1. 机器学习
机器学习可以看做是一门人工智能的科学,该领域的主要研究对象是人工智能。机器学习利用数据或以往的经验,以此优化计算机程序的性能标准。
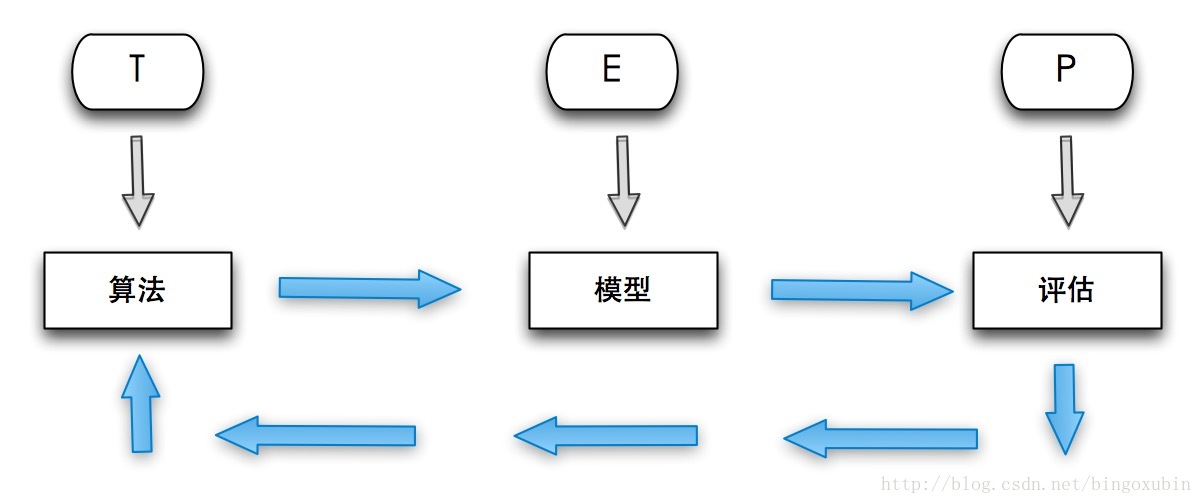
机器学习强调三个关键词:算法、经验、性能,其处理过程如上图所示。在数据的基础上,通过算法构建出模型并对模型进行评估。评估的性能如果达到要求,就用该模型来测试其他的数据;如果达不到要求,就要调整算法来重新建立模型,再次进行评估。如此循环往复,最终获得满意的经验来处理其他的数据。机器学习技术和方法已经被成功应用到多个领域,比如个性推荐系统,金融反欺诈,语音识别,自然语言处理和机器翻译,模式识别,智能控制等。
2. 基于大数据的机器学习
传统的机器学习算法,由于技术和单机存储的限制,只能在少量数据上使用。即以前的统计/机器学习依赖于数据抽样。但实际过程中样本往往很难做好随机,导致学习的模型不是很准确,在测试数据上的效果也可能不太好。随着 HDFS(Hadoop Distributed File System) 等分布式文件系统出现,存储海量数据已经成为可能。在全量数据上进行机器学习也成为了可能,这顺便也解决了统计随机性的问题。然而,由于 MapReduce 自身的限制,使得使用 MapReduce 来实现分布式机器学习算法非常耗时和消耗磁盘IO。因为通常情况下机器学习算法参数学习的过程都是迭代计算的,即本次计算的结果要作为下一次迭代的输入,这个过程中,如果使用 MapReduce,我们只能把中间结果存储磁盘,然后在下一次计算的时候从新读取,这对于迭代 频发的算法显然是致命的性能瓶颈。
在大数据上进行机器学习,需要处理全量数据并进行大量的迭代计算,这要求机器学习平台具备强大的处理能力。Spark 立足于内存计算,天然的适应于迭代式计算。即便如此,对于普通开发者来说,实现一个分布式机器学习算法仍然是一件极具挑战的事情。幸运的是,Spark提供了一个基于海量数据的机器学习库,它提供了常用机器学习算法的分布式实现,开发者只需要有 Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程。其次,Spark-Shell的即席查询也是一个关键。算法工程师可以边写代码边运行,边看结果。spark提供的各种高效的工具正使得机器学习过程更加直观便捷。比如通过sample函数,可以非常方便的进行抽样。当然,Spark发展到后面,拥有了实时批计算,批处理,算法库,SQL、流计算等模块等,基本可以看做是全平台的系统。把机器学习作为一个模块加入到Spark中,也是大势所趋。
3. Spark 机器学习库MLLib
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要包括以下几方面的内容:
算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
特征化公交:特征提取、转化、降维,和选择公交;
管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
持久性:保存和加载算法,模型和管道;
实用工具:线性代数,统计,数据处理等工具。
Spark 机器学习库从 1.2 版本以后被分为两个包:
spark.mllib包含基于RDD的原始算法API。Spark MLlib 历史比较长,在1.0 以前的版本即已经包含了,提供的算法实现都是基于原始的 RDD。
spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件。
使用 ML Pipeline API可以很方便的把数据处理,特征转换,正则化,以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。这种方式给我们提供了更灵活的方法,更符合机器学习过程的特点,也更容易从其他语言迁移。Spark官方推荐使用spark.ml。如果新的算法能够适用于机器学习管道的概念,就应该将其放到spark.ml包中,如:特征提取器和转换器。开发者需要注意的是,从Spark2.0开始,基于RDD的API进入维护模式(即不增加任何新的特性),并预期于3.0版本的时候被移除出MLLib。
Spark在机器学习方面的发展非常快,目前已经支持了主流的统计和机器学习算法。纵观所有基于分布式架构的开源机器学习库,MLlib可以算是计算效率最高的。MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤。下表列出了目前MLlib支持的主要的机器学习算法:
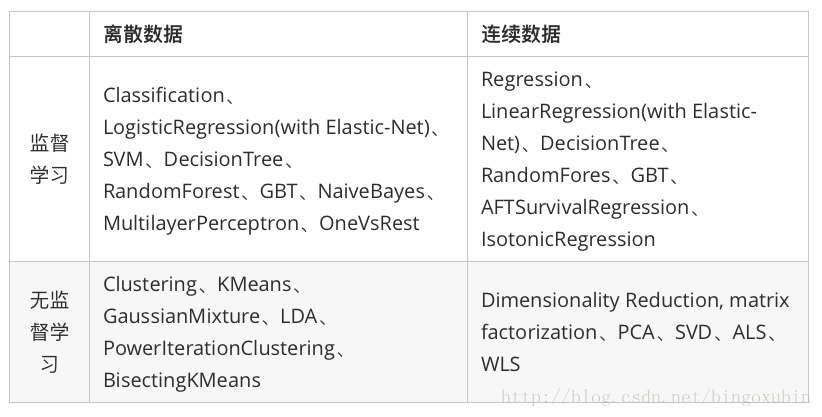
MLlib 是spark的可以扩展的机器学习库,由以下部分组成:通用的学习算法和工具类,包括分类,回归,聚类,协同过滤,降维,当然也包括调优的部分
- Data types
- Basic statistics (基本统计)
- summary statistics 概括统计
- correlations 相关性
- stratified sampling 分层取样
- hypothesis testing 假设检验
- random data generation 随机数生成
- Classification and regression (分类一般针对离散型数据而言的,回归是针对连续型数据的。本质上是一样的)
- linear models (SVMs, logistic regression, linear regression)线性模型(支持向量机,逻辑回归,线性回归)
- naive Bayes 贝叶斯算法
- decision trees 决策树
- ensembles of trees (Random Forests and Gradient-Boosted Trees)
多种树(随机森林和梯度增强树)
- Collaborative filtering 协同过滤
- alternating least squares (ALS) (交替最小二乘法(ALS) )
- Clustering 聚类
- k-means k均值算法
- Dimensionality reduction (降维)
- singular value decomposition (SVD) 奇异值分解
- principal component analysis (PCA) 主成分分析
- Feature extraction and transformation 特征提取和转化
- Optimization (developer) 优化部分
- stochastic gradient descent 随机梯度下降
- limited-memory BFGS (L-BFGS) 短时记忆的BFGS (拟牛顿法中的一种,解决非线性问题)
4. 线性回归实例
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaDoubleRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.mllib.evaluation.RegressionMetrics;
import org.apache.spark.mllib.linalg.Vectors;
import org.apache.spark.mllib.regression.LabeledPoint;
import org.apache.spark.mllib.regression.LinearRegressionModel;
import org.apache.spark.mllib.regression.LinearRegressionWithSGD;
import scala.Tuple2;
public class SparkMLlibLinearRegression {
public static void main(String[] args) {
String path = "file:///data/hadoop/spark-2.0.0-bin-hadoop2.7/data/mllib/ridge-data/lpsa.data";
SparkConf conf = new SparkConf();
JavaSparkContext sc = new JavaSparkContext(args[0], "Spark", conf);
JavaRDD<String> data = sc.textFile(path);
JavaRDD<LabeledPoint> parsedData = data.map(new Function<String, LabeledPoint>() {
@Override
public LabeledPoint call(String line) throws Exception {
String[] parts = line.split(",");
String[] features = parts[1].split(" ");
double[] v = new double[features.length];
for (int i = 0; i < v.length; i++) {
v[i] = Double.parseDouble(features[i]);
}
return new LabeledPoint(Double.parseDouble(parts[0]), Vectors.dense(v));
}
});
parsedData.cache();
// Building the model
int numIterations = 100;
double stepSize = 0.00000001;
final LinearRegressionModel model =
LinearRegressionWithSGD.train(JavaRDD.toRDD(parsedData), numIterations, stepSize);
// Evaluate model on training examples and compute training error
JavaRDD<Tuple2<Double, Double>> valuesAndPreds = parsedData.map(new Function<LabeledPoint, Tuple2<Double, Double>>(){
@Override
public Tuple2<Double, Double> call(LabeledPoint point)
throws Exception {
double prediction = model.predict(point.features());
return new Tuple2<Double, Double>(prediction, point.label());
}
});
double MSE = new JavaDoubleRDD(valuesAndPreds.map(
new Function<Tuple2<Double, Double>, Object>() {
public Object call(Tuple2<Double, Double> pair) {
return Math.pow(pair._1() - pair._2(), 2.0);
}
}
).rdd()).mean();
System.out.println("training Mean Squared Error = " + MSE);
//模型评测
JavaRDD<Tuple2<Object, Object>> valuesAndPreds2= parsedData.map(new Function<LabeledPoint, Tuple2<Object, Object>>(){
@Override
public Tuple2<Object, Object> call(LabeledPoint point)
throws Exception {
double prediction = model.predict(point.features());
return new Tuple2<Object, Object>(prediction, point.label());
}
});
RegressionMetrics metrics = new RegressionMetrics(JavaRDD.toRDD(valuesAndPreds2));
System.out.println("R2(决定系数)= "+metrics.r2());
System.out.println("MSE(均方差、方差) = "+metrics.meanSquaredError());
System.out.println("RMSE(均方根、标准差) "+metrics.rootMeanSquaredError());
System.out.println("MAE(平均绝对差值)= "+metrics.meanAbsoluteError());
// Save and load model
model.save(sc.sc(), "target/tmp/javaLinearRegressionWithSGDModel");
LinearRegressionModel sameModel = LinearRegressionModel.load(sc.sc(),
"target/tmp/javaLinearRegressionWithSGDModel");
double result = sameModel.predict(Vectors.dense(-0.132431544081234,2.68769877553723,1.09253092365124,1.53428167116843,-0.522940888712441,-0.442797990776478,0.342627053981254,-0.687186906466865));
System.out.println(sameModel.weights());
System.out.println("save predict result="+ result);
result = model.predict(Vectors.dense(-0.132431544081234,2.68769877553723,1.09253092365124,1.53428167116843,-0.522940888712441,-0.442797990776478,0.342627053981254,-0.687186906466865));
System.out.println(model.weights());
System.out.println("predict result="+ result);
}
}