摘要:自然语言理解是人工智能的核心难题之一,也是目前智能语音交互和人机对话的核心难题。之前写过一篇文章自然语言理解,介绍了当时NLU的系统方案,感兴趣的可以再翻一番,里面介绍过的一些内容不再赘述。本文详细讨论了自然语言理解的难点,并进一步针对自然语言理解的两个核心问题,详细介绍了规则方法和深度学习的应用。
1. 引言
自然语言理解是人工智能的核心难题之一,也是目前智能语音交互和人机对话的核心难题。维基百科有如下描述[1]:
Natural language understanding (NLU) is a subtopic of natural language processing in artificial intelligence that deals with machine reading comprehension. NLU is considered an AI-hard problem.
对于AI-hard的解释如下:
In the field of artificial intelligence, the most difficult problems are informally known as AI-complete or AI-hard, implying that the difficulty of these computational problems is equivalent to that of solving the central artificial intelligence problem—making computers as intelligent as people, or strong AI.
简言之,什么时候自然语言能被机器很好的理解了,strong AI也就实现了~~
之前写过一篇文章自然语言理解,介绍了当时NLU的系统实现方案,感兴趣的可以再翻一番,里面介绍过的一些内容不再赘述。那篇文章写于2015年底,过去一年多,技术进展非常快,我们的算法也进行了大量升级,核心模块全部升级到深度学习方案。本文主要结合NUI平台中自然语言理解的具体实现,详细的、系统的介绍意图分类和属性抽取两个核心算法。如下图所示,第一个框中是意图分类,第二个框中是属性抽取。

对于整个NUI平台的介绍可以参考孙健/千诀写的从“连接”到“交互”—阿里巴巴智能对话交互实践及思考。
2. 自然语言理解的难点
为什么自然语言理解很难?本质原因是语言本身的复杂性。自然语言尤其是智能语音交互中的自然语言,有如下的5个难点:
一. 语言的多样性
一方面,自然语言不完全是有规律的,有一定规律,也有很多例外;另一方面,自然语言是可以组合的,字到词,词到短语,短语到从句、句子,句子到篇章,这种组合性使得语言可以表达复杂的意思。以上两方面共同导致了语言的多样性,即同一个意思可以有多种不同的表达方式,比如:
1. 我要听大王叫我来巡山
2. 给我播大王叫我来巡山
3. 我想听歌大王叫我来巡山
4. 放首大王叫我来巡山
5. 给唱一首大王叫我来巡山
6. 放音乐大王叫我来巡山
7. 放首歌大王叫我来巡山
8. 给大爷来首大王叫我来巡山
二. 语言的歧义性
在缺少语境约束的情况下,语言有很大的歧义性,比如:
1. 我要去拉萨
(1)火车票?
(2)飞机票?
(3)音乐?
(4)还是查找景点?
三. 语言的鲁棒性
语言在输入的过程中,尤其是通过语音识别转录过来的文本,会存在多字、少字、错字、噪音等等问题,比如:
1. 错字
(1)大王叫我来新山
2. 多字
(2)大王叫让我来巡山
3. 少字
(3)大王叫我巡山
4. 别称
(4)熊大熊二(指熊出没)
5. 不连贯
(5)我要看那个恩花千骨
6. 噪音
(6)全家只有大王叫我去巡山咯
四. 语言的知识依赖
语言是对世界的符号化描述,语言天然连接着世界知识,比如:
1. 大鸭梨
(1)除了表示水果,还可以表示餐厅名
2. 七天
(2)除了表示时间,还可以表示酒店名
3. 总参
(3)除了表示总参谋部,还可以表示餐厅名
4. 天气预报
(4)还是一首歌名
5. 晚安
(5)这也是一首歌名
五. 语言的上下文
上下文的概念包括很多内容,比如:
1. 对话上下文
2. 设备上下文
3. 应用上下文
4. 用户画像
5. ...
U:买张火车票
A:请问你要去哪里?
U:宁夏
这里的宁夏是指地理上的宁夏自治区
U:来首歌听
A:请问你想听什么歌?
U:宁夏
这里的宁夏是指歌曲宁夏
3. 意图分类的实现方法
意图分类是一种文本分类。主要的方法有:
1. 基于规则(rule-based)
(1)CFG
(2)JSGF
(3)……
2. 传统机器学习方法
(1)SVM
(2)ME
(3)……
3. 深度学习方法
(1)CNN
(2)RNN/LSTM
(3)……
3.1 基于规则的方法
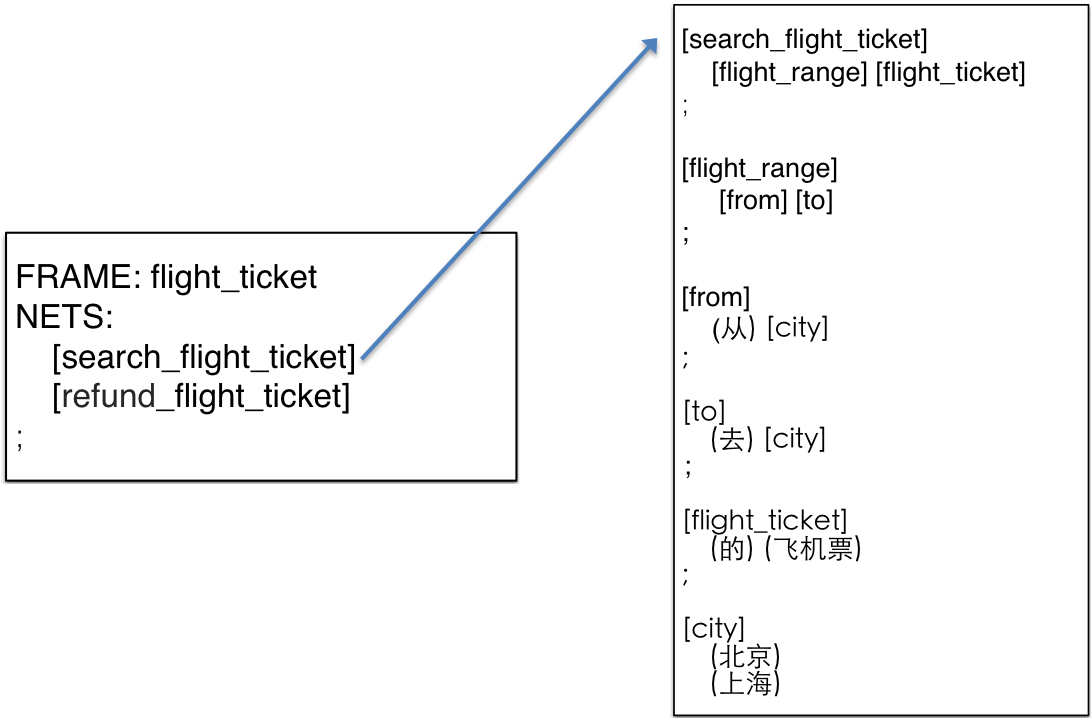
这里重点介绍基于CFG的方法[2],该方法最早出现于CMU Phoenix System中,以下是一个飞机票领域的示例:
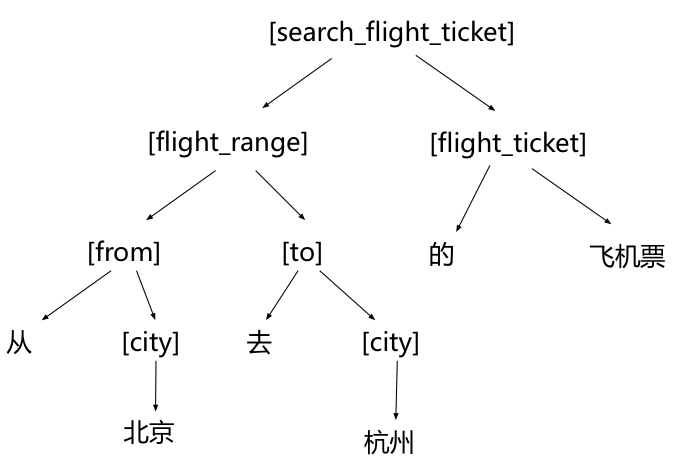
按照上面的文法,对于“从北京去杭州的飞机票”,可以展成如下的树:
3.2 基于传统统计的方法
我们在第一版的系统中,采用的基于SVM的方法,在特征工程上做了很多工作。第二版中切换到深度学习模型后,效果有很大提升,此处略过,直接介绍深度学习方法。
3.3 基于深度学习的方法
深度学习有两种典型的网络结构:
1. CNN(卷积神经网络)
2. RNN(循环神经网络)
基于这两种基本的网络结构,又可以衍生出多种变形。我们实验了以下几种典型的网络结构:
1. CNN [3]
2. LSTM [4]
3. RCNN [5]
4. C-LSTM [6]
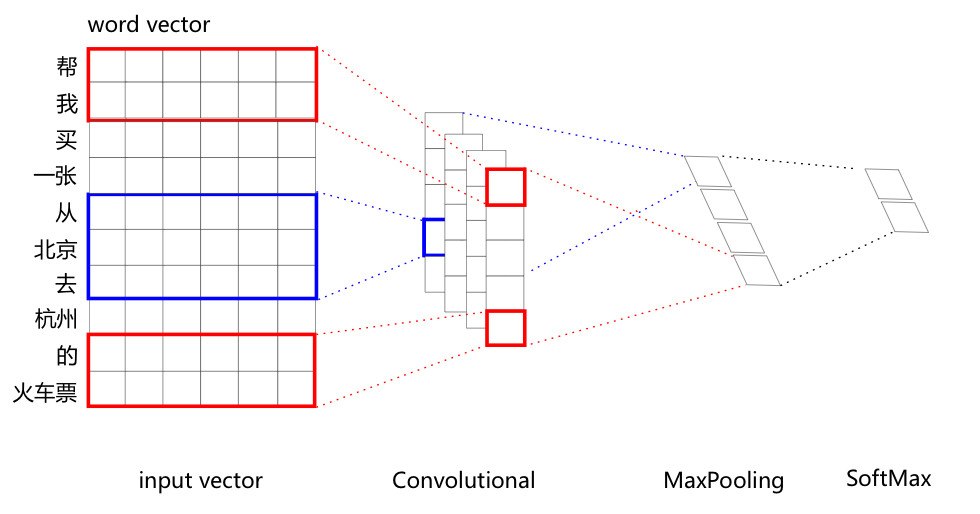
从实验结果来看,简单的CNN的效果最好,其网络结构如下:
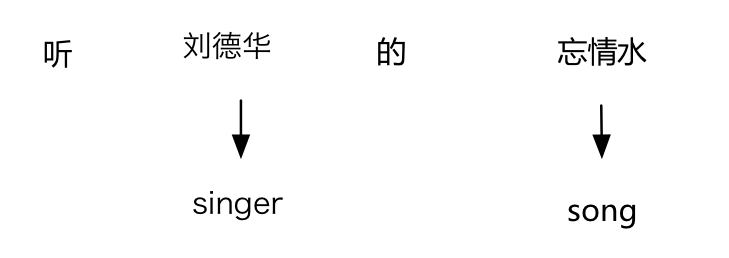
单纯的CNN分类效果无法超越复杂特征工程的SVM分类器,尤其是在像音乐、视频等大量依赖世界知识的领域中。比如怎么把如下的世界知识融入到网络中去:
这背后更大的背景是,深度学习在取得巨大成功后,慢慢开始显露出瓶颈,比如如何表示知识、存储知识,如何推理等。其中一个探索方向就是试图把联结主义和符号主义进行融合。纯粹的基于联结主义的神经网络的输入是distributed representation,把基于符号主义的symbolic representation融合到网络中,可以大大提高效果,比如:

4. 属性抽取的实现方法
属性抽取问题可以抽象为一个序列标注问题,如下例:

1. 基于规则(rule-based)
(1)Lexicon-based
(2)CFG
(3)JSGF
(4)……
2. 传统机器学习方法
(1)HMM
(2)CRF
(3)……
3. 深度学习方法
(1)RNN/LSTM
(2)……
4.1 基于规则的方法
这里主要介绍基于JSGF(JSpeech Grammar Format)的方法:
JSGF is a BNF-style, platform-independent, and vendor-independent textual representation of grammars for use in speech recognition.
其基本的符号及其含义如下:

比如对于如下的示例:

可以展开成图:

对于“帮我打开空调”,其在图中的匹配路径如下:

匹配到这条路径后,可以根据标签,把“空调”抽取到device这个属性槽上。
4.2 基于传统统计的方法
经典算法为CRF,略过。
4.3 基于深度学习的方.
用于序列标注的深度学习模型主要有[7]:
1. RNN
2. LSTM
3. Bi-LSTM
4. Bi-LSTM-Viterbi
5. Bi-LSTM-CRF
也有一些多任务联合训练的模型,比如[8]、[9]。
在我们的系统中,采用的是Bi-LSTM-CRF模型:
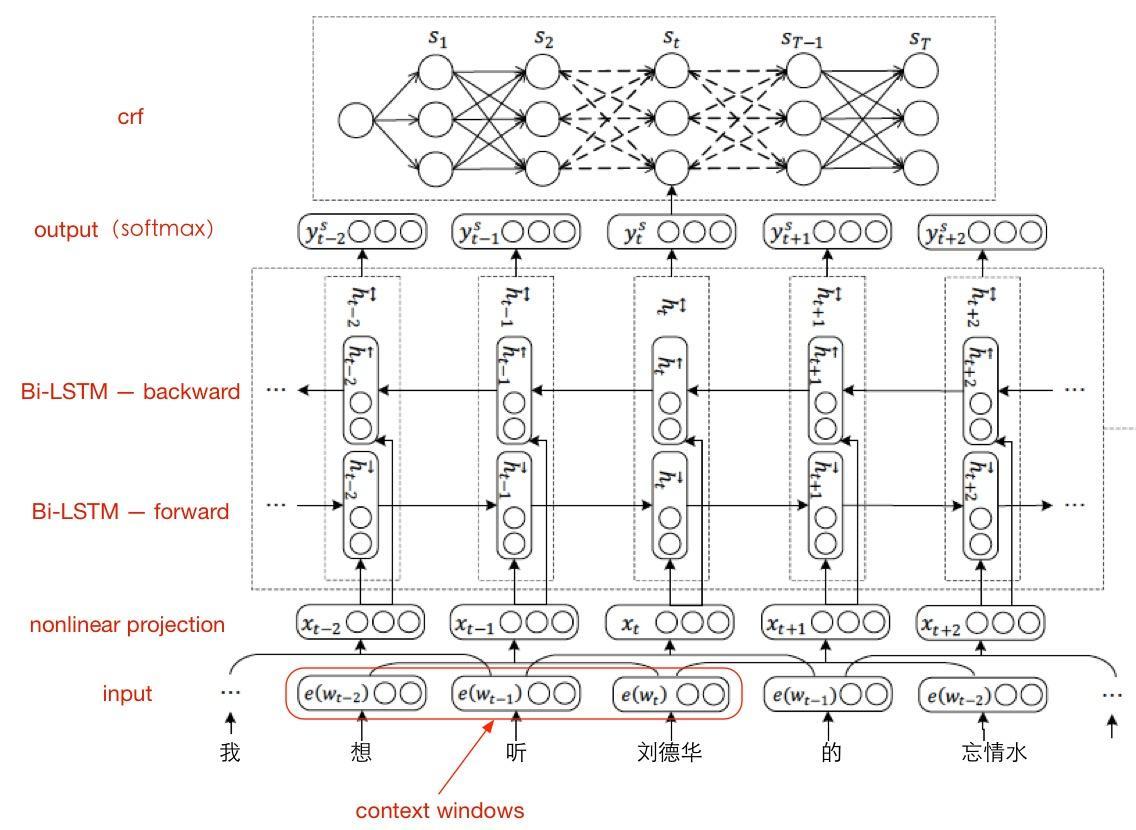
同样的,在input上,将distributed representation和symbolic representation做了融合。
5. 小结
在实际的系统中,基于规则的方法和基于深度学习的方法并存。基于规则的方法主要用来快速解决问题,比如一些需要快速干预的BUG;基于深度学习的方法是系统的核心。