ML Lecture 8-1: “Hello world” of deep learning
初探深度学习
TensorFlow和theano比较灵活,可以视为微分器,它们可以做深度学习以外的事情,任何需要计算微分/导数的场景都可以用这两个工具,其算出的微分值可以用于后续的梯度下降。由于灵活性比较大,所以运用难度也更大。
- http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Lecture/Theano%20DNN.ecm.mp4/index.html
- http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Lecture/RNN%20training%20(v6).ecm.mp4/index.html
而Keras是TensorFlow和theano的接口,相对比较好学,具备一定的灵活性,同时也有许多封装好的模块供使用,Keras的一个应用实例见此处。
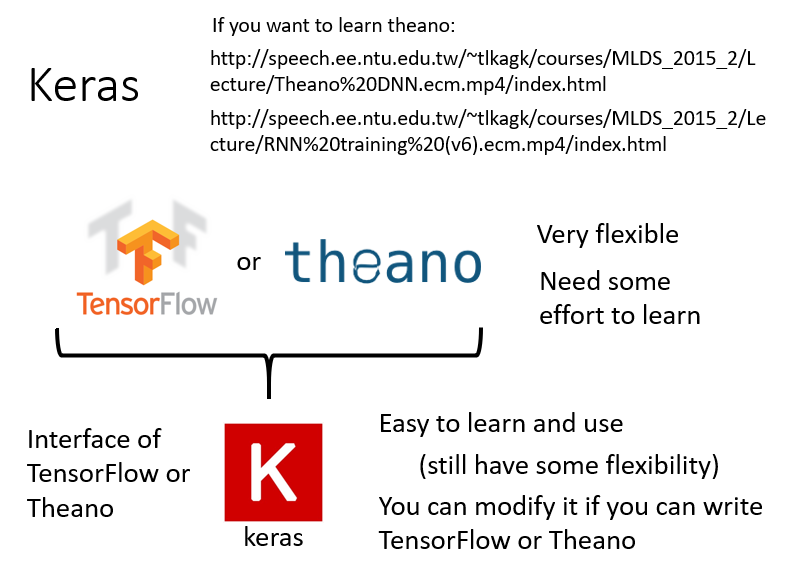

“Hello World”——基于Keras 1.0
仍以Brief Introduction of Deep Learning中的识别手写数字为例,使用的数据集为MNIST。在这个任务中,输入是一个能够代表一张图片的向量,输出是图片中的数字分别属于
个数字的概率。输入向量的大小是一个
的矩阵,Keras提供了函数可以自动下载MNIST数据。

1. 定义模型/函数集
第一步是决定模型长什么样子,设计神经网络的内部结构。
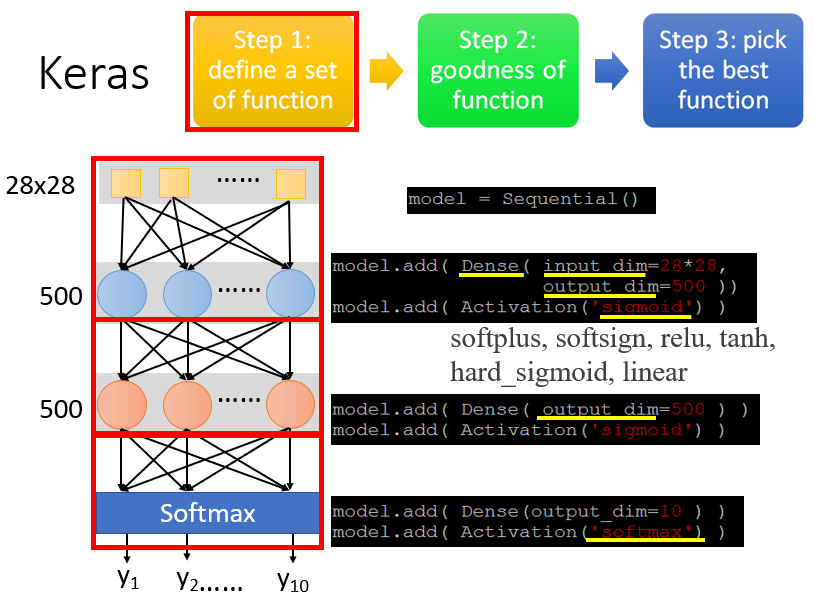
# 声明一个神经网络模型
model = Sequential()
# 设计第一层神经网络结构:Dense表示完全连接的神经网络;input_dim表示输入一个28*28的向量,这个向量代表一张图片;output_dim表示当前隐藏层有500个神经元
model.add(Dense(input_dim = 28*28, output_dim = 500))
# 声明激活函数为Sigmoid
model.add(Activation('sigmoid'))
# 设计第二层神经网络结构:这里不需要再声明input_dim,因为上一层的输出就决定了输入本层的向量维数;只需要定义本层的神经元个数:output_dim设为500维
model.add(Dense(output_dim = 500))
# 声明激活函数为Sigmoid
model.add(Activation('sigmoid'))
# 定义最后一层做数字分类:有10个数字,output_dim设为10维
model.add(Dense(output_dim = 10))
# 声明激活函数为Softmax
model.add(Activation('softmax'))激活函数的可选参数(Usage of activations):softmax、elu、selu、softplus、softsign、relu、tanh、sigmoid、hard_sigmoid、linear
2. 判断函数的优劣(定义损失函数)
第二步是评价一个函数的好坏,定义损失函数。
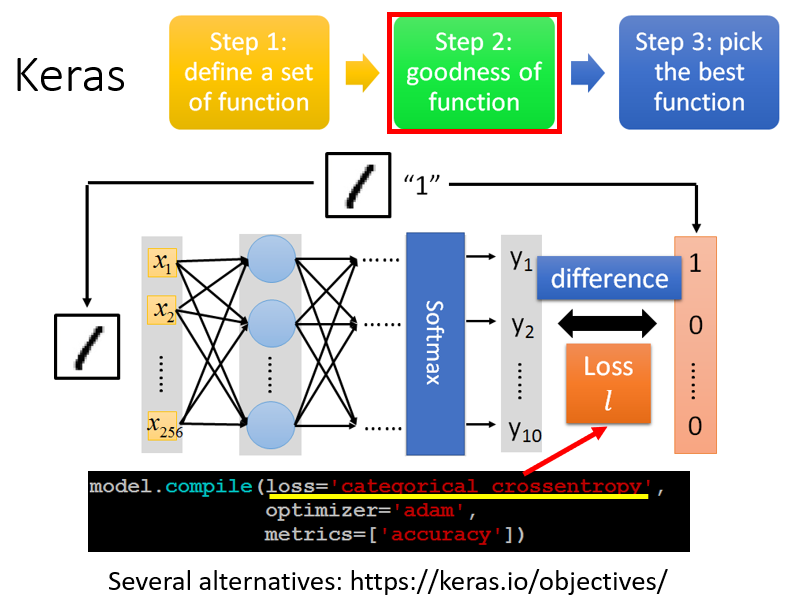
# 定义损失函数为交叉熵categorical_crossentropy
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = 'accuracy')损失函数的可选参数(Usage of loss functions):mean_squared_error、mean_absolute_error、mean_absolute_percentage_error、mean_squared_logarithmic_error、squared_hinge、hinge、categorical_hinge、logcosh、categorical_crossentropy、sparse_categorical_crossentropy、binary_crossentropy、kullback_leibler_divergence、poisson、cosine_proximity
3. 选择最佳函数/参数(训练过程)
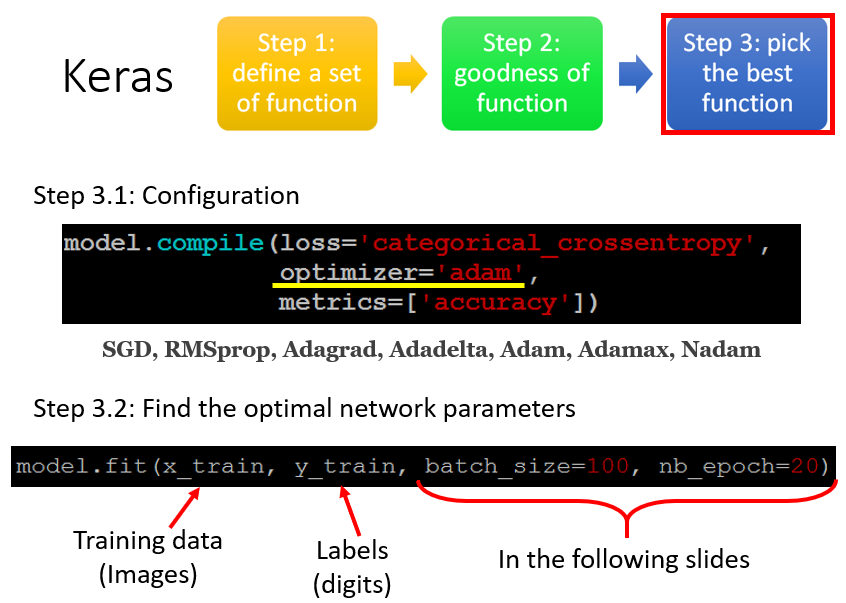
# 开始训练前,进行一些训练模型的基本配置:optimizer指定用何种方式寻找最佳函数(虽然有不同的optimizer参数可选,但它们都是基于梯度下降的,只是学习率有所不同)
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = 'accuracy')
# x_train代表训练样本(这里代表输入一张图片向量);y_train代表样本的真实label(这里代表一张图片里对应的真实数字是0-9中的哪一个,独热编码形式)
model.fit(x_train, y_train, batch_size = 100, nb_epoch = 20)优化学习率的可选参数(Usage of optimizers):SGD、RMSprop、Adagrad、Adadelta、Adam、Adamax、Nadam、TFOptimizer
衡量指标的可选参数(Usage of metrics):binary_accuracy、categorical_accuracy、sparse_categorical_accuracy、top_k_categorical_accuracy、sparse_top_k_categorical_accuracy、Custom metrics
x_train、y_train的输入形式:
x_train是一个储存了所有图片的numpy array,它是 维的矩阵。第一维的长度是样本个数(如果有一万张图片,第一维的长度就是一万);第二维的长度取决于图片的大小,看有多少个pixel,例如图片是 个pixel,则第二维的长度为 。y_train是储存了所有图片的真实label的numpy array,它也是 维的矩阵,第一维的长度是样本个数(如果有一万张图片,第一维的长度就是一万);第二维的长度取决于输出类别的个数,即 个类别。
例如,第一张图的真实lable是
,则在y_train这个numpy array中,第一列所代表的label将从上往下数第
格涂黑(代表数字
),其他格子留白。数字
的真实label分别表示如下图右。
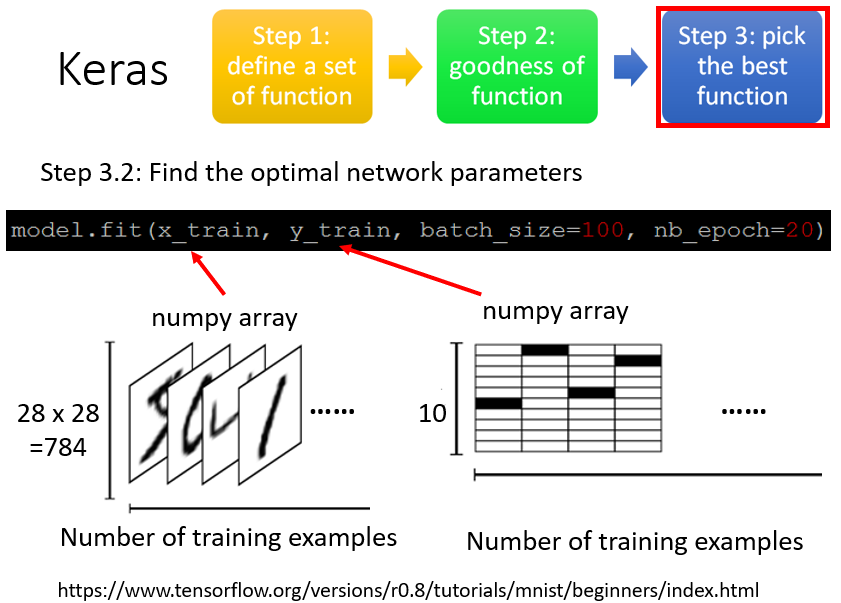
batch_size、nb_epoch的含义:
使用梯度下降法时,我们并没有真的使Total Loss最小化。而是把训练数据随机(如果不随机地选择,对模型性能影响很大)分成不同的batch,令各个不同batch的损失值最小。例如,有一万张训练图片,每次随机选择
张图片出来,作为一个batch,并使这
张图片的损失函数最小化。因此,训练过程可以归纳如下:
- 随机生成神经网络的初始参数
- 按照每个batch定义的样本数,将训练数据随机分成多个batch
- 随机选择一个batch,计算这个batch中的所有样本的损失函数 ,根据 最小化的原则更新参数,即计算 对各个参数的偏导数
- 随机选择第二个batch,计算损失函数为 ,计算 对各个参数的偏导数并更新参数
- 重复上述过程,直到遍历了所有batch
如果有
个batch,则参数就会更新
次。把所有的batch都遍历过,使每个batch的损失函数都最小化以后,就称为一个epoch,训练神经网络就是不断重复以上过程,一般需要好几十个epoch。
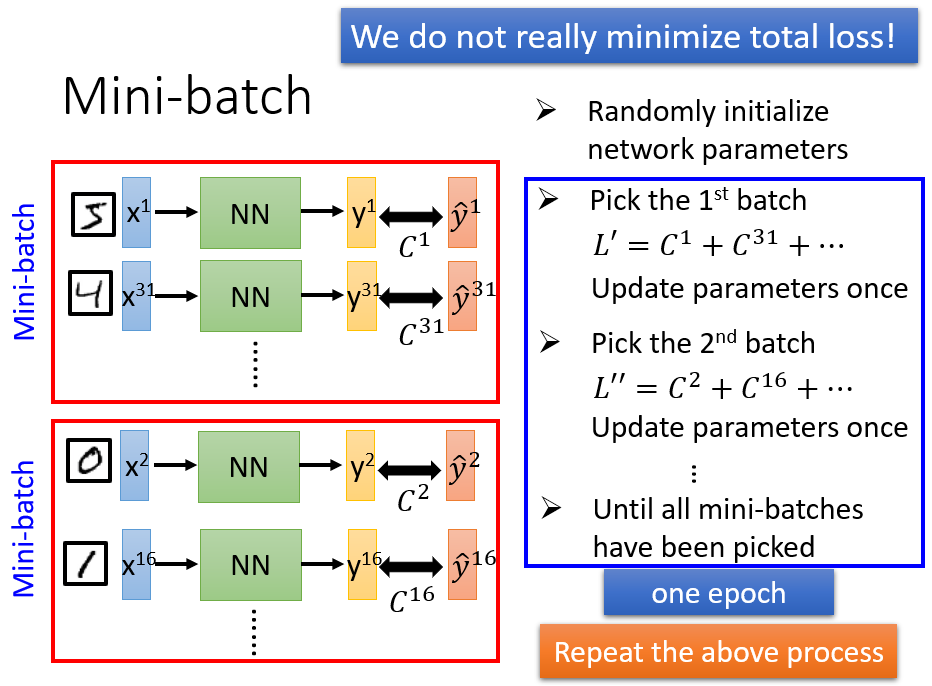
因此,这两个参数的含义如下:
- 参数
batch代表一个batch中包含的样本量,例如设置batch=100,Keras会按照每 个样本为一个batch的原则,随机生成多个batch - 参数
nb_epoch代表所有batch遍历完一轮后(即完成一个epoch),继续重复上述过程(进行第二、三个epoch…),一共要重复多少轮。例如nb_epoch=20意味着所有batch会被遍历 次。
【注】:设置nb_epoch=20并不是代表一共更新了 次参数。一个epoch会多次更新参数:每看一个batch,就更新一次参数。若有 个batch,则一个epoch更新 次参数, 个epoch就更新 次参数。
特别地,当batch=1时,等同于随机梯度下降。随机梯度下降的好处在于,相较于原来的梯度下降,速度更快。假设有 个训练样本,原来的梯度下降计算出这 个样本的总损失函数,并更新一次参数;而随机梯度下降已经针对这 个样本更新了 次参数(虽然每次更新参数的方向是不稳定的,但是速度更快)。
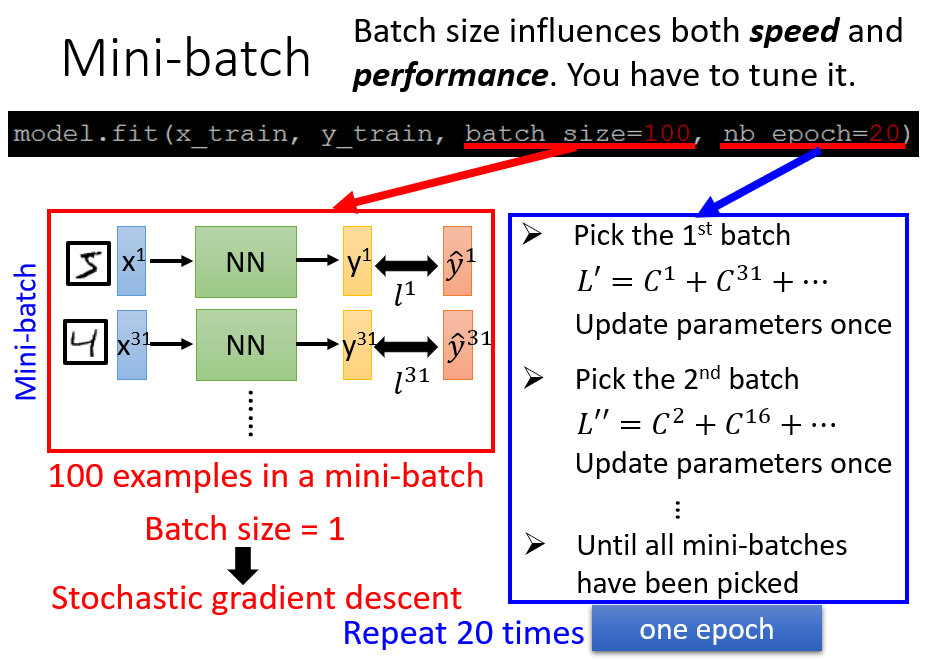
尽管随机梯度下降的更新速度有优势,但碍于实操问题,我们并不能完全采用batch=1的随机梯度下降方法,而必须设置mini-batch。假设对于
个训练样本,分别做如下设置:
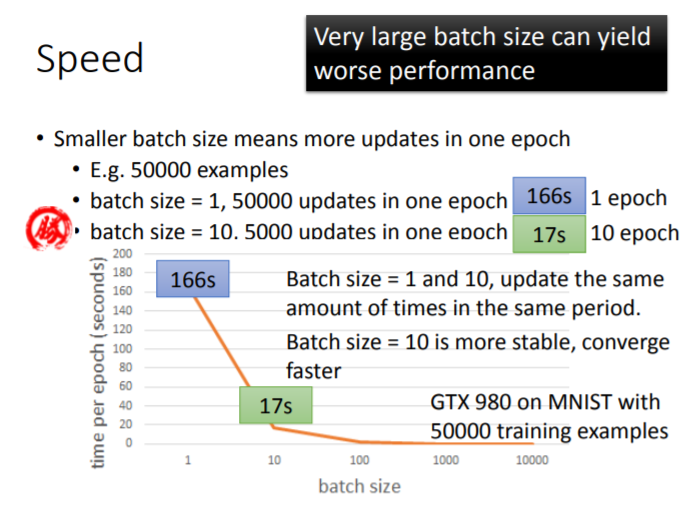
batch=1,则一个epoch中更新 次参数(随机梯度下降)batch=10,则一个epoch中更新 次参数(mini-batch)
表面上看,无论设置batch=1或10,同样都是针对
个样本,一个epoch的计算量应该相同,随机梯度下降更新参数的速度(
次)似乎是mini-batch速度(
次)的十倍。实际上,当设置不同的batch size,一个epoch需要的时间是不同的。
用GTX 980在MNIST数据集的
个样本上测试速度,当设置不同的batch size时,跑一个epoch所需要的时间如下图:
- 前者需 (完成 个epoch,参数更新 次),后者需 (完成 个epoch,参数更新 次, 个epoch参数更新 次,约需要 s)。二者由于耗时的差异,参数更新速度相差无几
- 在二者的参数更新次数差异不大的情况下,选择batch=10更为稳定
选择随机梯度下降是由于其速度更快,但当其速度优势不明显时,就应该选择稳定性更好的mini-batch
【batch size较大的优势】
- 设置较大的batch size能使耗时更短,是因为利用了并行运算。当batch=10,在GPU上并行运算时,这 个样本是同时计算的。由于是同时计算,所以一个batch中包含 个样本的运算时间,与一个batch中包含 个样本的运算时间,几乎是一样的。
【batch size太大的缺陷】
- 虽然较大的batch size训练起来更稳定,还可实现并行运算使训练速度变快,但batch size不能无限增大,因为GPU可以实现的并行运算量是有限的:同时计算 个样本的时间和计算 个样本的时间是相差无几的,batch=10比batch=1更有优势;一旦需要同时计算 个样本,GPU的运算时间也会相应增加,batch=10000不一定比batch=1更有优势。因此,考虑到硬件限制,batch size是无法无穷尽增长的。
- 此外,若设置太大的batch size,在做梯度下降训练时,跑两下神经网络就会卡住(陷入鞍点、局部最小值等地方)。因为神经网络模型的参数优化并非单纯的
凸优化问题(Convex Optimization Problem),在误差曲面(Error Surface)上存在许多坑坑洼洼的局部最小值。
假如设置了full batch(即没有设置mini-batch),这种情况是完全顺着Total Loss的梯度方向走,哪怕GPU可以跑得动,训练过程也特别容易卡顿,没两步就停下来,训练效果也不理想。
此时随机梯度下降的优势就显现出来了:由于具有随机性,每一次根据新样本计算出的梯度向量的方向都是随机的。训练过程中如果陷入局部最小值,只要这个局部最小值的坑不是特别深,随机梯度下降方法是可以跳出这个梯度为 的坑,继续更新参数的。
可见,神经网络的训练需要带上一定的随机性更为合理。而mini-batch的存在提供了这种随机性,同时又避免随机梯度下降在样本量大的情况下训练时间过长。
存在mini-batch情况下的GPU并行运算
不论是前向传播,还是反向传播,整个神经网络可以视为一连串矩阵运算的结果。
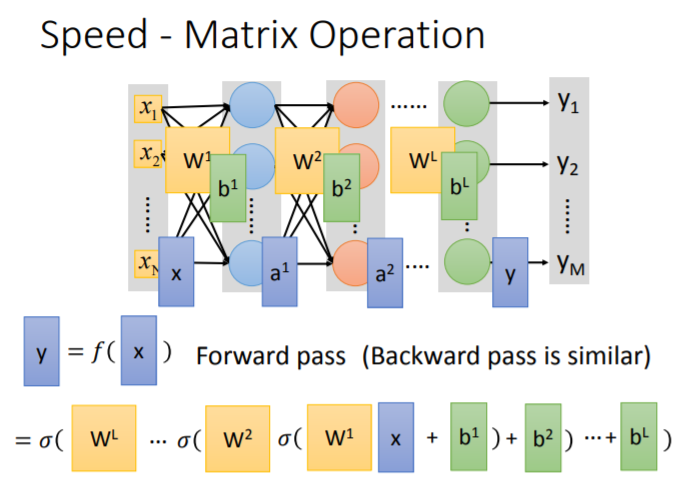
在使用GPU的条件下,随机梯度下降和mini-batch更新参数的方式如下图:
- 随机梯度下降每更新一次参数,是基于单一样本的:看过黄色样本后更新一次参数;继续看绿色样本再更新一次参数,
这里进行了两步,基于2个样本更新了2次参数 - mini-batch每更新一次参数,是基于一个batch的样本量的:假设batch=2,将一个batch中的样本向量(黄色、绿色样本向量)拼成一个矩阵,同时乘以权重矩阵
做并行运算,然后更新一次参数。相当于
把随机梯度的两步合并为一步同时进行,基于2个样本更新了1次参数
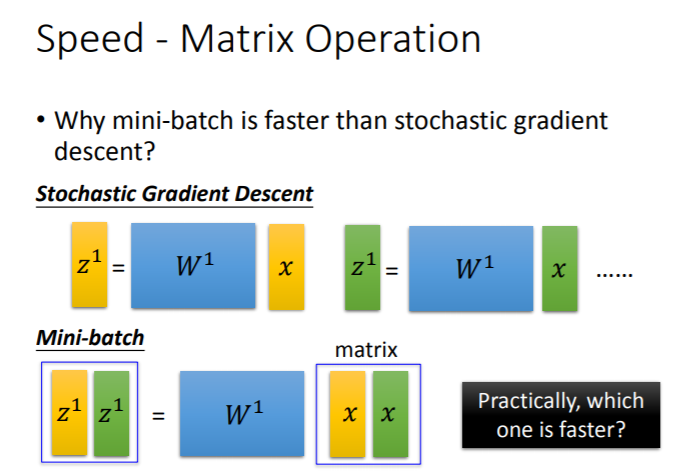
理论上,同样是基于黄、绿
个样本更新参数,这两种方法的运算量应该是一样的,但在实操中,mini-batch的运算速度是更快的。对GPU来说,做矩阵运算时,矩阵中的每一个元素都可以平行运算,同时计算
个样本向量和计算
个样本向量所用的时间是相同的。随机梯度下降的运行时间(分别做两次矩阵运算),是mini-batch运行时间(并行一次矩阵运算)的两倍。
因此,利用GPU以mini-batch的方式训练神经网络可以实现加速。如果仅使用GPU,而没有采用mini-batch,其实并没有实现加速,GPU的优势没有体现。
4. 保存、加载、测试神经网络模型
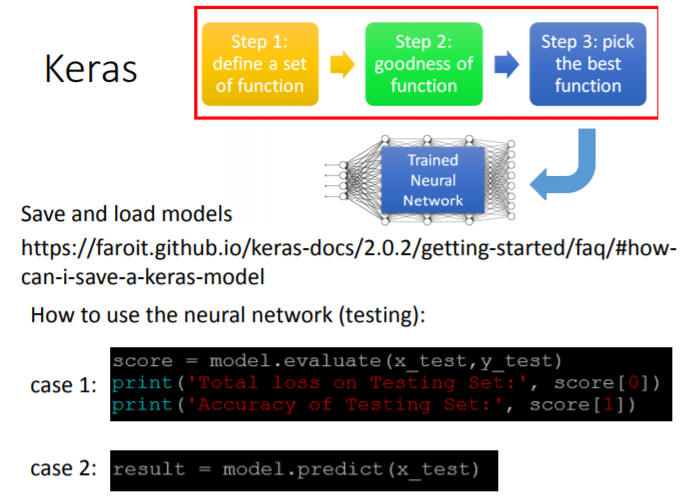
# Evaluation(测试集+测试集label)
# 训练好的模型在测试集(x_test)上做验证,测试集的真实label(y_test)也已知
# model.evaluate的结果输出一个二维向量,记为score
# 第一维score[0]代表模型在测试集上的损失值,第二维score[1]是模型在测试集上的正确率
score = model.evaluate(x_test, y_test)
print('Total loss on Testing Set:', score[0])
print('Accuracy of Testing Set:', score[1])
# Predict(测试集)
# 训练好的模型在测试集(x_test)上做验证,测试集的真实label未知,模型有待投入使用
result = model.predict(x_test)
ML Lecture 8-2: Keras 2.0
代码更新——基于Keras 2.0构建完全连接前馈式神经网络
1. 定义模型/函数集
# 声明一个神经网络模型
model = Sequential()
# 设计第一层神经网络结构:Dense表示完全连接的神经网络
# input_dim表示输入一个28*28的向量,这个向量代表一张图片
# units表示当前隐藏层有500个神经元
# 声明激活函数为relu
model.add(Dense(input_dim = 28*28, units = 500, activation = 'relu'))
# 设计第二层神经网络结构:这里不需要再声明input_dim,因为上一层的输出就决定了输入本层的向量维数
# 只需要定义本层的神经元个数:units设为500维,代表本层有500个神经元
# 声明激活函数为relu
model.add(Dense(units = 500, activation = 'relu'))
# 定义最后一层做数字分类:有10个数字,units设为10维
# 声明激活函数为Softmax,则输出向量的每一维都是0-1之间的值(视为分类概率),所有维度总和为1
model.add(Dense(units = 10, activation = 'softmax'))激活函数的可选参数(Usage of activations):softmax、elu、selu、softplus、softsign、relu、tanh、sigmoid、hard_sigmoid、linear
2. 判断函数的优劣(定义损失函数)
# 定义损失函数为交叉熵categorical_crossentropy
# optimizer指定用何种方式寻找最佳函数(虽然有不同的optimizer参数可选,但它们都是基于梯度下降的,只是学习率有所不同)
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])损失函数的可选参数(Usage of loss functions):mean_squared_error、mean_absolute_error、mean_absolute_percentage_error、mean_squared_logarithmic_error、squared_hinge、hinge、categorical_hinge、logcosh、categorical_crossentropy、sparse_categorical_crossentropy、binary_crossentropy、kullback_leibler_divergence、poisson、cosine_proximity
优化学习率的可选参数(Usage of optimizers):SGD、RMSprop、Adagrad、Adadelta、Adam、Adamax、Nadam、TFOptimizer
衡量指标的可选参数(Usage of metrics):binary_accuracy、categorical_accuracy、sparse_categorical_accuracy、top_k_categorical_accuracy、sparse_top_k_categorical_accuracy、Custom metrics
3. 选择最佳函数/参数(训练过程)
# model.fit函数利用梯度下降训练模型
# x_train代表训练样本(这里代表输入一张图片向量);y_train代表样本的真实label(这里代表一张图片里对应的真实数字是0-9中的哪一个,独热编码形式)
# x_train、y_train都以numpy array的形式储存,是二维的矩阵
model.fit(x_train, y_train, batch_size = 100, epochs = 20)4. 保存、加载、测试神经网络模型
# Evaluation(测试集+测试集label)
# 训练好的模型在测试集(x_test)上做验证,测试集的真实label(y_test)也已知
# model.evaluate的结果输出一个二维向量,记为score
# 第一维score[0]代表模型在测试集上的损失值,第二维score[1]是模型在测试集上的正确率
score = model.evaluate(x_test, y_test)
print('Total loss on Testing Set:', score[0])
print('Accuracy of Testing Set:', score[1])
# Predict(测试集)
# 训练好的模型在测试集(x_test)上做验证,测试集的真实label未知,模型有待投入使用
result = model.predict(x_test)ML Lecture 8-3: Keras Demo
Keras Demo
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.optimizers import SGD, Adam
from keras.utils import np_utils
from keras.datasets import mnist
def load_data():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
number = 10000
x_train = x_train[0:number]
y_train = y_train[0:number]
x_train = x_train.reshape(number, 28*28)
x_test = x_test.reshape(x_test.shape[0], 28*28)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Convert class vectors to binary class matrices
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
x_train = x_train
x_test = x_test
# x_test=np.random.normal(x_test)
x_train = x_train / 255
x_test = x_test / 255
return (x_train, y_train), (x_test, y_test)
(x_train, y_train), (x_test, y_test) = load_data()
# x_train是一个二维向量(10000, 784)
# 表示x_train包含10000个样本,每个样本向量的维度为784
x_train.shape # (10000, 784)
x_train[0] # 第一张图片是一个784维的向量,其中多个元素为0。部分元素介于0-1之间,代表该像素格是否被涂黑,完全涂黑时对应值为1
type(x_train) # numpy.ndarray
# y_train是一个二维向量(10000, 10)
# 表示y_train包含10000个样本,每个样本真实label的维度为10
y_train.shape # (10000, 10)
y_train[0] # 第一张图片对应的真实label是5:array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)
type(y_train) # numpy.ndarray
model = Sequential()
model.add(Dense(input_dim = 28*28, units = 655, activation = 'sigmoid'))
model.add(Dense(units = 655, activation = 'sigmoid'))
model.add(Dense(units = 655, activation = 'sigmoid'))
model.add(Dense(units = 10, activation = 'softmax'))
model.compile(loss = 'mse', optimizer = SGD(lr = 0.1), metrics = ['accuracy'])
model.fit(x_train, y_train, batch_size = 100, epochs = 50)
result = model.evaluate(x_test, y_test)
print('\nTest Acc:', result[0])示例代码只是演示了模型构建的基本步骤,其正确率是非常低的,后续会涉及一些调参的trick。
其他资料:
How can I save a Keras model?
Get Started with TensorFlow
Classify movie reviews: binary classification