最近在“小象学院”上知识图谱的课程,做了一些笔记,现整理了一下
1、什么是知识融合
将来自不同知识库的同一实体融合在一起
目标:融合各层面的知识
合并两个知识图谱(本体),需要确认的是:
(1)等价实例 实体的匹配 左右两个人是同一个人 samsAs 猫王
(2)等价类/子类 摇滚歌手是歌手的子类 subClassOf
(3)等价属性/子属性 出生于出生日期是等价的属性 subPropertyOf

上图中左右两个是同一个人,只是来自不同的知识库,一个来自YAGO,一个来自ElvisPedia
另一个例子:

来源于不同知识库的“自由女神像”
知识图谱的构建经常需要融合多种不同来源的数据

知识对齐是知识图谱融合的主要工作

上图中的边表示“sameAs”,边越粗,表示sameAs的比例越高,位于中心与其他的节点或数据源边越多,表示它的领域越开放,即充分的与其他领域的重合度
图中不同的颜色代表不同的知识图谱来源,
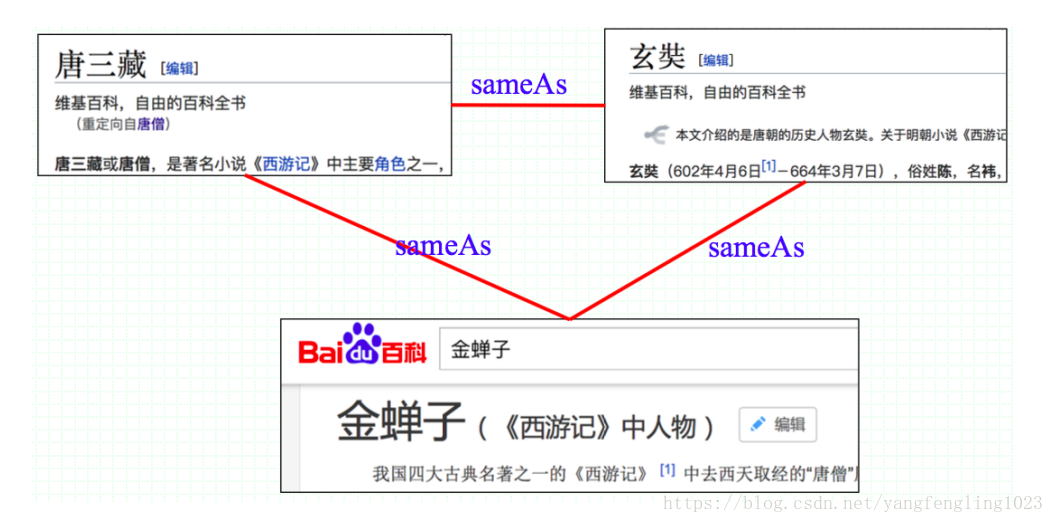
中文百科中的等价实例:
在不同的文献中,知识融合有不同的叫法,如本体对齐、本体匹配、Record Linkage、Entity Resolution、实体对齐等叫法,但它们的本质工作是一样的。
知识图谱的基本问题是怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来,如下图:

上图中将不同表现形式的人统一一下
知识融合的主要技术挑战
目前知识融合的主要技术挑战有两点:
1)数据质量的挑战:如命名模糊,数据输入错误、数据丢失、数据格式不一致、缩写等等
2)数据规模的挑战:数据量大(并行计算)、数据种类多样性、不再仅仅通过名字匹配、多种关系、更多链接等
2、知识融合的基本技术流程
流程如下图所示:
知识融合一般分为两步:本体对齐、实体匹配,且两者的基本流程相类似

下面对各个部分进行简单的介绍
数据预处理
在数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤
1)语法正规化:
语法匹配:如联系电话的表示方法
综合属性:如家庭地址的表达方式
2)数据正规化:
移除空格、《》、“”、-等等
输入错误类的拓扑错误
用正式名字替换昵称和缩写等等
记录链接
假设两个实体的记录x和y,x和y在第i个属性上的值是xi,yi,那么通过如下两步进行记录链接
1)属性相似度:综合单个属性相似度得到属性相似度向量

2)实体相似度:根据属性相似度向量得到一个实体的相似度
实体关系发现框架Limes
教程网址:http://openkg1.oss-cn-beijing.aliyuncs.com/d9780259-7e4f-456f-88fa-8274a3def82b/tutorial-limes.pdf
在执行下面的操作之前,若自己的电脑上没有安装maven,则需要进行这个安装,安装其实很简单,下载相应的包,解压到指定位置,将/bin添加到系统变量上即可,网上有很多教程,在这里就不进行多解释了
获取limes:
git clone https://github.com/dice-group/LIMES
编译源码:
进入limes-core目录编译:
cd limes-core
mvn clean install
创建可运行的Jar文件:
mvn clean package shade:shade --Dcheckstyle.skip=true -Dmaven.test.skip=true
生成 limes-core-VERSION-SNAPSHOT.jar
运行jar文件:
cd target
java -jar limes-core-1.0.0-SNAPSHOT.jar config.xml ##其中的1.0.0根据你生成的版本进行适当的修改

config.xml是自定义的配置文件,可以换成其他的名字