根据师兄的建议看了GoogleNet论文。可能由于理论知识欠缺,这篇论文看得云里雾里,虽说在吴恩达的deeplearning课程中学习过,但是论文中还是有不少不懂的地方,只能借助其他人的笔记学习。
GoogleNet是深度为22层的,利用inception结构的网络。Inception结构很好地利用了网络中的计算资源,并且在不增加计算负载的情况下,增加网络的宽度和深度。同时,为了优化网络质量,采用了Hebbian原理和多尺度处理。GoogLeNet在分类和检测上都取得了不错的效果。
在related work中,作者介绍了一些参考方法:
GoogleNet参考Robust object recognition with cortex-like mechanisms.中利用固定的多个Gabor滤波器来进行多尺度处理的方法,对inception结构中的所有滤波器都进行学习,并运用至整个22层网络。
GoogLeNet参考Network in network.中对1x1卷积的使用来增加网络深度的做法,GoogLeNet也利用了1x1卷积来进行降维和限制网络尺寸的作用。这里其实就是之前学过的bottleneck层的作用。
GoogLeNet参考Rich feature hierarchies for accurate object detection and semantic segmentation(RCNN)分解问题的方法。在R-CNN中,目标检测被分为两个子问题:首先利用底层特征如颜色,超像素等来进行提取与类别无关的proposals,然后将这些proposals放入CNN中进行训练来确定类别信息。GoogleNet采用类似的做法,但进行了一些改进,例如为了得到更高bounding box recall的multi-box预测,同时还有bounding box proposal的更好分类的方法。
作者认为,提升DNN表现的最直接方法就是增加深度或者宽度,然而这种方法有两种缺点。
1.更大的网络有更多的参数,导致更倾向于过拟合,尤其是训练集中标注的例子的数量有限时。
2.网络大小的增加会导致计算资源的急剧增加。
因此,为了增加网络宽度和深度而又同时减少参数的inception结构被提出:
作者认为解决这两种问题的基本方法是将全连接改成稀疏连接结构,甚至在卷积内部。根据Arora的Provable bounds for learning some deep representations中的发现,如果数据集的概率分布能被一个大的,非常稀疏的深度神经网络来表示,最佳网络拓扑可以通过与输出高度相关的聚合神经元和上一层的激活函数的相关统计的分析逐层建立(这段话完全不懂。。。)。数学限制条件很多,根据Hebbian准则限制条件可以相对较少而可运用于实际。
通常全连接是为了更好的优化并行计算,而稀疏连接是为了打破对称来改善学习,传统常常利用卷积来利用空间域上的稀疏性,但卷积在网络的早期层中的与patches的连接也是稠密连接,因此考虑到能不能在滤波器层面上利用稀疏性,而不是神经元上。但是在非均匀稀疏数据结构上进行数值计算效率很低,并且查找和缓存未定义的开销很大,而且对计算的基础设施要求过高,因此考虑到将稀疏矩阵聚类成相对稠密子空间来倾向于对稀疏矩阵的计算优化。因此提出了inception结构。
inception结构的主要思想在于卷积视觉网络中一个优化的局部稀疏结构怎么样能由一系列易获得的稠密子结构来近似和覆盖。上面提到网络拓扑结构是由逐层分析上一层的相关统计信息并聚集到一个高度相关的单元组中,这些簇(单元组)表达下一层的单元(神经元)并与之前的单元相连接,而靠近输入图像的底层相关的单元在一块局部区域聚集,这就意味着我们可以在一块单一区域上聚集簇来结尾,并且他们能在下一层由一层1x1的卷积层覆盖,也即利用更少的数量在更大空间扩散的簇可由更大patches上的卷积来覆盖,也将减少越来越大的区域上patches的数量。
为了避免patch对齐问题,因此限制了inception结构中滤波器的大小为1x1,3x3,5x5。由于inception结构中都是互相堆叠的,因此输出相关统计信息一定不同:为了在高层能提取更抽象的特征,就要减少其空间聚集性,因此通过增加高层inception结构中的3x3,5x5卷积数量,捕获更大面积的特征。
对于上面一大段话差不多是从原文翻译的意思的整合,然而我还是不太明白,后来找到了一个相对直白的说法:
在传统的卷积网络中,每一层都会从之前的层提取信息,以便将输入数据转换成更有用的表征。但是,不同类型的层会提取不同种类的信息。5×5 卷积核的输出中的信息就和 3×3 卷积核的输出不同,又不同于最大池化核的输出……在任意给定层,我们怎么知道什么样的变换能提供最「有用」的信息呢?
因此引出见解:为什么不让模型选择呢?
Inception 模块会并行计算同一输入映射上的多个不同变换,并将它们的结果都连接到单一一个输出。换句话说,对于每一个层,Inception 都会执行 5×5 卷积变换、3×3 卷积变换和最大池化。然后该模型的下一层会决定是否以及怎样使用各个信息。

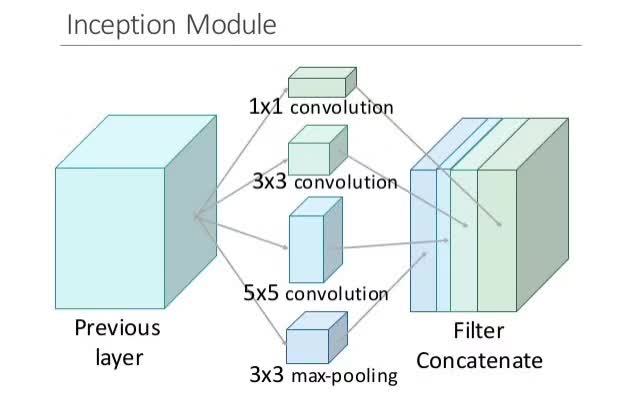
在上述inception结构中,由于滤波器数量的增加,加上池化操作使得5x5大小的滤波器的计算开销非常大,池化层输出与卷积层输出的合并增加了输出值的数量,并且可能覆盖优化稀疏结构,处理十分低效,引起计算爆炸。因此引出下面这个inception结构,即添加了bottleneck的inception结构。

inception结构中有很多嵌套,低维嵌套包含了大量的图片patch信息,且这种嵌套表达了一个稠密且压缩的信息的形式,但我们想要表达的更加稀疏,并且只在大量聚集的时候才对信号进行压缩,因此考虑利用在3x3和5x5卷积操作前进行1x1卷积来进行降维处理,1x1不仅降维,而且还引入了ReLU非线性激活。实际发现,只在高层中使用inception结构对整个网络更加有利。
inception结构的好处在于在没有计算复杂度不受控制的计算爆炸时,可以增加每个阶段的单元个数,也就是网络的宽度,当然还有深度;同时这种结构也类似于图像中多尺度处理之后将处理结果聚集在一起以便于下一个阶段能同时提取不同尺寸下的特征。
由于稀疏结构的计算量大的问题,所以采用1x1的卷积来减少参数的计算,其中1x1 卷积解释为:
在3x3和5x5层前,各自增加一个1x1的卷积操作。1x1的卷积(或者网络层中的网络),提供了一个减少维度的方法。比如,我们假设你拥有一个输入层,体积是100x100x60(这并不定是图像的三个维度,只是网络中每一层的输入)。增加20个1x1的卷积滤波器,会让你把输入的体积减小到100x100x20。这意味着,3x3层和5x5层不需要处理输入层那么大的体积。这可以被认为是“池特征”(pooling of feature),因为我们正在减少体积的高度,这和使用常用的最大池化层(maxpooling layers)减少宽度和长度类似。另一个需要注意的是,这些1x1的卷积层后面跟着的是ReLU 单元,这肯定不会有害。
有了上面的这种结构形式,叫inception:这个inception模型由一个网络层中的网络、一个中等大小的过滤卷积、一个大型的过滤卷积、一个操作池(pooling operation)组成。网络卷积层中的网络能够提取输入体积中的每一个细节中的信息,同时5x5的滤波器也能够覆盖大部分接受层的的输入,进而能提起其中的信息。你也可以进行一个池操作,以减少空间大小,降低过度拟合。在这些层之上,你在每一个卷积层后都有一个ReLU,这能改进网络的非线性特征。基本上,网络在执行这些基本的功能时,还能同时考虑计算的能力。这篇论文还提供了更高级别的推理,包括的主题有稀疏和紧密联结。

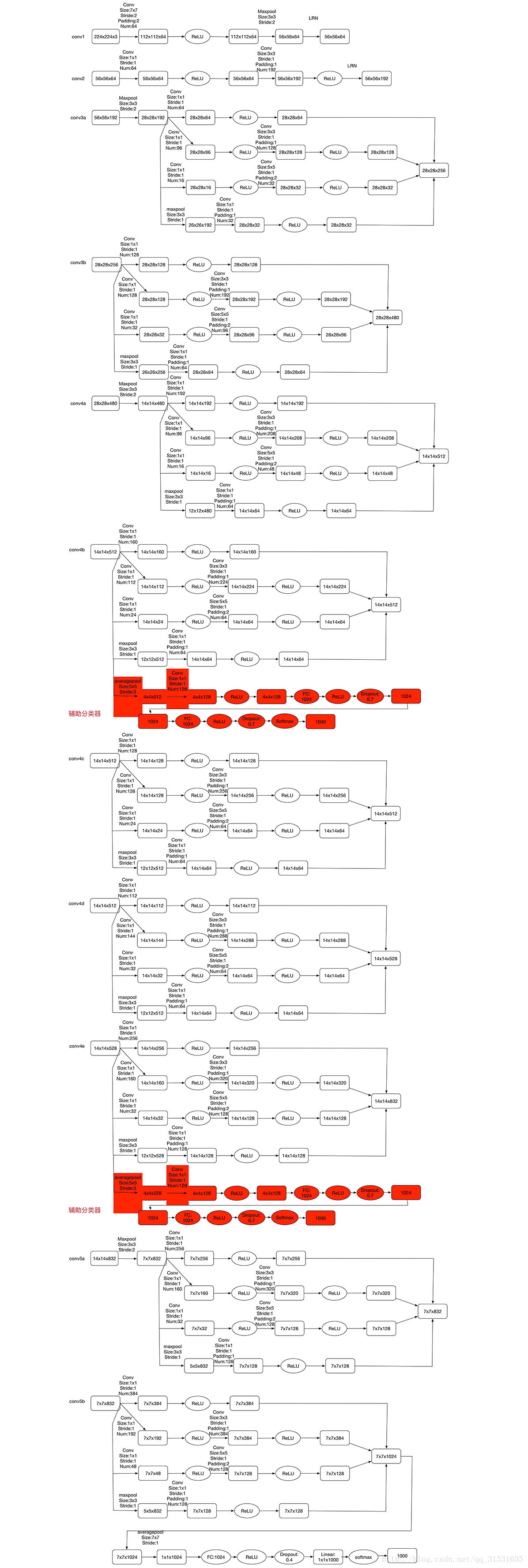
上图为GoogLeNet的网络框图细节,其中“#3x3 reduce”,“#5x5 reduce”代表在3x3,5x5卷积操作之前使用1x1卷积的数量。输入图像为224x224x3,且都进行了零均值化的预处理操作,所有降维层也都是用了ReLU非线性激活函数。
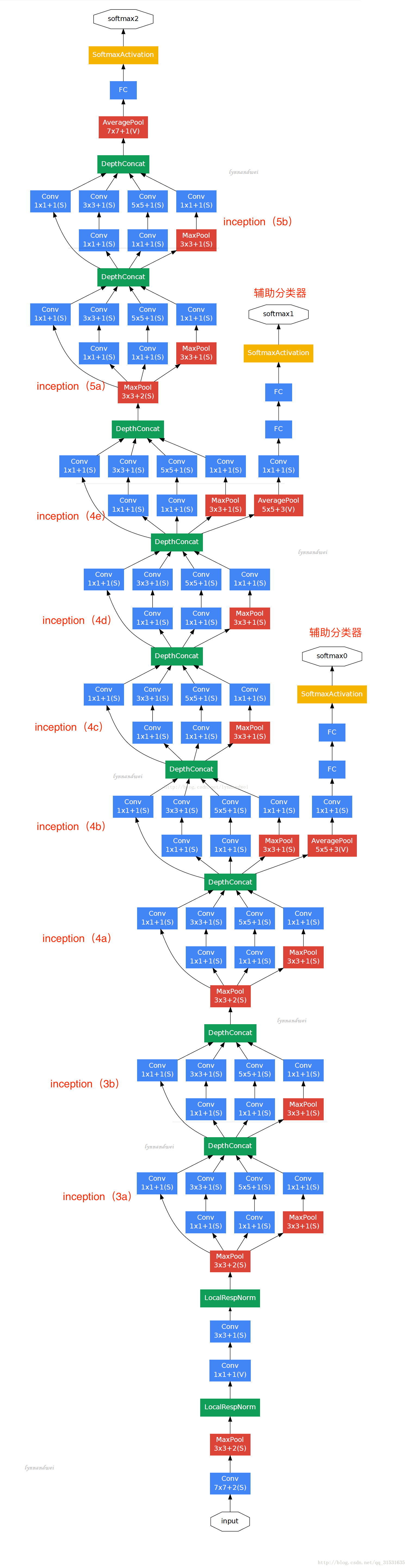
如上图用到了辅助分类器,Inception Net有22层深,除了最后一层的输出,其中间节点的分类效果也很好。因此在Inception Net中,还使用到了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中。这样有利于增强分类器低层表现,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception Net的训练很有裨益。
辅助分类器结构如下图标注出: