-》ip,hostname,/etc/hosts
192.168.134.223 bigdata-hpsk02.huadiancom
192.168.134.224 bigdata-hpsk02.huadiancom
192.168.134.225 bigdata-hpsk02.huadiancom
-》克隆后机器,使用root:
vim /etc/udev/rules.d/70-persistent-net.rules
-》删掉eth0
-》将eth1修改为eth0
-》复制mac地址
编辑网卡文件:vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改ip地址及Mac地址
IPADDR=192.168.134.199
HWADDR=00:0C:29:65:64:A8
重启网络:service network restart
ifconfig
-》Linux环境配置
-》ip、主机名、本地映射(/etc/hosts),DNS
-》关闭防火墙,selinux
-》在Linux中创建统一的用户,统一的目录
-》修改句柄数
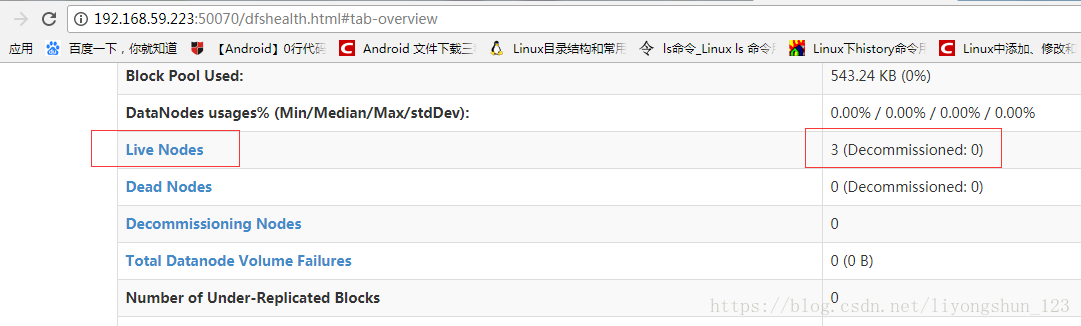
-》ssh免密钥登录
-》hadoop的启动方式
-》单个进程启动:用于启动
sbin/hadoop-daemon.sh start namenode
-》分别启动yarn和hdfs:用于关闭
sbin/start-dfs.sh
-》namenode
-》datanode
-》secondarynamenode
sbin/start-yarn.sh
-》resourcemanager
-》所有的nodemanager
-》一次性启动所有进程
sbin/start-all.sh
-》第一步:每台机器为自己创建公私钥
ssh-keygen -t rsa :/home/hpsk/.ssh
ssh-keygen -t rsa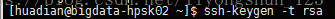
四次回车,当出现下图是成功
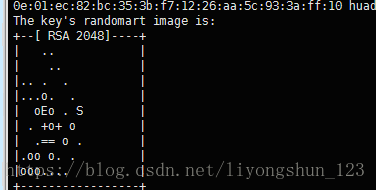
把自己的公钥发给每台机器,包括自己




测试是否成功
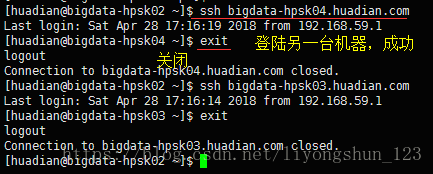
然后另外的机器,同样,把自己的公钥发给每一台机器,包括自己

-》NTP时间同步:通过ntp服务实现每台机器的 时间一致
-》通过Linux crontab实现
根据时间规则取执行某个命令
crontab -e
* * * * * command
分 时 日 月 周
00-59 00-23 1-31 1-12 0-7
每天凌晨两点执行shell.sh
00 2 * * * sh /opt/datas/shell.sh
*/1 * * * * ntpdate ntp_server_ip
00 1,2 * * *
1-2
-》直接使用ntp服务同步外网时间服务器
-》选择一台机器作为中间同步服务A,A与外网进行同步,B,C同步A
-》配置A sudo vim /etc/ntp.con

删除默认配置:所有的机器都删除
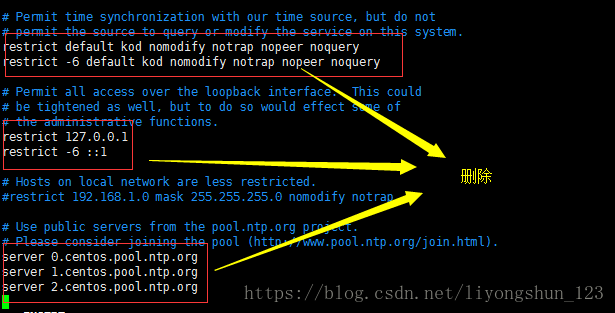
-》添加
配置A允许哪些机器与我同步
restrict 192.168.134.0 mask 255.255.255.0 nomodify notrapserver 202.112.10.36 server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10 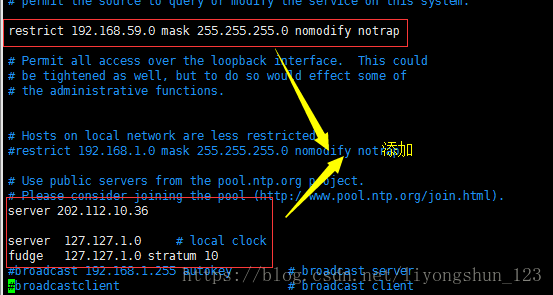
-》配置B,C同步A
在BC,机器上
sudo vim /etc/ntp.confserver 192.168.59.223-》节点分布:
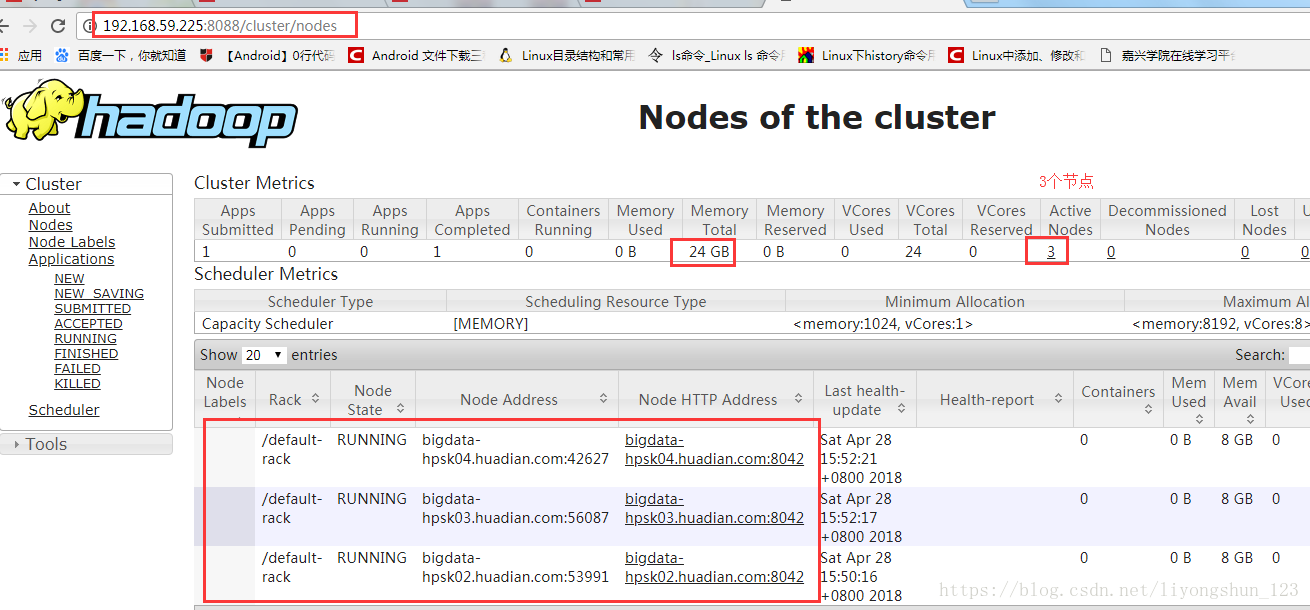
在第一台机器上namenode主节点,第三台配置resourcemanager(工作)
node2 datanode nodemanager
node3 datanode nodemanager resourcemanager(工作)
-》安装jdk
在第一台上安装jdk
tar -zxvf /opt/datas/jdk-8u91-linux-x64.tar.gz -C /opt/modules/
分发到其他机器
scp -r jdk1.8.0_91 [email protected]:/opt/modules/
下载:2下载1的
scp -r [email protected]:/opt/modules/jdk1.8.0_91 /opt/modules/
scp -r [email protected]:/opt/modules/jdk1.8.0_91 /opt/modules/
-》配置环境变量
##JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_91
export PATH=$PATH:$JAVA_HOME/bincd ..
-》安装hadoop
-》下载解压安装
-》修改配置文件
-》env.sh:配置环境变量
hadoop-env
mapred-env
yarn-env
-》JAVA_HOME
-》site.xml:配置用户自定义需求
core-site:配hadoop全局的一些属性
fs.defaultFS:hdfs的入口
hadoop.tmp.dir hadoop临时存储目录
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-hpsk02.huadian.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.3/datas</value>
</property>
hdfs-site:配置hdfs的属性
dfs.replication:文件副本数
dfs.permission.enabled
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>MapReduce运行在yarn上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site:用于配置yarn的属性
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-hpsk04.huadian.com</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>-》slaves:配置所有从节点的 地址
一行一个
bigdata-hpsk02.huadian.com
bigdata-hpsk03.huadian.com
bigdata-hpsk04.huadian.com
scp -r hadoop-2.7.3 [email protected]:/opt/modules/ scp -r hadoop-2.7.3 [email protected]:/opt/modules/ scp -r [email protected]:/opt/modules/hadoop-2.7.3 /opt/modules/-》格式化文件系统
-》只在主节点namenode那里格式化
bin/hdfs namenode -format-》启动对应的进程
-》namenode哪里开启hdfs的主节点,即在第一台机器上开启namenode主节点

-》开启所有的从节点



-》resourcemanager哪里开启yarn的主节点,即在第一台机器上开启namenode主节点
即在第三台机器上,可以按照上面的先在第三台上面开启主节点
sbin/yarn-daemon.sh start resourcemanager然后分别在所有的机器上开启从节点
sbin/yarn-daemon.sh start nodemanager-》也可以在第三台机器上同时开启
sbin/start-yarn.sh 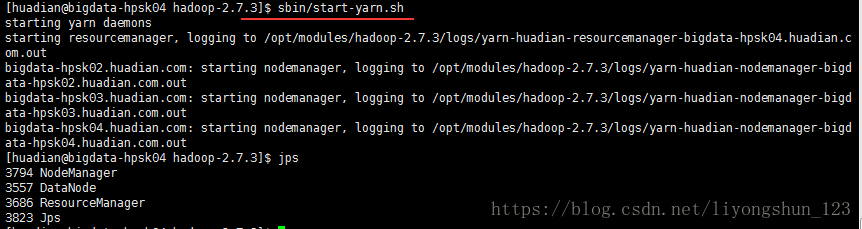

浏览器测试