而不是找到用户的外观。一旦我们拥有电影外观相似的矩阵,我们就可以轻松地向那些对数据集中的任何电影进行评级的用户推荐相同的电影。与用户 - 用户协同过滤相比,该算法的资源消耗要少得多。因此,对于新用户,该算法比用户 - 用户协作花费的时间少得多,因为我们不需要用户之间的所有相似性得分。并且对于固定数量的电影,电影电影外观相似的矩阵随着时间的推移而固定。
在任一情景中,我们构建相似度矩阵。对于用户 - 用户协同过滤,用户相似性矩阵将包括一些距离度量,其测量任何两对用户之间的相似性。同样,项目相似性矩阵将测量任何两对项目之间的相似性。
通常在协同过滤中使用3个距离相似性度量标准:
- Jaccard相似度:相似性基于评级项目A和B的用户数量除以评级为A或B的用户数量。通常用于我们没有数字评级但只是布尔值的用户数量就像正在购买的产品或点击添加一样。
- 余弦相似度 :(如在基于内容的系统中)相似性是A和B的项矢量的2个矢量之间的角度的余弦。矢量越近,角度越小,余弦越大。
- Pearson相似性:相似性是两个向量之间的Pearson系数。出于多样性的目的,我将在此实现中使用Pearson Similarity。
代码
由于笔记本电脑的计算能力有限,我将仅使用一部分评级来构建推荐系统。特别是,我将从1M评级中随机抽取20,000个评级(2%)。
我使用scikit-learn库将数据集拆分为测试和培训。Cross_validation.train_test_split根据测试示例的百分比将数据混洗并拆分为两个数据集,此处为0.2。
from sklearn import cross_validation as cv
train_data, test_data = cv.train_test_split(small_data, test_size=0.2)现在我需要创建一个用户项矩阵。由于我已将数据拆分为测试和培训,因此我需要创建两个矩阵。训练矩阵包含80%的评级,测试矩阵包含20%的评级。
# Create two user-item matrices for training and testing data
train_data_matrix = train_data.as_matrix(columns = ['user_id', 'movie_id', 'rating'])
test_data_matrix = test_data.as_matrix(columns = ['user_id', 'movie_id', 'rating'])现在我用的是pairwise_distances功能从sklearn计算Pearson相关系数。该方法提供了一种将距离矩阵作为输入的安全方法,同时保留了与采用矢量数组的许多其他算法的兼容性。
from sklearn.metrics.pairwise import pairwise_distances
# User Similarity Matrix
user_correlation = 1 - pairwise_distances(train_data, metric='correlation')
user_correlation[np.isnan(user_correlation)] = 0
# Item Similarity Matrix
item_correlation = 1 - pairwise_distances(train_data_matrix.T, metric='correlation')
item_correlation[np.isnan(item_correlation)] = 0有了相似度矩阵,我现在可以预测未包含在数据中的评级。使用这些预测,我可以将它们与测试数据进行比较,以尝试验证我们的推荐模型的质量。
# Function to predict ratings
def predict(ratings, similarity, type='user'):
if type == 'user':
mean_user_rating = ratings.mean(axis=1)
# Use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings - mean_user_rating[:, np.newaxis])
pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T
elif type == 'item':
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
return pred评价
有许多评估指标,但用于评估预测评级准确性的最常用指标之一是均方根误差(RMSE)。我将使用sklearn中的mean_square_error(MSE)函数,其中RMSE只是MSE的平方根。我将使用scikit-learn的均方误差函数作为我的验证指标。比较基于用户和项目的协同过滤,看起来基于用户的协同过滤提供了更好的结果。
from sklearn.metrics import mean_squared_error
from math import sqrt
# Function to calculate RMSE
def rmse(pred, actual):
# Ignore nonzero terms.
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return sqrt(mean_squared_error(pred, actual))
# Predict ratings on the training data with both similarity score
user_prediction = predict(train_data_matrix, user_correlation, type='user')
item_prediction = predict(train_data_matrix, item_correlation, type='item')
# RMSE on the train data
print('User-based CF RMSE: ' + str(rmse(user_prediction, train_data_matrix)))
print('Item-based CF RMSE: ' + str(rmse(item_prediction, train_data_matrix)))
## Output
User-based CF RMSE: 699.9584792778463
Item-based CF RMSE: 114.97271725933925模型训练的RMSE是衡量模型解释信号和噪声的程度的度量。我注意到我的RMSE非常大。我想我可能会过度拟合训练数据。
总的来说,基于内存的协同过滤易于实现并产生合理的预测质量。但是,这种方法有一些缺点:
- 它没有解决众所周知的冷启动问题,即新用户或新项目进入系统时。
- 它无法处理稀疏数据,这意味着很难找到评价相同项目的用户。
- 当新用户或没有任何评级的项目进入系统时,它会受到影响。
- 它往往推荐受欢迎的项目。
注意:可以在此Jupyter Notebook中找到基于内容和基于内存的协同过滤的完整代码。
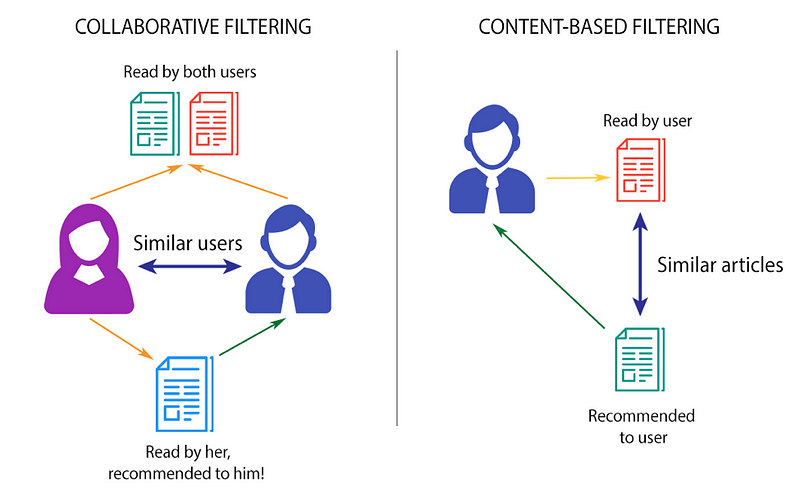
协作过滤与基于内容的过滤
3 - 矩阵分解
在之前的尝试中,我使用基于内存的协同过滤来根据用户的评级数据制作电影推荐。我只能在一个非常小的数据样本(20,000个评级)上尝试它们,最终得到相当高的Root均方误差(错误推荐)。计算项目或用户之间距离关系的基于内存的协同过滤方法存在以下两个主要问题:
- 它不能很好地扩展到海量数据集,尤其是基于用户行为相似性的实时建议 - 这需要大量的计算。
- 评级矩阵可能过度拟合用户品味和偏好的嘈杂表示。当我们在原始数据上使用基于距离的“邻域”方法时,我们匹配稀疏的低级细节,我们假设它们代表用户的偏好向量而不是向量本身。

减少数据维度的3个理由
因此,我需要应用维度降低技术从原始数据中导出品味和偏好,也称为低秩矩阵分解。为何减少尺寸?
- 我可以发现原始数据中隐藏的相关性/特征。
- 我可以删除无用的冗余和嘈杂功能。
- 我可以更容易地解释和可视化数据。
- 我还可以访问更简单的数据存储和处理。
数学
基于模型的协同过滤基于矩阵分解(MF),其已经受到更大的曝光,主要是作为用于潜变量分解和降维的无监督学习方法。矩阵分解被广泛用于推荐系统,它可以比基于内存的CF更好地处理可扩展性和稀疏性:
- MF的目标是学习用户的潜在偏好和来自已知评级的项目的潜在属性(学习描述评级特征的特征),然后通过用户和项目的潜在特征的点积来预测未知评级。
- 当你有一个非常稀疏的矩阵,有很多维度时,通过矩阵分解,你可以将用户项矩阵重构为低秩结构,你可以通过两个低秩矩阵的乘法来表示矩阵,其中行包含潜在的向量。
- 通过将低秩矩阵相乘,填充原始矩阵中缺失的条目,您可以使此矩阵尽可能接近地近似原始矩阵。
众所周知的矩阵分解方法是奇异值分解(SVD)。在较高的层次上,SVD是一种算法,它将矩阵A分解为原始矩阵A的最佳较低等级(即较小/较简单)近似。在数学上,它将A分解为两个酉矩阵和一个对角矩阵:
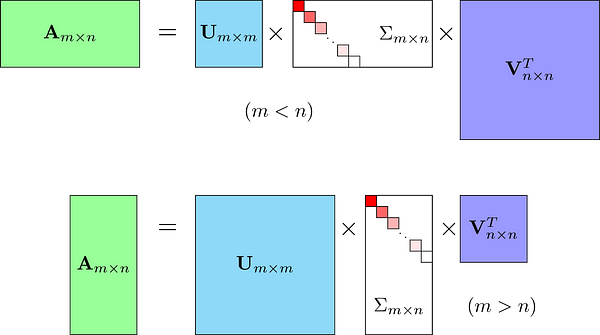
SVD方程
其中A是输入数据矩阵(用户的评级),U是左奇异向量(用户“特征”矩阵),Sum是奇异值的对角矩阵(基本上是每个概念的权重/强度),而V ^ T是右奇异向量(电影“特征”矩阵)。U和V ^ T是列正交,并且表示不同的事物:U表示用户“喜欢”每个特征的程度,V ^ T表示每个特征与每个电影的相关程度。
为了得到较低等级的近似值,我采用这些矩阵并仅保留前k个特征,这可以被认为是潜在的品味和偏好向量。
代码
Scipy和Numpy都具有进行奇异值分解的功能。我将使用Scipy函数svds因为它让我选择我想用多少潜在因子来近似原始评级矩阵(而不是在之后截断它)。
from scipy.sparse.linalg import svds
U, sigma, Vt = svds(Ratings_demeaned, k = 50)由于我将利用矩阵乘法来获得预测,我将把Sum(现在是值)转换为对角矩阵形式。
sigma = np.diag(sigma)我现在拥有了为每个用户制作电影评级预测所需的一切。我可以通过跟随数学和矩阵乘以U,Sum和V ^ T来同时完成所有操作,以获得等级k = 50的近似值A.
但首先,我需要添加用户手段以获得实际的星级评估预测。
all_user_predicted_ratings = np.dot(np.dot(U, sigma), Vt) + user_ratings_mean.reshape(-1, 1)通过每个用户的预测矩阵,我可以构建一个功能来为任何用户推荐电影。为了便于比较,我返回用户已评级的电影列表。
preds = pd.DataFrame(all_user_predicted_ratings, columns = Ratings.columns)现在我编写一个函数来返回指定用户尚未评级的最高预测评级的电影。
def recommend_movies(predictions, userID, movies, original_ratings, num_recommendations):
# Get and sort the user's predictions
user_row_number = userID - 1 # User ID starts at 1, not 0
sorted_user_predictions = preds.iloc[user_row_number].sort_values(ascending=False) # User ID starts at 1
# Get the user's data and merge in the movie information.
user_data = original_ratings[original_ratings.user_id == (userID)]
user_full = (user_data.merge(movies, how = 'left', left_on = 'movie_id', right_on = 'movie_id').
sort_values(['rating'], ascending=False)
)
# Recommend the highest predicted rating movies that the user hasn't seen yet.
recommendations = (movies[~movies['movie_id'].isin(user_full['movie_id'])].
merge(pd.DataFrame(sorted_user_predictions).reset_index(), how = 'left',
left_on = 'movie_id',
right_on = 'movie_id').
rename(columns = {user_row_number: 'Predictions'}).
sort_values('Predictions', ascending = False).
iloc[:num_recommendations, :-1]
)
return user_full, recommendations评价
我不会像上次那样手动进行评估,而是使用Surprise 库提供各种即用型强大的预测算法,包括(SVD)来评估其在MovieLens数据集上的RMSE(均方根误差)。这是一个Python Scikit-Learn构建和分析推荐系统。
# Import libraries from Surprise package
from surprise import Reader, Dataset, SVD, evaluate
# Load Reader library
reader = Reader()
# Load ratings dataset with Dataset library
data = Dataset.load_from_df(ratings[['user_id', 'movie_id', 'rating']], reader)
# Split the dataset for 5-fold evaluation
data.split(n_folds=5)
# Use the SVD algorithm.
svd = SVD()
# Compute the RMSE of the SVD algorithm.
evaluate(svd, data, measures=['RMSE'])我的平均均方根误差为0.8736,非常好。
建议
让我们尝试为ID为1310的用户推荐20部电影。
predictions = recommend_movies(preds, 1310, movies, ratings, 20)
predictions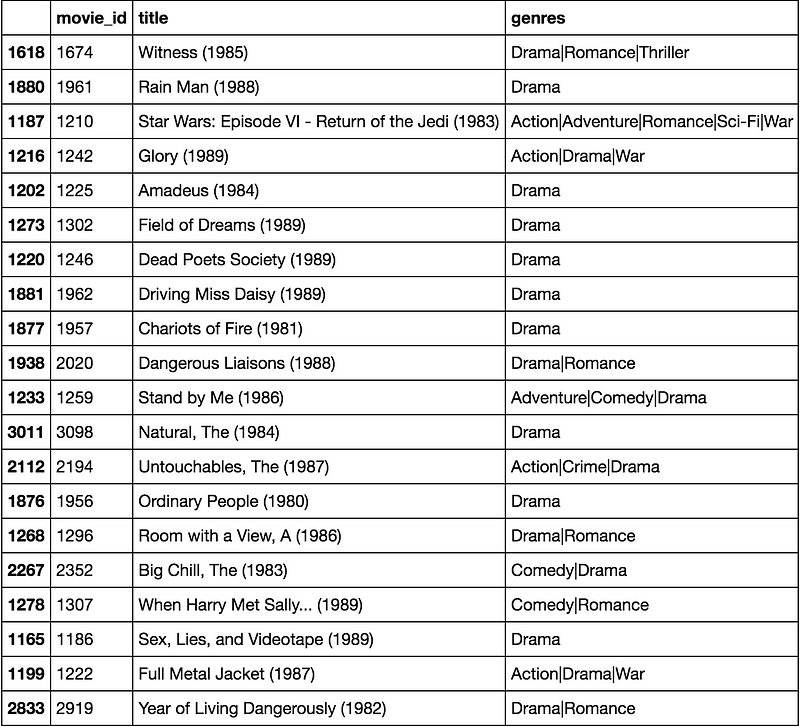
这些看起来很不错。很高兴看到,尽管我实际上没有将电影的类型用作特征,但是截断的矩阵分解特征“拾取”了用户的基本品味和偏好。我推荐了一些喜剧,戏剧和浪漫电影 - 所有这些都是这部用户评价最高的电影类型。
注意:可以在此Jupyter笔记本中找到SVD矩阵分解的完整代码。
4 - 深度学习
数学
使用深度学习的想法类似于基于模型的矩阵分解。在矩阵分解中,我们将原始稀疏矩阵分解为2个低秩正交矩阵的乘积。对于深度学习实现,我们不需要它们是正交的,我们希望我们的模型学习嵌入矩阵本身的值。从用于特定电影 - 用户组合的嵌入矩阵中查找用户潜在特征和电影潜在特征。这些是其他线性和非线性层的输入值。我们可以将此输入传递给多个relu,线性或sigmoid层,并通过任何优化算法(Adam,SGD等)学习相应的权重。
代码
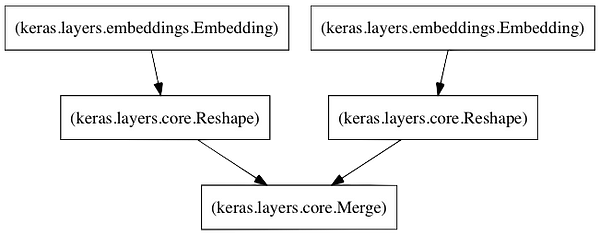
神经网络的体系结构
以下是我的神经网络的主要组成部分:
- 左嵌入层,用于创建按潜在因子矩阵的用户。
- 右侧嵌入图层,用于创建由潜在因素矩阵制作的电影。
- 当对这些层的输入是(i)用户id和(ii)电影id时,它们将分别返回用户和电影的潜在因子矢量。
- 合并层,采用这两个潜在向量的点积来返回预测评级。
此代码基于Alkahest的博客文章Colrasorative Filtering in Keras中概述的方法。
然后我使用Mean Squared Error(MSE)作为损失函数和AdaMax学习算法来编译模型。
# Define model
model = CFModel(max_userid, max_movieid, K_FACTORS)
# Compile the model using MSE as the loss function and the AdaMax learning algorithm
model.compile(loss='mse', optimizer='adamax')现在我需要训练模型。这一步将是最耗时的步骤。在我的特殊情况下,对于我们拥有近100万收视率,近6,000名用户和4,000部电影的数据集,我在MacBook笔记本电脑CPU中每个时期(30个纪元~3个小时)大约6分钟训练模型。我将培训和验证数据以90/10的比例进行了分配。
# Callbacks monitor the validation loss
# Save the model weights each time the validation loss has improved
callbacks = [EarlyStopping('val_loss', patience=2),
ModelCheckpoint('weights.h5', save_best_only=True)]
# Use 30 epochs, 90% training data, 10% validation data
history = model.fit([Users, Movies], Ratings, nb_epoch=30, validation_split=.1, verbose=2, callbacks=callbacks)下一步是实际预测随机用户将给随机电影的评级。下面我为所有用户和所有电影应用新训练的深度学习模型,每个使用100维嵌入。
# Use the pre-trained model
trained_model = CFModel(max_userid, max_movieid, K_FACTORS)
# Load weights
trained_model.load_weights('weights.h5')在这里,我定义了预测用户对未评级项目评级的功能。
# Function to predict the ratings given User ID and Movie ID
def predict_rating(user_id, movie_id):
return trained_model.rate(user_id - 1, movie_id - 1)评价
在上面的培训过程中,每次验证损失都有所改善时,我保存了模型权重。因此,我可以使用该值来计算最佳验证均方根误差。
# Show the best validation RMSE
min_val_loss, idx = min((val, idx) for (idx, val) in enumerate(history.history['val_loss']))
print 'Minimum RMSE at epoch', '{:d}'.format(idx+1), '=', '{:.4f}'.format(math.sqrt(min_val_loss))
## Output
Minimum RMSE at epoch 17 = 0.8616在时期17 ,最佳验证损失为0.7424。取该数字的平方根,我得到的RMSE值为0.8616,优于SVD模型的RMSE(0.8736)。
建议
在这里,我根据用户ID 2000的预测值制作了未评级的20部电影的推荐列表。让我们看一下。
recommendations = ratings[ratings['movie_id'].isin(user_ratings['movie_id']) == False][['movie_id']].drop_duplicates()
recommendations['prediction'] = recommendations.apply(lambda x: predict_rating(TEST_USER, x['movie_id']), axis=1)
recommendations.sort_values(by='prediction', ascending=False).merge(movies, on='movie_id', how='inner',
suffixes=['_u', '_m']).head(20)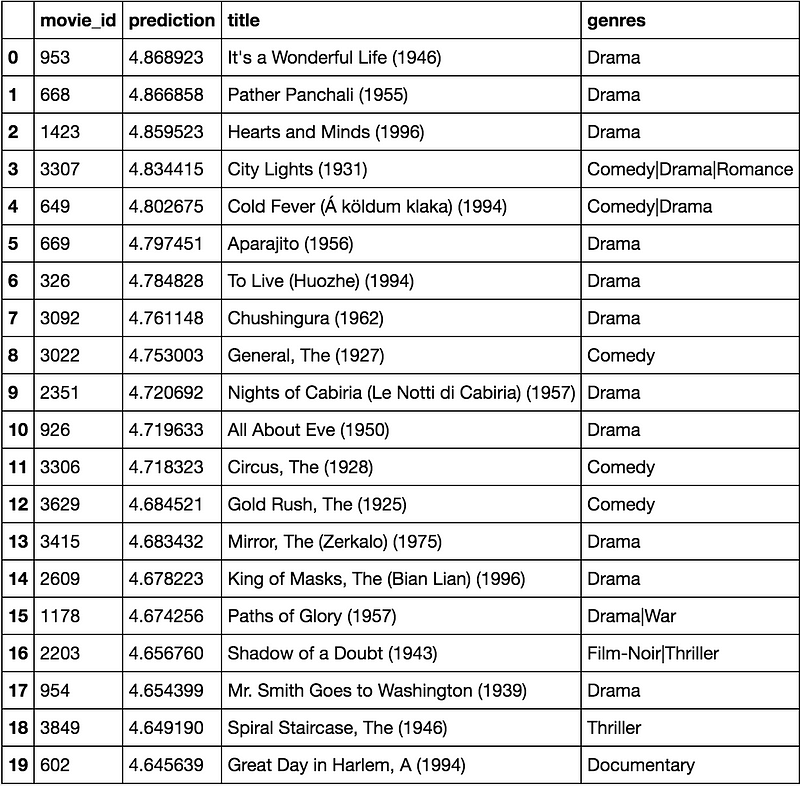
该模型比我之前尝试的所有方法(基于内容的,用户 - 项目相似性协同过滤,SVD)表现得更好。我当然可以通过更多线性和非线性层使其更深入来改善该模型的性能。
注意:可以在此Jupyter笔记本中找到深度学习模型的完整代码。
最后
推荐引擎是您的伴侣和顾问,通过为您提供量身定制的选项并为您创建个性化体验,帮助您做出正确的选择。毫无疑问,推荐引擎在新时代变得越来越受欢迎。学习使用它们使企业更具竞争力并使消费者更高效,这将符合您的最佳利益。
我希望这篇文章有助于您了解构建自己的电影推荐系统的4种不同方法。您可以通过此链接查看我的GitHub仓库中的所有源代码(https://github.com/khanhnamle1994/movielens)。如果您对改进有任何疑问或建议,请与我们联系!