1.Set集合
(1)set特点:
内容不能重复 无顺序 (无下标)
(2)常用方法:
方法来自Collection方法
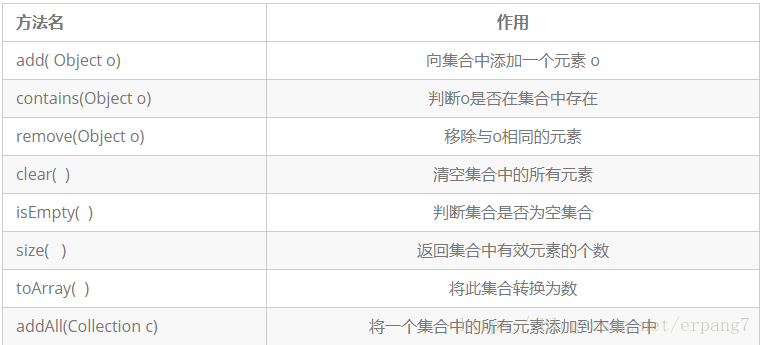
自身没有其他方法
(3)遍历
①迭代器遍历
package nearly.test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetTest01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
//set集合,泛型控制类型
Set<String> set =new HashSet<>();
set.add("alilang");
set.add("taishan");
set.add("huojianshaonv");
set.add("kaluli");
//2.迭代器+while进行遍历
Iterator<String> it=set.iterator();
while(it.hasNext()){
System.out.println("姓名:"+it.next());
}
}
}
②for-each遍历
package nearly.test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetTest01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
//set集合,泛型控制类型
Set<String> set =new HashSet<>();
set.add("alilang");
set.add("taishan");
set.add("huojianshaonv");
set.add("kaluli");
//1.for-each循环遍历set集合
for(String str:set){
System.out.println("姓名:"+str);
}
}
}

1.HashSet 散列表 存储、访问效率极高
o.hashCode(); //得到o对象的哈希码
/*
Object类中:hashCode()
通过.hashCode() 得到对象哈希码
*/
o-数组长度的数
o在散列表中的下标如果自定义对象放入HashSet为了保证元素内容的不重复
①覆盖HashCode()方法,保证相同的对象可以返回相同的哈希码
例子:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
long temp;
temp = Double.doubleToLongBits(salary);
result = prime * result + (int) (temp ^ (temp >>> 32));
return result;
}②覆盖equals()方法,保证相同对象返回true
例如:
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Worker other = (Worker) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (Double.doubleToLongBits(salary) != Double.doubleToLongBits(other.salary))
return false;
return true;
}③不仅要保证相同对象返回相同哈希码,还应当尽可能保证不同对象哈希不同
注:HashSet散列表 查询效率高 增删效率高 需要让元素在散列表中的排列分布尽可能分散 内存使用效率低
(4)实现类:
①LinkedHashSet Hash子类
只是保证元素遍历顺序和添加顺序保持一致
②TreeSet
自动对set中的元素做排序 利用排序规则,CompareTo返回值为0 即认为内容相同
所以只有当两个对象equals为true时,才应该让compareTo返回0
TreeSet是SortedSet(Set的子接口)的实现类
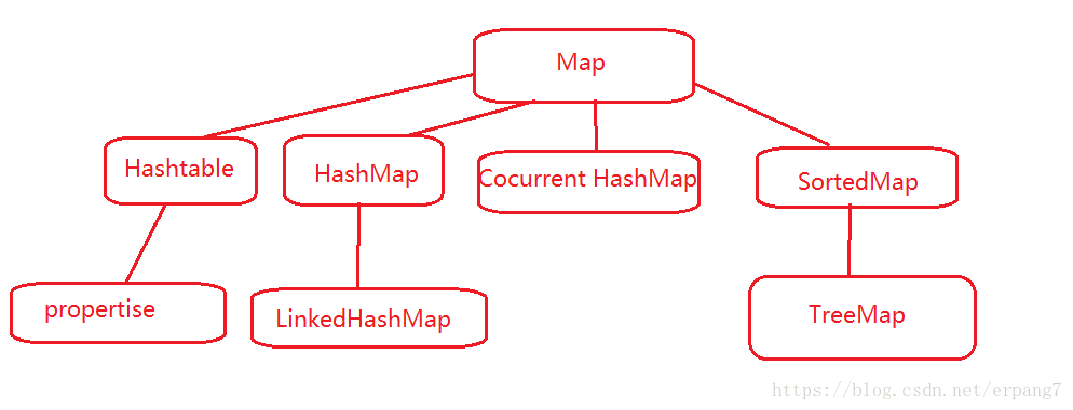
2.Map集合
(1)特点
元素是键值对 key-value
key是不可重复的 无顺序
value可以重复的
通过key查找对应的value
(2)常用方法
①put(Object key,Object value)
将key-value添加到map集合中,如果key已存在,新的value覆盖旧的value
②get(Object key)
通过key查找value
③size()
获得集合的长度
④remove(Object key)
删除对应的key-value对
⑤Containskey(K key)
判断Map中key是否存在
⑥ContainsValue(V value)
判断Map中value是否存在
(3)遍历
①keySet() 键遍历
返回map中所有的键
package nearly.test;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class MapTest01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Map<String,Double> map=new HashMap<>();
map.put("张全蛋", 65.5);
map.put("大头怪", 35.5);
map.put("大队长", 95.8);
map.put("赵铁柱", 75.5);
map.put("葫芦娃", 65.7);
map.put("霸波本", 75.5);
map.put("奔波霸", 85.5);
//1.for-each+keyset循环遍历
Set<String> set=map.keySet();
Iterator<String> it=set.iterator();
Double sumScore=0.0;
for (String string : set) {
Double value=map.get(string);
sumScore+=value;
}
System.out.println("平均成绩为:"+sumScore/map.size());
//2.set+while循环遍历
Set<String> set=map.keySet();
Iterator<String> it=set.iterator();
Double sumScore=0.0;
while(it.hasNext()){
String key= it.next();
Double value=map.get(key);
sumScore+=value;
}
System.out.println("平均成绩:"+sumScore/map.size());*/
}
}
②values() 值遍历
返回map中所有的值
返回值:既非List又非Set 是Collection
package nearly.test;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class MapTest01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Map<String,Double> map=new HashMap<>();
map.put("张全蛋", 65.5);
map.put("大头怪", 35.5);
map.put("大队长", 95.8);
map.put("赵铁柱", 75.5);
map.put("葫芦娃", 65.7);
map.put("霸波本", 75.5);
map.put("奔波霸", 85.5);
//4.值遍历
Collection ct=map.values();
Double sumScore=0.0;
for (Object object : ct) {
sumScore+=(Double) object;
}
System.out.println("平均成绩:"+sumScore/map.size());
}
}
③entrySet遍历
内部静态接口(写于map里边)
entrySet():返回Map中所有的Entry对象,每个entry对象都封装了 key-value两个对象
返回值:Set<Map.Entry>
package nearly.test;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class MapTest01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Map<String,Double> map=new HashMap<>();
map.put("张全蛋", 65.5);
map.put("大头怪", 35.5);
map.put("大队长", 95.8);
map.put("赵铁柱", 75.5);
map.put("葫芦娃", 65.7);
map.put("霸波本", 75.5);
map.put("奔波霸", 85.5);
//3.entryset集合遍历
Set<Entry<String,Double>> es=map.entrySet();
Double sumScore=0.0;
for (Entry<String, Double> entry : es) {
Double value=entry.getValue();
sumScore+=value;
}
System.out.println("平均成绩:"+sumScore/map.size());
}
}
(4)实现类:
①HashMap
使用哈希算法去掉重复的键
允许空指针作为键和值
更新于JDK1.2 线程不安全 快
②Hashtable
不允许键值是空指针
更新于JDK1.0 线程安全 慢
③LinkedHashMap
是HashMap的一个子类
维护键值对的顺序
④TreeMap
SortedMap(Map 的子接口)的实现类
自动对键作排序
⑤properties
Hashtable的子类
键值对都是字符串(String)
通常用作配置文件的读取
⑥ConcurrentHashMap
线程安全 快 Since JDK1.5