前言
搜索引擎指的是通过一定的策略, 从互联网中获取到数据, 将这些数据保存到自己的服务器当中, 然后提供用户一个页面, 用来做查询的, 这个就被称为搜索引擎 例如: 百度、谷歌
原始数据库查询的弊端
- 1) 当数据量很大的时候, 当用户输入一个内容的时候, 我们很难在很快的时间进行返回
- 2) 原始的数据库中模糊查询, 只能进行首尾的匹配
- 3) 当用户输入错误, 那么原始的数据库将会和用户的基本需求相差太远
倒排索引
倒排索引, 指定的将一句话,或者是一段话进行分词, 然后将分词的后的内容保存到索引库当中, 建立索引, 这样当用户输入一些内容的时候, 将用户输入的内容进行分词, 将分词后的数据到索引库中进行匹配, 如果有对应的数据将其对应的内容进行返回
Lucene 入门
引入pom相关jar
<!--lucene 的核心包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.2</version>
</dependency>
<!--lucene 的查询依赖包(可以省略)-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
<version>4.10.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-test-framework</artifactId>
<version>4.10.2</version>
</dependency>
<!--lucene的分词器的包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.2</version>
</dependency>
<!--lucene的查询包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.2</version>
</dependency>
<!--lucene的高亮的包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>4.10.2</version>
</dependency>
<!-- 引入IK分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>下面来执行一个简单的写入案例
public static void base() throws IOException {
//目录(索引库位置)
FSDirectory directory = FSDirectory.open(new File("D:\\open"));
//分词器
Analyzer analyzer = new StandardAnalyzer();
//写入器的配置对象
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
//创建索引写入器
IndexWriter indexWriter = new IndexWriter(directory, config);
//写入一个文档
Document document = new Document();
document.add(new LongField("id", 1L, Field.Store.YES));
document.add(new TextField("content",
"welcome to china, how are you", Field.Store.YES));
document.add(new StringField("title", "欢迎来到中国", Field.Store.NO));
indexWriter.addDocument(document);
//提交
indexWriter.commit();
indexWriter.close();
}通过以上我们完成一次文档写入操作,并且此文档分为三个属性(id,content,title)
//批量写入多个文档
ArrayList<Document> list = new ArrayList<Document>();
indexWriter.addDocuments(list);注: IndexWriterConfig 中可以配置索引库创建模式
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
/**
* APPEND: 表示追加, 如果索引库存在, 就会向索引库中追加数据, 如果索引库不存在, 直接报错
*
* CREATE: 表示创建, 不管索引库有没有, 每一次都是重新创建一个新的索引库
*
* CREATE_OR_APPEND (默认值): 如果索引库有, 就会追加, 如果没有 就会创建索引库
*/
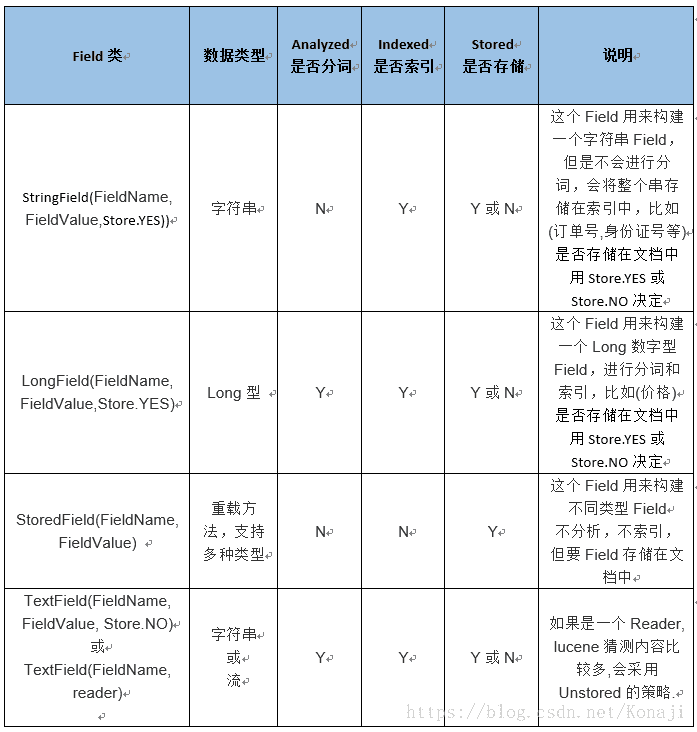
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);Lucene中常用的一些字段说明
查询
public static void serch() throws IOException, ParseException {
//创建索引查询对象
DirectoryReader indexReader =
DirectoryReader.open(FSDirectory.open(new File("D:\\open")));
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//此处使用的分词器一样要和写入索引使用的分词器保持一致
Analyzer analyzer = new StandardAnalyzer();
//查询解析器
QueryParser parser = new QueryParser("content", analyzer);
Query query = parser.parse("中国");
//查询
TopDocs topDocs = indexSearcher.search(query, Integer.MAX_VALUE);
//返回当前文档集合
ScoreDoc[] docs = topDocs.scoreDocs;
//返回的总数量
int totalHits = topDocs.totalHits;
for (ScoreDoc doc : docs) {
// 此处的id值是lucene自己维护的id值
int docId = doc.doc;
//当前这个文档的命中率
float score = doc.score;
//根据给定的id 查询对应的文档内容
Document document = indexSearcher.doc(docId);
String id = document.get("id");
String content = document.get("content");
String title = document.get("title");
System.out.println("索引ID:" + docId + ",命中率:" + score);
System.out.println("id:" + id + ",content:" + content + ",title:" + title);
}
}多字段查询
MultiFieldQueryParser parser = new MultiFieldQueryParser(new String[]{"id","content"},
new StandardAnalyzer());
Query parse = parser.parse("中国");引入IK分词器
IK分词插件在中文检索中非常常用。
<!-- 引入IK分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>引入配置文件
- ext.dic (扩展词典)
- stopword.dic (停用词典)
- IKAnalyzer.cfg.xml
1) 扩展词典(新创建词功能):有些词IK分词器不识别,可以为新词也创建索引 例如:“给力”
2) 停用词典(停用某些词功能)有些词不需要建立索引 例如:“哦”,“啊”,“的”
ext.dic

给力stopword.dic
哦
的
呀
啊
了IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>切换分词器
IndexWriterConfig indexWriterConfig =
new IndexWriterConfig(Version.LATEST, new IKAnalyzer());常用的五种查询
//首先抽出来一个查询方法
public static void IKAbstractSerch ( Query query ) throws IOException {
FSDirectory directory = FSDirectory.open(new File("D:\\open"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs topDocs = searcher.search(query, Integer.MAX_VALUE);
int totalHits = topDocs.totalHits;
ScoreDoc[] docs = topDocs.scoreDocs;
System.out.println("查询到的总记录数:" + totalHits);
for (ScoreDoc doc : docs) {
int docId = doc.doc;
float score = doc.score;
Document document = searcher.doc(docId);
String id = document.get("id");
String content = document.get("content");
String title = document.get("title");
System.out.println("索引ID:" + docId + ",命中率:" + score);
System.out.println("id:" + id + ",content:" + content + ",title:" + title);
}
}词条查询
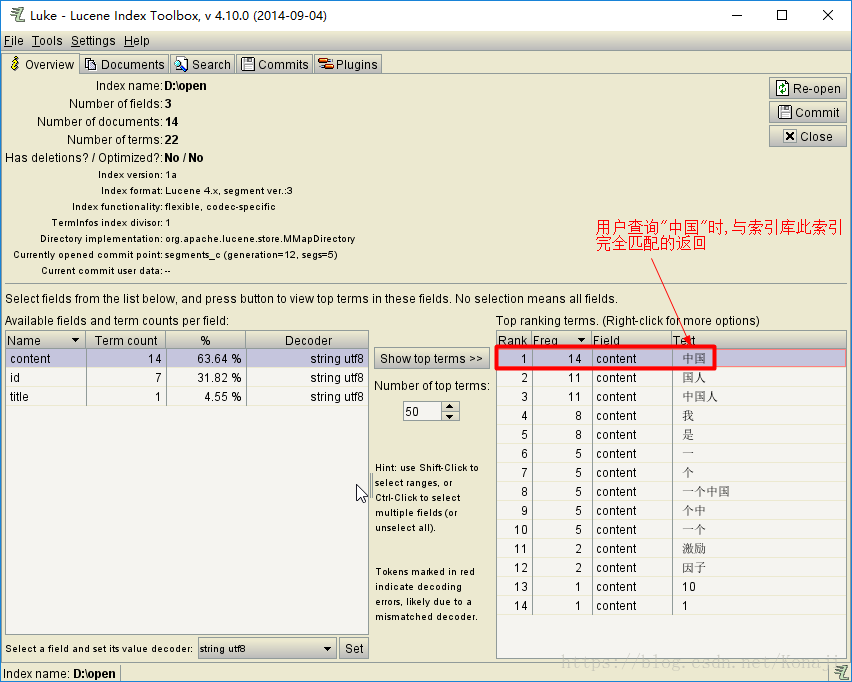
查询的是一个不可再分的内容,可以是一个字、一个词、一句话,将用户输入的字符与索引库中的词条进行100%匹配,将完全匹配到的返回,属于精确查询
public void termTest () throws IOException {
TermQuery query = new TermQuery(new Term("content","中国"));
IKAbstractSerch(query);
}
通配符查询
public void wildTest () throws IOException {
/**
* ? : 占位符,表示占用一个字符
* * :占位符,表示占用0到多个字符
*/
WildcardQuery query = new WildcardQuery(new Term("content","*中国*"));
IKAbstractSerch(query);
}
例如 : 索引库中有这样一个索引 : 我是中国人
以下都能查到此索引:
*是中国*
我是中国?
* (实质查询所有)
注 : 以下是查不到的情况
我是中国人? -> 因为?是一个占位符,索引中必须真实存在才能返回模糊查询
模糊查询指用户输入的数据进行替换、补位、移动时最大支持两次操作
public void fuzzTest () throws IOException {
FuzzyQuery query = new FuzzyQuery(new Term("content","国中人"));
IKAbstractSerch(query);
}修改默认两次的设置 : 数值只能为 0-2 之间,超出会异常
public void fuzzTest () throws IOException {
FuzzyQuery query = new FuzzyQuery(new Term("content","国中人"),1);
IKAbstractSerch(query);
}数值范围查询
查询最小值与最大值之间的数,通过true与false来控制包含关系,true表示包含
public void numeric () throws IOException {
//查询id为1-4之间的数,包含1与4
NumericRangeQuery query = NumericRangeQuery.newLongRange("id",1l,4l,true,true);
IKAbstractSerch(query);
}组合查询
本身没有任何查询条件,需要联合其他查询
public void booleanQuery () throws IOException {
BooleanQuery query = new BooleanQuery();
WildcardQuery wildcardQuery = new WildcardQuery(new Term("content","*"));
NumericRangeQuery numericRangeQuery =
NumericRangeQuery.newLongRange("id",1l,4l,false,false);
query.add(wildcardQuery,BooleanClause.Occur.MUST_NOT);
query.add(numericRangeQuery, BooleanClause.Occur.MUST);
IKAbstractSerch(query);
}组合查询中的条件说明
MUST : 此条件必须包含
MUST_NOT : 不能含有此条件里的内容
SHOULD : 指可选的,有就包含进去,取并集Lucene的高亮效果
将匹配到的文本设置HTML高亮
//具体分两步
//1 高亮设置
SimpleHTMLFormatter simpleHTMLFormatter =
new SimpleHTMLFormatter("<font color='red'>","</font>");
QueryScorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(simpleHTMLFormatter,scorer);
//2 替换文本
content = highlighter.getBestFragment(new IKAnalyzer(), "content", content);完整代码
@Test
public void highTest () throws Exception {
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File("D:\\open")));
IndexSearcher searcher = new IndexSearcher(reader);
Query query = new FuzzyQuery(new Term("content","国中"));
//高亮设置
SimpleHTMLFormatter simpleHTMLFormatter =
new SimpleHTMLFormatter("<font color='red'>","</font>");
QueryScorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(simpleHTMLFormatter,scorer);
Sort sort = new Sort(new SortField("id",SortField.Type.LONG,true));
TopDocs search = searcher.search(query, Integer.MAX_VALUE,sort);
ScoreDoc[] docs = search.scoreDocs;
for (ScoreDoc doc : docs) {
int docId = doc.doc;
Document document = searcher.doc(docId);
String content = document.get("content");
//替换文本
content = highlighter.getBestFragment(new IKAnalyzer(), "content", content);
}
}Lucene排序
//参数3: 是否需要进行反转, 默认是false, 表示不反转,从小到大排序
Sort sort = new Sort(new SortField("id", SortField.Type.LONG,true));
TopDocs topDocs = indexSearcher.search(query, Integer.MAX_VALUE, sort);Lucene分页
Lucene是不支持分页的,所以我们可以根据自己写的算法,来实现物理分页
public static void IKAbstractSerchPage ( Query query ) throws IOException {
//当前页
int page = 1;
//每页显示条数
int totle = 5;
FSDirectory directory = FSDirectory.open(new File("D:\\open"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
//计算从索引库取多少记录数
TopDocs topDocs = searcher.search(query, page*totle);
int totalHits = topDocs.totalHits;
ScoreDoc[] docs = topDocs.scoreDocs;
//判断是否超过总记录数
int count = 0;
if ( totalHits <= page*totle ) {
count = totalHits;
} else {
count = page*totle;
}
//取出当前页的数据
for (int i = ((page-1)*totle); i< count; i++ ){
ScoreDoc doc = docs[i];
int docId = doc.doc;
float score = doc.score;
Document document = searcher.doc(docId);
String id = document.get("id");
String content = document.get("content");
String title = document.get("title");
System.out.println("索引ID:" + docId + ",命中率:" + score);
System.out.println("id:" + id + ",content:" + content + ",title:" + title);
}
}Lucene激励因子
//写入一个文档
Document document = new Document();
document.add(new LongField("id", 1L, Field.Store.YES));
TextField textField = new TextField("content","后门程序", Field.Store.YES);
//激励因子,默认为1
textField.setBoost(10);
document.add(textField);
document.add(new StringField("title", "欢迎来到中国", Field.Store.NO));
indexWriter.addDocument(document);注意事项
写入与查询操作一定要使用同一个分词解析器Analyzer